







 本文详细介绍了如何在Java环境下安装和使用Kuromoji进行日语分词,对比了Mecab等工具,提供了从下载、配置到实际应用的全过程指导。
本文详细介绍了如何在Java环境下安装和使用Kuromoji进行日语分词,对比了Mecab等工具,提供了从下载、配置到实际应用的全过程指导。
之前尝试过一些中英日三种语言的NLP任务,中文和日语的共同点是没有天然的分词,研究文本时需要提前完成分词任务,中文分词任务强烈推荐是用jieba分词,因为很容易装,使用也很简单,一两行代码就可以得到比较好的分词结果。日语中分词工具也有很多,比如mecab,这个应该是用的比较多的,很多日语的分词工具多多少少都受到他的影响。但是这篇博客想说的不是mecab,而是Kuromoji。CSDN上也有很多关于Kuromoji的博文,很多都是一些关于他的优势之类的内容,都是比较提纲挈领的,但是稍微缺少更加细节化的内容,因为接触分词任务的一般都是最开始做研究的小白,就跟我一样。所以我想在自己安装完之后稍微补充一些,如果有兴趣的同学可以一起交流一下,我的邮箱会放在最后的地方,有不清楚的我们可以一起研究一下。
首先是下载,下载可以从官网中找到他们在github上的一个下载链接,不是很大,11M左右,很快就下好了。
官网链接
Github下载链接
附上资源网页的图片
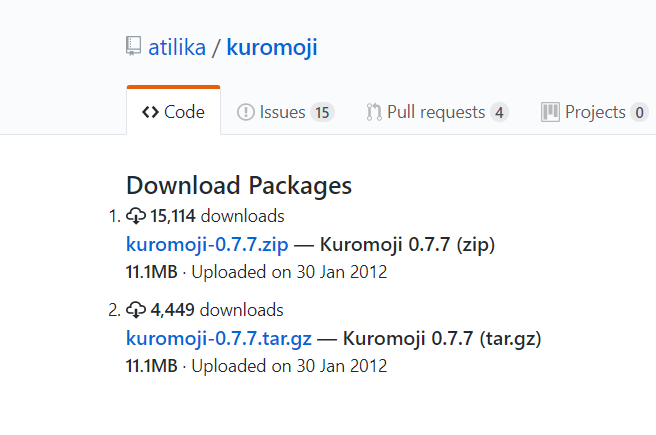
上面两个资源应该是一样的,只是压缩方式有所不同。可以选择第一个下载的人比较多的试用一下。下载完成之后可以得到一个压缩包,接下来就是很多博主没有写但是我第一装的时候弄了好久的导入部分了。
我很早之前就安装好了一次,这次因为想写这个博文,所以又重新安装了一次。
这里使用的是java,如果想在python上做日语的分词 python3.6还是 python3.7是可以直接安装的,
python 3.5(比如我就要自己修改了)的话好像没法直接装,附上python3.5的安装实战,日文版的。
MeCabを「Windows10;Python3.5(64bit)」に入れる
以下是Java的安装步骤
下好之后解压到eclipse的workspace中新建的一个文件夹。
如下:
接下来就要让eclipse认识这个分词工具了。
点击package explorer的空白处,像下面这个图一样。
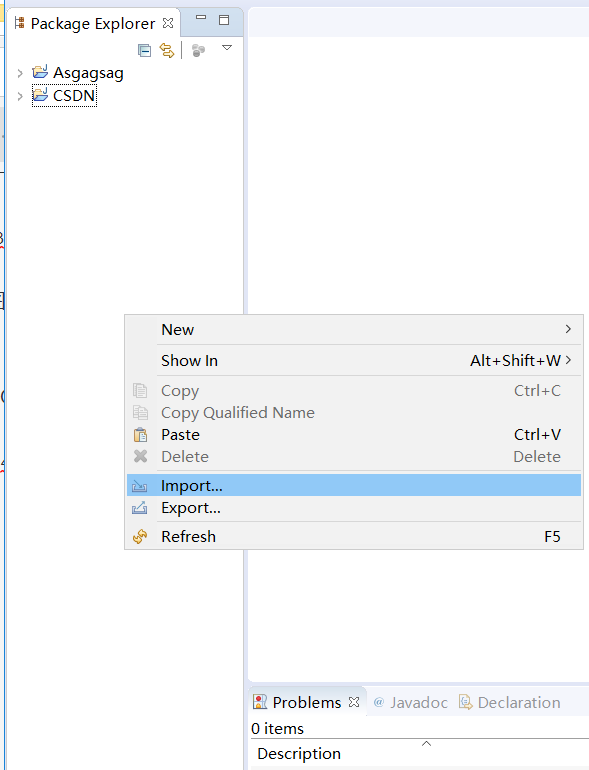
然后点击Import导入,然后点击General,选择General中最下方的选项,可以从文件夹中导入项目,然后点击next.
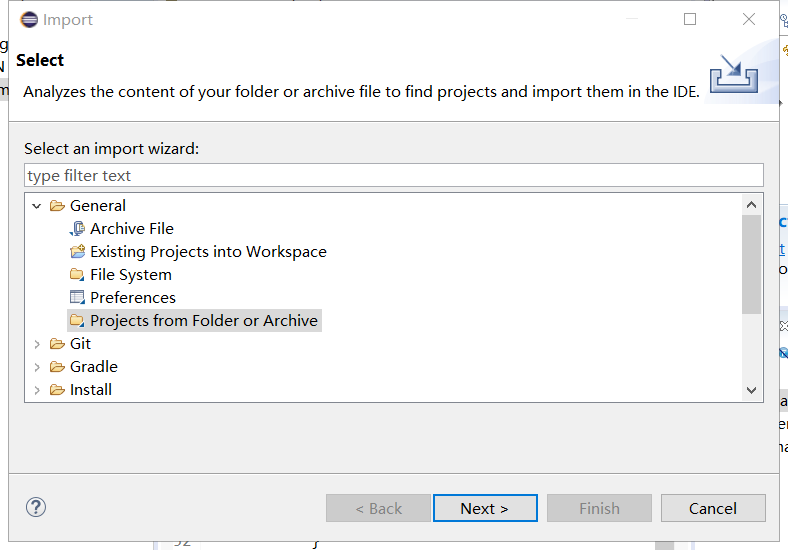
点进来可以看到
然后吧下面图上的两个红框根据自己文件所在的位置选择好文件夹就可以了,然后点一下finish
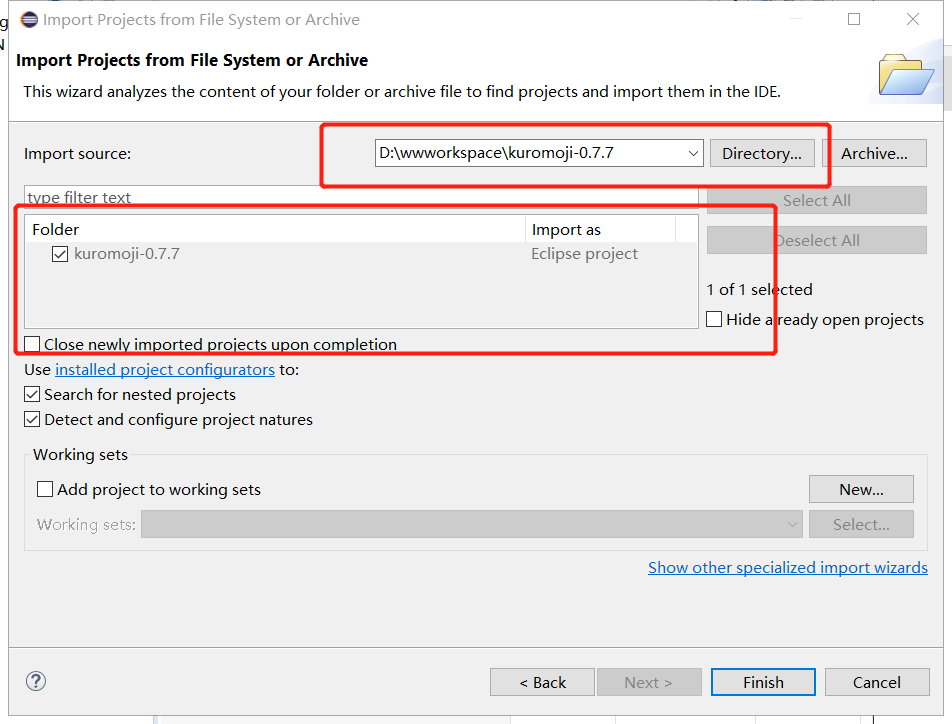
刚才的package explorer就会自动导入。
接下来就可以试用一下了。打开自带的程序,输入一行日语就可以进行分词。
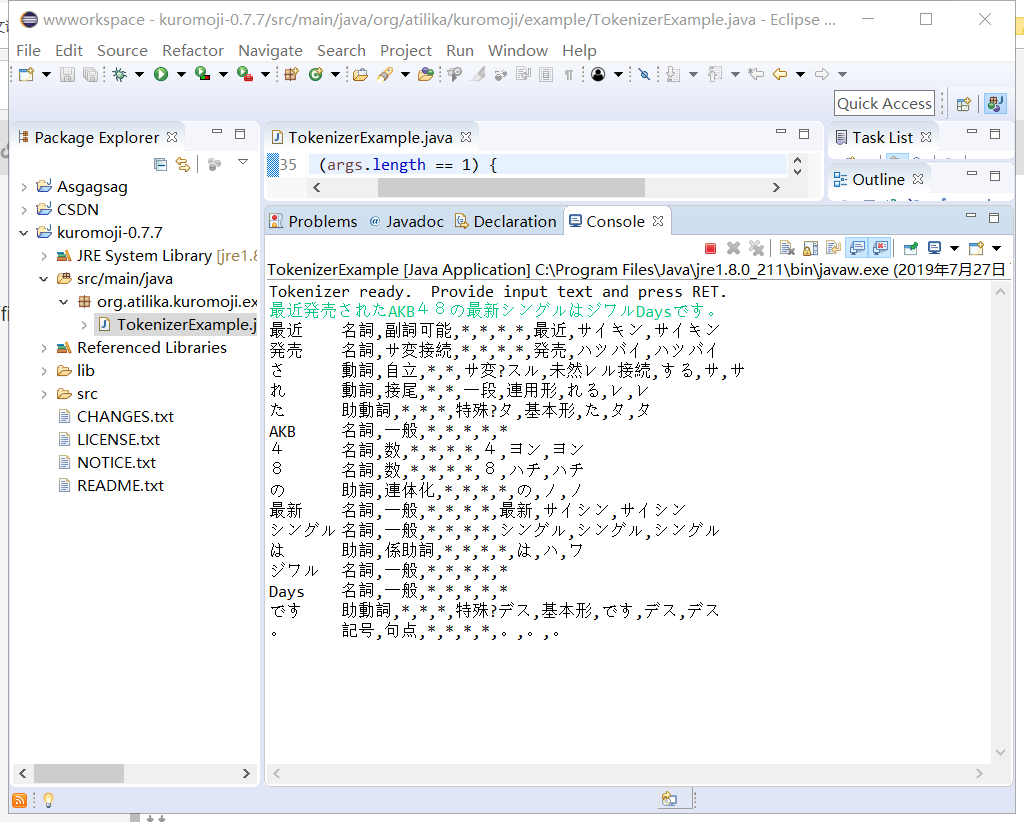
好的,这就是这个日语分词工具自带的分词方法,可以通过自带的类和方法返回词性,但是一般来讲我们在分词任务中,得到分词的结果就好了,不需要词性的说明,这时候程序里面稍微改动一下就可以实现了,可以动手试一下。
最后附上一个我自己写的对文档中的文章进行分词的程序,加入输入输出流就可以了。
package org.atilika.kuromoji.example;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.List;
import org.atilika.kuromoji.Token;
import org.atilika.kuromoji.Tokenizer;
import org.atilika.kuromoji.Tokenizer.Builder;
public class TextSegmentation{
public static void main(String[] args) {
Builder builder = Tokenizer.builder();
Tokenizer normal = builder.build();
File writeName = new File("D:\\Pycharm\\pycharmCode\\japanese_mission\\twitter_emotion\\tweets_segment.txt");
String InputPathName = "D:\\Pycharm\\pycharmCode\\japanese_mission\\twitter_emotion\\tweets.txt";
try (FileReader reader = new FileReader(InputPathName);
BufferedReader br = new BufferedReader(reader);
FileWriter writer = new FileWriter(writeName);
BufferedWriter out = new BufferedWriter(writer);
) {
String[] line;
while((line = br.readLine().split(",",2)) != null) {
System.out.println(line[0]);
List<Token> tokensNormal = normal.tokenize(line[1]);
String str = line[0]+","+disp(tokensNormal) + "\r\n";
out.write(str);
out.flush();
}
}catch (IOException e) {
e.printStackTrace();
}
}
public static String disp(List<Token> tokens) {
String str = "";
for (Token token : tokens)
str += (token.getSurfaceForm() + " ");
return str;
}
}
写的不好的地方希望大家指正,但是还是希望能温柔一点,贯彻爱与和平。
另外真心推荐一个快捷键
ctrl + f
找关键词神速。
邮箱:tttyyy0504@outlook.com
欢迎来人来函以及来而无往非礼也之洽谈。

















 1631
1631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









