







前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
本文主要介绍建表语句与数据操作语句的详细过程 , 首先我们进行一个知识的回顾吧.
文章目录

知识回顾
先进行数据库的操作
创建数据库
语法 :
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT '注释'] #可选 , 设置注释
[LOCATION hdfs_path] #可选 , 设置新建的数据库在hdfs当中的存储路径
[WITH DBPROPERTIES] #可选
若不指定路径LOCATION,其默认路径为${hive.metastore.warehouse.dir}/database_name.db
查看数据库
SHOW DATABASES [LIKE '通配符表达式']
查看数据库的详细情况
DESCRIBE DATABASE [EXTENDED] db_name
修改数据库
--修改dbproperties
ALTER DATABASE database_name SET DBPROPERTIES (property_name=property_value, ...) ;
--修改location
ALTER DATABASE database_name SET LOCATION hdfs_path ;
--修改owner userhive
ALTER DATABASE database_name SET LOCATION OWNER USER user_name ;
删除数据库(慎用)
DROP DATABASE [IF EXITSTS] database_name [RESTRICT | CASCADE];
接下来时操作表的语句
创建表(普通语法)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]hive
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
CTAS语法建表
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
Create Table Like建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[LIKE exist_table_name]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
以上就是对上篇文章的一个知识回顾 .
下面我们开始本篇文章的学习 :
建表方式的详解(重点)
内部表与外部表的区别
使用表格看一下内部表与外部表的区别 :
| 创建语句 | 存储位置 | 删除数据 | 理念 | |
|---|---|---|---|---|
| 内持部表 | CREATE TABLE … | Hive管理 , 默认为 /user/hive/warehouse | 输出元数据且删除数据 | 持久使用 |
| 外部表 | CREATE EXTERNAL TABLE … | 随意一个位置 , LOCATION关键字指定 | 仅仅删除元数据 | 临时链接 |
内部表的创建
未被external关键字修饰的即是内部表, 即普通表。
内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
create table if not exists student(
id int comment 'id',
name string
)
row format delimited fields terminated by '\t'
location 'user/hive/warehouse/student'
这里先解读一下这个建表语句 :
-
表的元数据
create table if not hiveexists student( id int comment 'id', name string )这里的建表语句跟mysql的建表语句一样 , 基本上不存在其他的区别 .
-
序列化与与反序列化的方式
Row Formatrow format delimited fields terminated by '\t'因为当前创建的表较为简单, 只需要对每行数据进行简单的换行符分隔即可 , 因为不存在Array , Struct这种类似的数据类型 .
-
数据在HDFS但这个的存储位置
Locationlocation 'user/hive/warehouse/student' -
默认声明的属性, 文件格式
Stored As默认情况下 , 文件的存储类型为
.txt
以上就完成了我们的表创建 , 接下来我们进行文件的上传存储 , 测试文件是否能被正确的解析出来 .
外部表的创建
外部表,创建表被EXTERNAL关键字修饰,从概念是被认为并非Hive拥有的表,只是临时关联数据去使用。
创建外部表也很简单,基于外部表的特性,可以总结出:
外部表 和 数据 是相互独立的, 即:
- 可以先有表,然后把数据移动到表指定的
LOCATION中 - 也可以先有数据,然后创建表通过
LOCATION指向数据
- 在Linux上创建新文件,test_external.txt,并填入如下内容:
vim test_external.txt
#以下就是文件内存
#注意我们每一行的数据需要使用'\t'分隔开 , 这里我采用了Java代码完成了文件的创建
1001 张三
1002 李四
1003 王五
1004 赵六
1005 李五
1006 李六
1007 李七
1008 李八
1009 李九
10010 李十
-
在创建hive的外部表, 使用
EXTERNAL修饰create external table test_ext1 ( id int, name string ) row format delimited fields terminated by '\t' location '/tmp/test_ext1';注意:在外部表当中 , 文件分隔符一定要指定的, 一定要与实际的业务场景相符 .
-
先检查hdfs当中的
/tmp/test_ext1是否存在hdfs dfs -ls /tmp/testsh
可以看到hdfs的文件已经存在了
-
接下来上传文件到Hive表指定的路径当中 , 完成之后 , hive的表就能自动识别文件当中的数据 , 自动完成数据写入.
hdfs dfs -put test_external.txt /tmp/test_ext1/可以看到 , 文件上传成功后 , 表的数据就自动被hive识别了 .
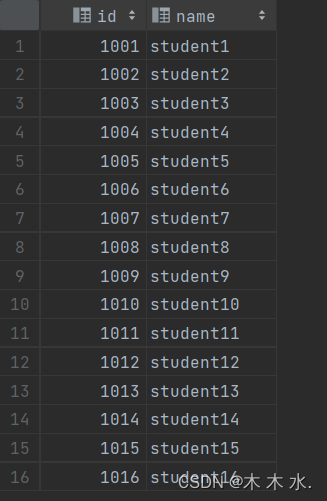
-
接下来我们可以先删除表 , hdfs当中的数据不会受到任何影响
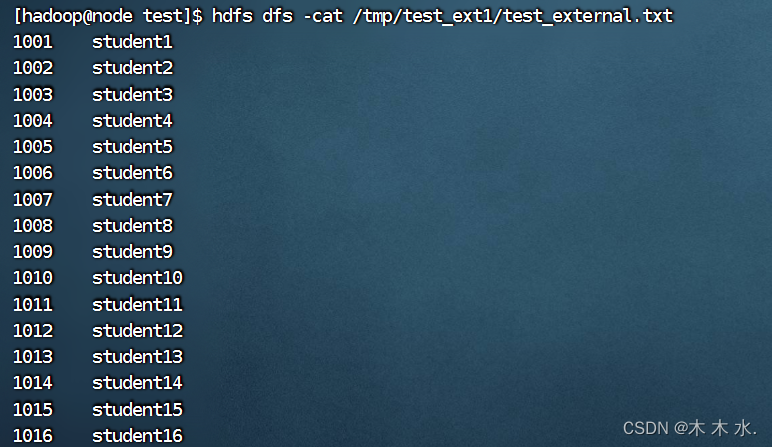
drop table test_ext1;此时我们去查看hdfs当中的数据
hdfs dfs -cat /tmp/test_ext1/test_external.txt可以看到数据并不会受到影响, 以此证明外部表的方式Hive的元数据和Hdfs是分开存储的, 且对它们的删除是不会影响的
内部表和外部表的转换
-
如果我们忘记了表的类型, 可以先查看表类型
desc formatted [table_name]就以刚刚我们创建的外部表为例 :
可以看到
Table Type字段是EXTERNAL_TABLE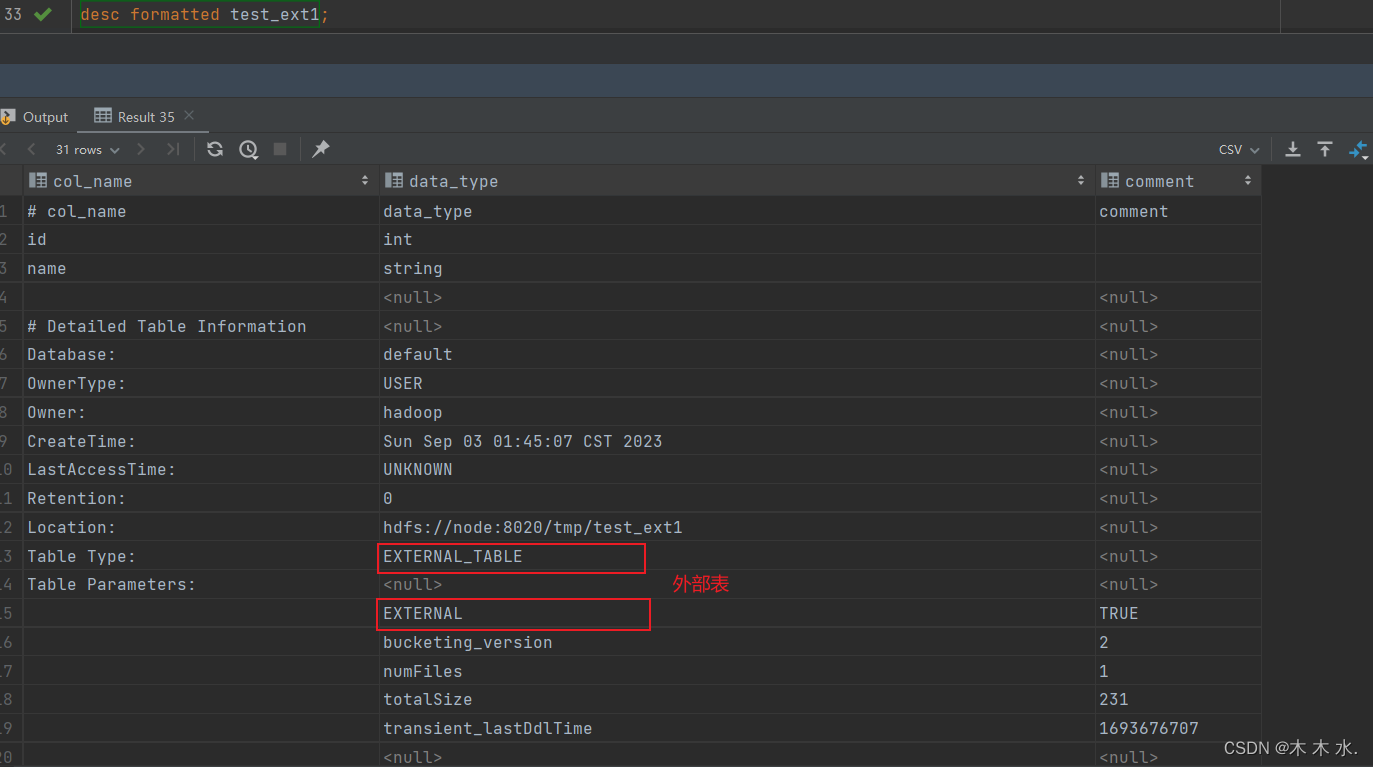
-
此时为了方便测试我们新建两个简单的表进行表的转换操作
##创建内部表 create table t1(id int ); ##创建外部表 create table t1( id int ) row format delimited fields terminated by '\t' location '/tmp/t2'; -
表类型的转换分为两种
-
外部表转内部表
#将t1转为外部表 alter table t1 set tblproperties ('EXTERNAL'='TRUE');
可以看到表的类型已经是外部类型了
-
内部表转外部表
#将t2转为内部表 alter table t2 set tblproperties ('EXTERNAL'='FALSE');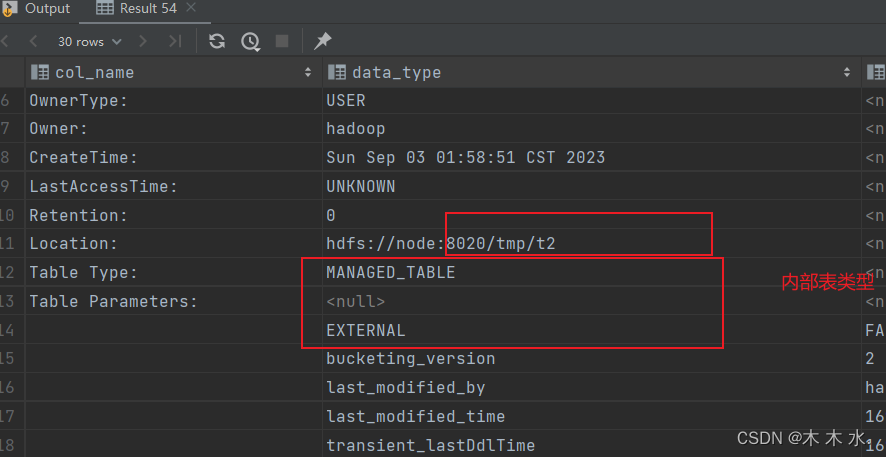
可以看到表的类型已经是内部类型了
-
-
要注意:
('EXTERNAL'='FALSE')或('EXTERNAL'='TRUE')为固定写法,区分大小写!!!
SERDE和复杂数据类型
前面我们一直介绍Hive的序列化和反序列化 , 以及我们提到了Hive的Array类型和Struct类型 , 我们下面来对其进行一个详细的演示 .
若现有如下格式的JSON文件需要由Hive进行分析处理,请考虑如何设计表?
{
"name": "dasongsong",
"friends": [
"bingbing",
"lili"
],
"students": {
"xiaohaihai": 18,
"xiaoyangyang": 16
},
"address": {
"street": "hui long guan",
"city": "beijing",
"postal_code": 10010
}
}
请注意 , 在业务场景当中 , JSON字符串是一个文件当中的一行完整的数据, 这里只是为了方便观看 , 将其格式化了 .
我们对这个JSON字符串进行一个详细的分析 :
-
name字段这个字段就是一个String类型的字符串
-
friends字段这个字段是一个Array类型的字符串
-
student字段这个字段内部还存在着一个key, value格式的数据类型,且value类型严格存储数字 我们这里使用Map结构 -
address字段这个字段内部也是一个key, value格式的数据类型, 但是这里的value既存储着数字 ,还存储着String , 我们这里就使用struce结构
对表的实现有两种方式
- 我们可以对其进行手动的序列化 , 但是需要我们将分隔符和字段全部一一对应 , 这种方式可以实现但是没必要
- 使用专门的JSON文件的
JSON Serde, 设计表字段时 , 表的字段与JSON字符串的一级字段保持一致 ,JSON Serde的底层就是根据一级字端作为key , 再一个个找到一级字段对应的value .
我们这里先设计表结构 , 根据以上对JSON字符串分析, 我们需要对name 字段采用 String , friends 字段采用 Array , student 字段采用 Map , 对 address 字段采用 Struct
create table teacher
(
name string,
friends array<string>,
students map<string,int>,
address struct<city:string,street:string,postal_code:int>
)
#此处的row format是采用官网提供的格式
row format serde 'org.apache.hadoop.hive.serde2.JsonSerDe'
location '/user/hive/warehouse/teacher';
这样我们就完成了表的定义
hdfs dfs -ls /user/hive/warehouse
可以看到, 我们 hdfs 的/user/hive/warehouse路径下已经创建此表的数据存储路径了

接下来我们准备好数据 , 注意, 这些数据一定是要压缩格式的一行数据 , 而不能是之前拿着格式化后的JSON格式数据 , 不然Serde是不能识别的 .
{"name":"dasongsong","friends":["bingbing","lili"],"students":{"xiaohaihai":18,"xiaoyangyang":16},"address":{"street":"hui long guan","city":"beijing","postal_code":10010}}
{"name":"dasongsong","friends":["bingbing","lili"],"students":{"xiaohaihai":18,"xiaoyangyang":16},"address":{"street":"hui long guan","city":"beijing","postal_code":10010}}
接下来我们在创建文件的当前文件夹当中将此文件上传到HDFS当中去sh , 再观察数据在Hive当中的数据序列化情况.
hdfs dfs -put test_testteacher.txt /user/hive/warehouse/teacher
可以看到数据已经自动的通过JSON Serde转为Hive的表能够存储的数据了.

大功告成~~
复杂数据类型的取值
复杂数据类型的取值其实也是跟sql语句差不多的
-
Array取值取全部值 , 就不要再字段上加上索引, 就会默认查询全部:
select friends from teacher;
取固定索引的值 ,就在字段上加上想要的值的索引即可 , 注意 , 这里选取的是第一个字段的所有值
select friends[0] from teacher;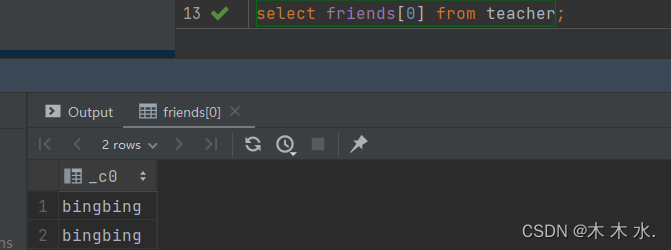
-
map取值取全部值, 只需要加上字段即可 , 不要指定对应的key
select students from teacher;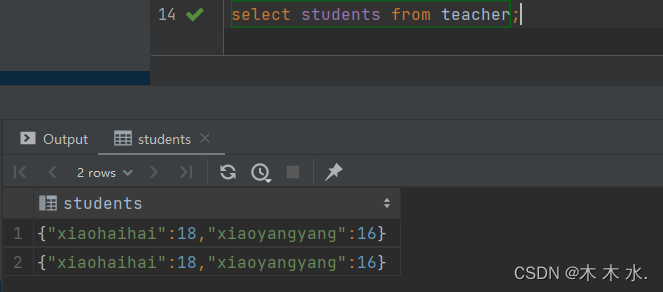
select students[xiaohaihai] from teacher;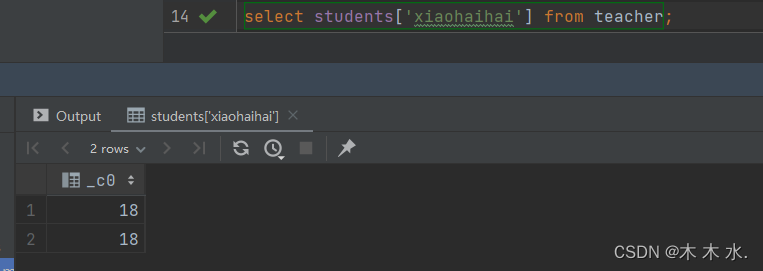
-
取
Struct的操作与上面不太一样了, 我们取具体的值是采用[字段名.属性名]的方式取全部值
select address from teacher;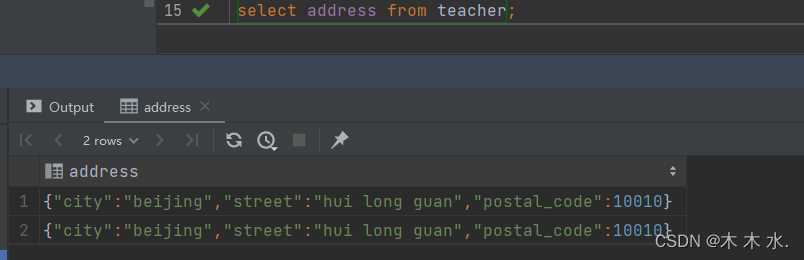
取相应属性的值采用
[字段名.属性名]select address.city from teacher;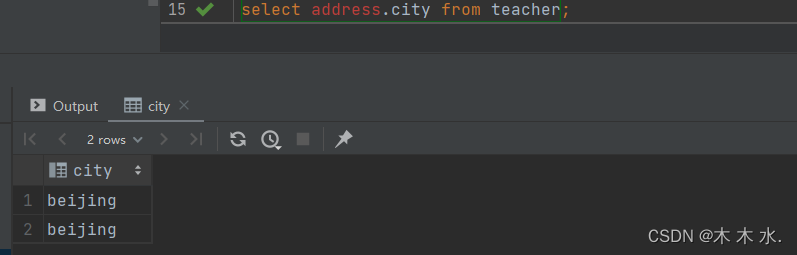
这里出现报红是因为DataGrip不支持
[字段名.属性名]这种语法 , 但是真正编译执行的时候是能够将其转换为hive可以执行的语句的 , 无需担心
以上就是复杂数据类型取值操作
CTAS方式建表与CTL建表
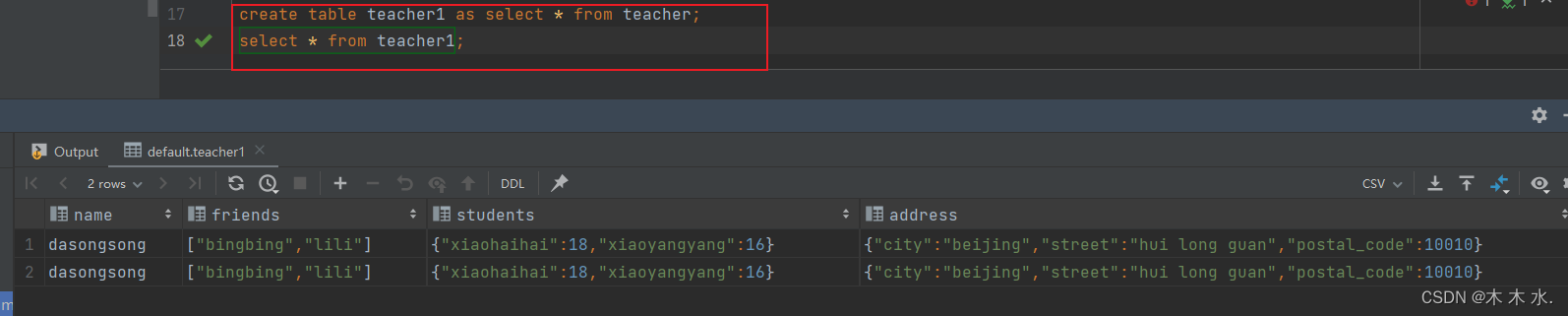
CTAS(Create Table As Select) : 这种方式建表可以将查询语句的结果作为新建表的内容创建
create table teacher1 as select * from teacher;
可以看到 , 这两张表的数据完全一致, 是因为查询的结果是teacher表的全部
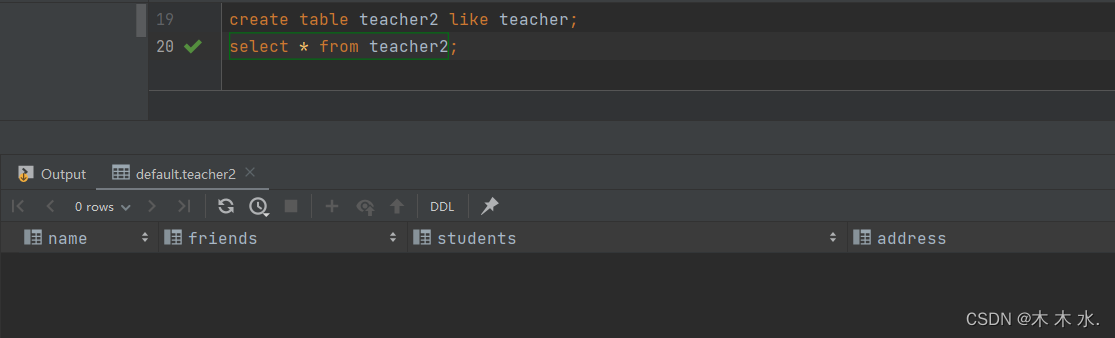
CTL建表(Create Table Like ) : 这种方式建表只会使建立的表结构一致 , 但是数据不会进行拷贝, 下面我们进行测试
create table teacher2 like teacher;
可以看到,这是一张空表, 但是其字段与 like 关键字后的表一致
操作表
查询表
在大数据领域 , Hive的表一般的是非常多的, 如果想一下子全部展示 , 我们估计找到想要的表还得花上很长的时间 , 这里需要使用到hive给我们提供的语法了.
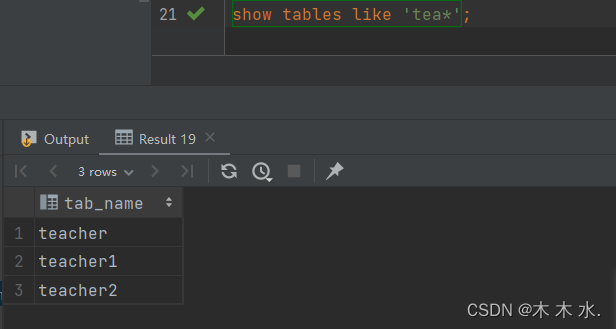
SHOW TABLES [IN database_name] LIKE ['通配符']
like通配符表达式 : * 表示任意个字符 , | 表示或的关系
show tables like 'tea*'
这里查询与'tea'开头的表名
展示表
我们想知道表的详细信息的时候, 就需要使用到DESCRIBE关键字了
DESCRIBE [EXTENDED | FORMATTED] [db_name.]table_name
EXTENDED: 展示详细信息FORMATTED: 对详细信息进行格式化的展示
先查看基本信息
desc teacher;
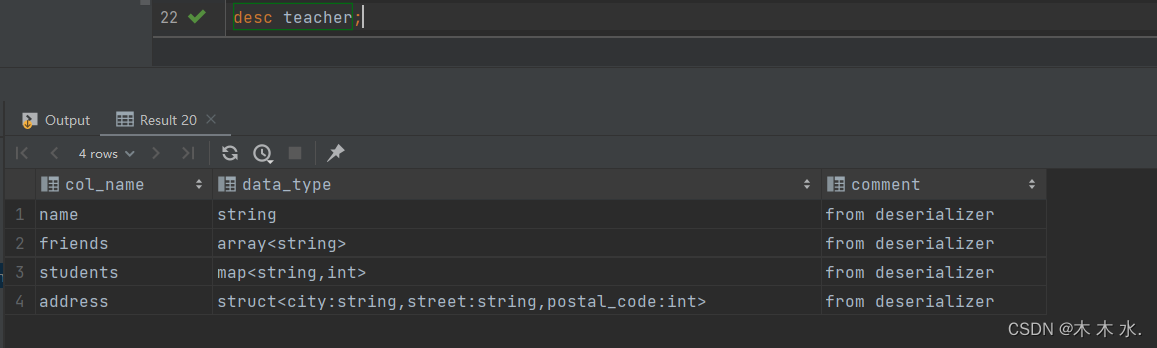
我们可以看到, 基本信息就是表的字段 , 字段的数据类型 , 和对应的注释
再查看表的详细信息
desc formatted teacher;
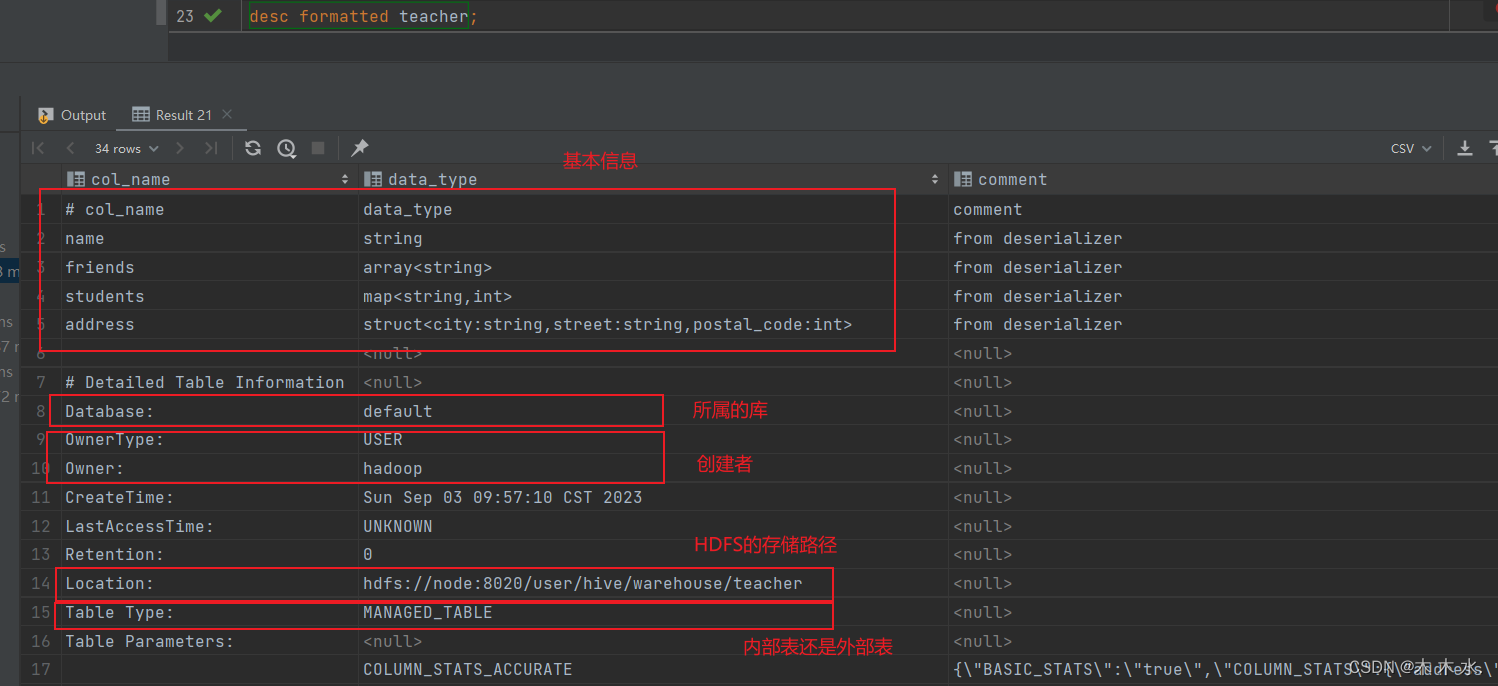
可以看到 , formatted详细信息还是挺多的 , 看我们需要信息的多少而决定需不需要使用formatted
修改表
Hive是支持修改表的元信息的 , 可以修改表名与字段名
修改表名
ALTER TABLE table_name RENAME TO new_table_name
修改字段(列)信息
#增加列信息
ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...)
#更新列信息
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
#替换列信息
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
-
增加列信息
该语句允许用户增加新的列,新增列的位置位于末尾, 允许一次性增加多个字段
-
更新列信息
该语句允许用户修改指定列的列名、数据类型、注释信息以及在表中的位置。
-
替换列信息
该语句允许用户用新的列集替换表中原有的全部列。
注意 , Hive不允许删除列信息 , 因为HDFS也不允许删除文件数据
删除表与清空表
删除表语法
DROP TABLE [IF EXISTS] table_name ;
清空表语法
TRUNCATE [TABLE] table_name
注意:truncate只能清空管理表(内部表),不能删除外部表中数据。
以上就是本文主要讲的内容 , 至此, 对Hive的DDL操作以及学习完了 , 下一篇文章开始介绍查询语句和查询的优化了 .
















 2460
2460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











