







一.RDD
graph LR
创建--->转换--->操作
1.RDD认知(Spark核心数据集)
RDD: 弹性分布式数据集

2.RDD分类
- 单值: 无key值
- 多个: 有key值
3.RDD操作
- 转换(Transformations):
- 数据加载到RDD
- RDD转换到另一个RDD
- 转换惰性机制: 所有的转换都是,记录了需要操作的步骤,但是没有马上执行。直到savrAsSequenceFile时才触发执行
- 操作(Acyions):
- RDD存储到硬盘
- RDD触发转换执行
4.转换(Transformations)函数
| 常用函数 | 描述 | 返回 |
|---|---|---|
| map(func) | 对RDD所有的元素使用func | 一个新的RDD |
| filter(func) | 对RDD所有的元素使用func | func为true的元素构成的RDD |
| flatMap(func) | 对RDD所有的元素使用func | 多个新的RDD |
| union(otherDatasks) | 返回新的dataset | 源dataset+定dataset |
| groupBy(numTasks) | 返回(K.seq[V]) | 相同的键值对分组 |
| reduccBykey(func.[num.Tasks]) | 用给定的func作用在groupBy上进行操作 | 操作后产生的K.seq[V] |
5.操作(Acyions)函数
| 常用函数 | 描述 |
|---|---|
| reduce(func) | func聚焦所有元素,接收两个参数返回一个值 |
| collect | 返回数据集的所有元素 |
| count() | 返回数据集中所有的个数 |
| first() | 返回数据集中的第一个元素 |
| take(n) | 返回前n个元素 |
| saveAsTextFile(path) | 将数据集元素以texfile形式保存到本地文件系统,hdfs或者其他的分布式文件系统。 Spark调用toString将元素转换为文件中的文本 |
| foreach(func) | 对数据集中的元素都执行func |
6.RDD转换和操作流程
.
7.宽依赖(Wide Dependebcies)
- 子RDD的一个分区都依赖某个父RDD
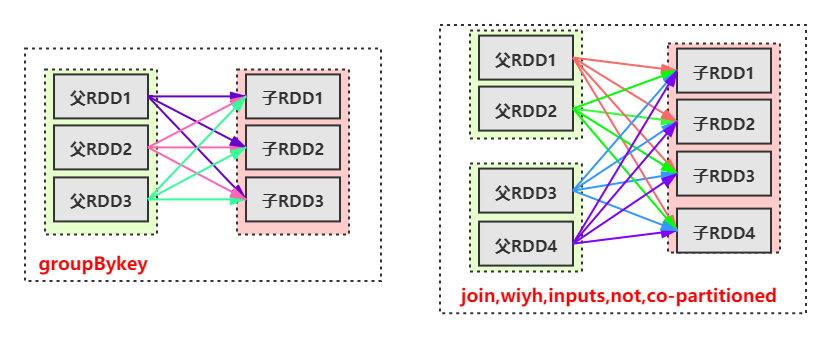
8.窄依赖(Narrow Dependencies)
- 子RDD的一个分区只依赖某个父RDD

9.Stae:阶段
划分
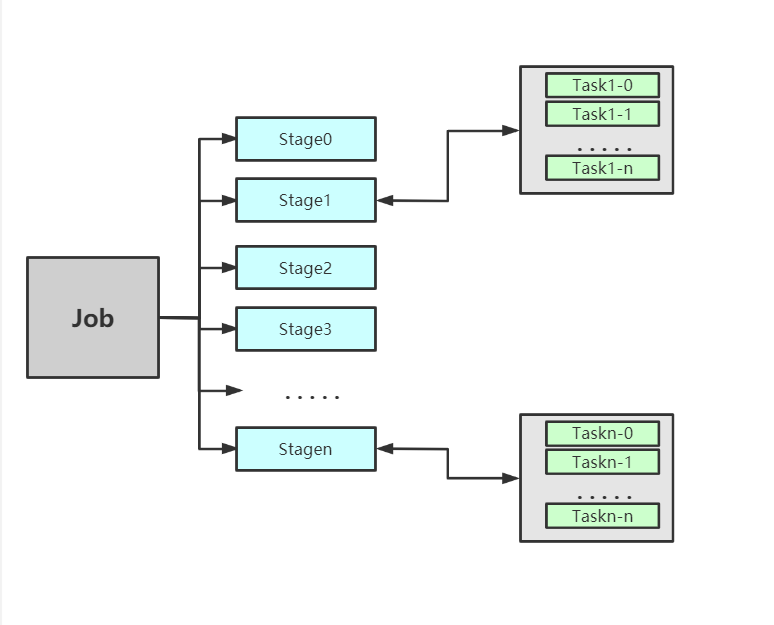
9.1Task
分类
- ShuffleMapTask
- 输出Shuff
- ResultTask
- 输出最终结果
9.2流程图

9.3stge中的RDD

















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











