






最近因为项目需要使用nodejs,因此不得不对其进行学习研究。一番深入后发现,nodejs除了好用,作为后台效率非常高之外,它自身的设计堪称精妙。我们都知道学习的一种有效方式就是看牛逼人物是怎么打造牛逼作品,而nodejs作为极为极为成功的后台系统,要不是有着高超精彩的设计和实现就不会有如此成就,倘若我们能吃透其设计原理和思路,那么我们成不了大师但成为小师,让自己的技术更上一层楼不成问题。
我们这一系列文章不去研究怎么用nodejs实现web后台,这方面的资料已经汗牛充栋,我们研究的是其内核设计思想。学习怎么使用它开发系统后台属于“术”的层次,研究它的设计思想则属于“道”的层次。本节我们先看看它的模块加载功能,也就是require函数的实现原理。
在nodejs开发中我们会使用require将很多功能模块加载到应用中,假设我们需要使用它的文件系统进行本地文件读写,那么我们需要使用如下语句先加载fs模块:
require('fs')
fs.writeFile(p, "hello world")
require是日用而人不知的功能,它就像空气,我们不曾意识到它的存在,但一旦没有了它,那么功能再强大的应用都开发 不了。它的作用非常重要,但人们却极少关注过它的实现原理,我们这里就来深度探讨一下他的实现。
require的实现利用了js中可以使用eval函数直接运行字符串所表示的代码这一功能,它的实现方法路子“颇野”,对于习惯于开发后台应用的技术人员而言,很难想到其设计思路,这里我们就从零实现一下它的功能,我默认nodejs已经在你的系统上安装完毕。首先在本地创建目录require,然后目录下创建my_module.js文件,它实现的是我们要加载的模块:
let local_string = "this is my module"
module.exports.LOCAL_STRING = local_string
exports.log = ()=> {
console.log(local_string)
}
它的内容很简单,就是导出一个变量和函数,引入这个模块的代码可以访问变量LOCAL_STRING和函数log,创建index.js,我们看看如何实现require函数的导入功能,实现代码如下:
let fs = require('fs')
function loadModule(file_name, module, my_require) {
if (file_name.endsWith('.js') !== true) {
file_name = file_name + ".js"
}
//必须要使用阻塞读,不然代码调用模块接口时,接口可能还没有加载进来
const stringSrc = `(function(module, exports, require) {
${fs.readFileSync(file_name, 'utf8')}
})(module, module.exports, my_require)`
eval(stringSrc)
}
function my_require(module_name) {
console.log(`Require call for loading moudle: ${module_name}`)
const id = my_require.resolve(module_name)
if (my_require.cache[id]) { //如果已经加载过则直接从缓存获取
return my_require.cache[id].exports
}
const module = {
exports: {},
id
}
my_require.cache[id] = module //这里缓存很重要,除了加快加载速度外还能处理循环依赖
loadModule(id, module, my_require)
return module.exports
}
my_require.cache = {} //用于缓存已经加载的模块
my_require.resolve = (module_name) => {
/*
为了简单起见,这里直接返回文件名,实际上他要执行如下步骤:
1,如果它以/开头,说明是绝对路径,那么直接返回,
如果是./开头,那么是相对路径,使用当前路径接口modue_name得到全路径后返回
2,如果不以/或者./开头,那么就是Nodejs的核心模块,nodejs将在其核心模块目录下查找
3,如果第2步找不到,那么现在当前目录下查找是否存在node_module目录,如果有则进去查找
,如果没有则回到上一级目录,查找node_module目录,然后进去查找,如果没有node_module目录,则继续
往上一级目录执行,直到根目录为止。
在匹配的时候,首先在给定目录下匹配是否有<module_name>.js文件,
如果没有,那么匹配<module_name>/index.js文件,如果还不匹配,
那么nodejs读取<module_name>/package.json文件,从里面给定的路径进行加载
*/
return module_name
}
const my_module = my_require('./my_module')
my_module.log()
我们将上面代码运行后所得结果如下:
this is my module
也就是它加载了my_module代码,然后调用了其导出的函数log。从代码实现看,require的本质就是将要加载的代码内容先拷贝到当前代码中,只不过用一个函数将代码内容包裹住,然后通过eval函数执行包裹函数,包裹函数传入的参数是module, module.exports,这两个对象恰好就是加载模块用于导出内容的对象,当eval执行后,加载模块要导出的内容就已经存储在module和module.exports中,可以直接使用了。
代码还需要注意的是,require采用了缓存功能,如果给定模块已经加载过了它就直接返回,这意味着无论模块在代码中被加载多少次,它实际上只加载了一次,以后每次遇到要requier它的时候,nodejs都会从缓存中直接将其返回,这样就能加快加载速度,这就类似于singleton模式,即使代码在多个地方加载同一个模块,他们实际上使用的都是同一个对象。
resolve函数中查找模块位置的方式很重要,它能够解决所谓"dependency hell"的问题,因为同一个模块可能有不同版本,同时应用在不同的地方可能需要加载同一个模块的不同版本,因此在依赖模块非常多,版本也不同时就极容易出错,如果代码向加载模块a的1.01版本,但却错误加载成1.02版本,那么出现的错误将非常难以查找。
resolve查找模块路径的方式就能解决这个问题。因为它会先从加载代码所在路径的node_module目录开始查找,假设我们应用有如下目录:
myAPP
|--- foo.js
|---node_modules
|----depA
| |----index.js
|----depB
|-----bar.js
|-----node_modules
|-----depA
| ----- index.js
|-----depC
|---foorbar.js
|---node_modules
|----index.js
从目录上看,myAPP,depB, depC都依赖于名字为depA的模块,当myAPP加载depA时,他会从它所在目录的node_modules路径中去查找,而depB,depC在加载depA时,会从他们所在路径的node_modules路径中查找,这样他们虽然都在加载同名字的模块,但是由于加载路径不一样,因此他们会得到不同的实例,于是他们的加载就不会产生冲突或混乱。
最后我们看看require的加载时如何解决循环依赖的。假设我们的代码模块之间存在如下循环依赖:
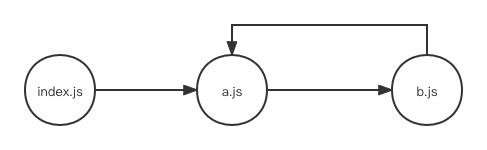
我们先创建a.js和b.js,a.js的内容如下:
exports.loaded = false
const b = my_require('./b')
module.exports = {
b ,
loaded: true,
}
同理我们看b.js的内容:
exports.loaded = false
const a = my_require('./a')
module.exports = {
a ,
loaded: true,
}
最后我们在index.js中添加内容如下:
const a = my_require('./a')
const b = my_require('./b')
console.log('a ->', JSON.stringify(a, null, 2))
console.log('b ->', JSON.stringify(b, null, 2))
如果我们运行上面代码会有什么结果,首先我们要问的是,上面代码在运行时是否会陷入死循环?答案是否定的,我们先给出输出结果,然后再分析为什么,上面代码运行后输出结果如下:
a -> {
"b": {
"a": {
"loaded": false
},
"loaded": true
},
"loaded": true
}
b -> {
"a": {
"loaded": false
},
"loaded": true
}
我们分析一下为什么会产生上面结果。首先my_require(‘./a.js’),在执行时首先会把a.js对应的module对象进行缓存,对应的语句如下:
my_require.cache[id] = module
这个缓存是代码没有产生死循环的原因。然后执行LoadModule,这个函数会执行a.js中的代码,在a.js代码中,第一行为:
exports.load = false
这句话执行后会使得它对应的module变为module.exports.load = false,接着执行my_require(‘./b’),这条语句执行时会执行判断 if (my_require.cache[id]),此时id对应’./a.js’,由于前面已经对a.js的模块进行了缓存,所以这个if成立,于是执行return my_require.cache[id].exports ,注意它对应的正好就是前面说的module.exports.load,而它的值设置为false, 这就是为何在a->对应输出中存在:
“a”: {
“loaded”: false
},
的原因。
然后在b.js中继续往下执行语句:
module.exports = {
a ,
loaded: true,
}
于是b模块中的loaded变量被设置成true,完成后代码重新回到a.js,然后也继续执行它对应的语句:
module.exports = {
b ,
loaded: true,
}
注意此时这里的b对应的就是:
"b": {
"a": {
"loaded": false
},
"loaded": true
},
由于a.js代码在执行完毕前将loaded变量设置成true,因此最后loaded变量设置为true,这也就是为何代码输出给定结果的原因。更详细的讲解和演示请在B站搜索Coding迪斯尼,更多干货:http://m.study.163.com/provider/7600199/index.htm?share=2&shareId=7600199















 1340
1340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









