







 本文介绍了Hive中的分桶表,包括其概念、与分区表的区别、创建方法(需开启自动优化并指定分桶列),以及为何必须使用insertselect而非loaddata进行数据插入。重点讲解了数据如何通过Hash取模分配到各个桶,以及分桶表如何通过减少操作数据量提升性能。
本文介绍了Hive中的分桶表,包括其概念、与分区表的区别、创建方法(需开启自动优化并指定分桶列),以及为何必须使用insertselect而非loaddata进行数据插入。重点讲解了数据如何通过Hash取模分配到各个桶,以及分桶表如何通过减少操作数据量提升性能。
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
前面我们学习了Hive的分区表操作,了解了Hive当中的数据可以按照分区列进行划分,但是Hive的高阶用法还不止一个,我们接下来学习Hive的分桶表,也是Hive当中最为重要的部分之一,大家认真学习吧!

文章目录
初识分桶表
分桶表的概念
在Hive中,分桶表(Bucketed table)是一种特殊的表类型。
它将存储在HDFS(Hadoop分布式文件系统)上的数据进一步划分成固定数目的桶。每个桶中包含相同数量的数据,同时每个桶都按照指定的列进行排序。
与分区表的类比
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式。
但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。
我们使用图片加深一下理解:
这是分桶的情况,直接将一个表分成三个文件进行存储
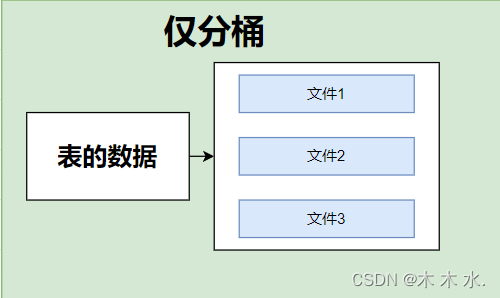
分桶又分区,这种情况下,每一个区的文件都会有三个文件进行存储
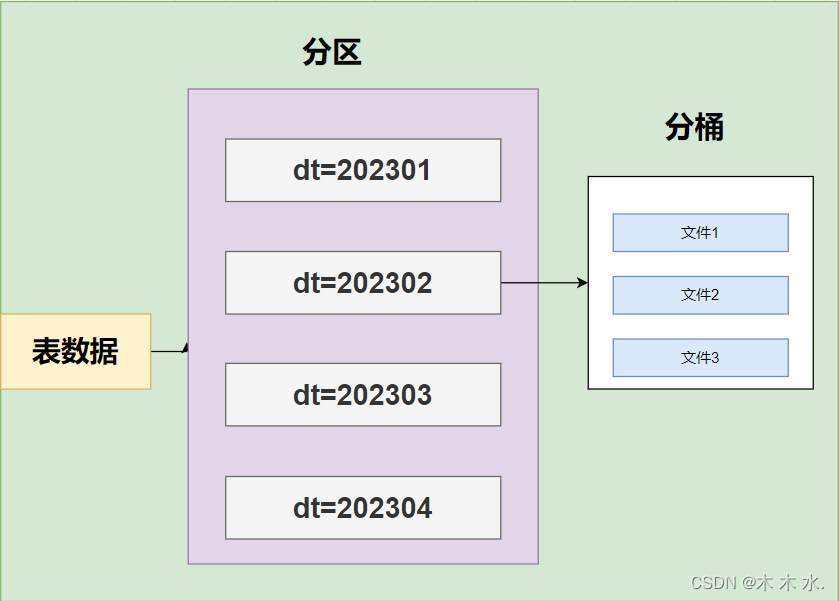
分区桶的创建
我们执行创建分区桶之前,我们先开启hive分桶的自动优化
set hive.enforce.bucketing=true
分桶自动优化会帮助我们自动将map reduce的任务与我们的分桶保持一致
语法:
create table course
(
c_id string,
c_name string,
t_id string
) clustered by (c_id) into 3 buckets row format delimited fields terminated by '\t';
关键字:
clustered by:根据列进行分桶,我们不能仅仅指定需要分桶的数量,还需要**指定根据哪些字段进行分桶**
into [num] buckets:指定需要分桶的数量,是相较于分区,更加细粒度的一种划分
分区桶插入数据
##查看myhive.db中course表存不存在
hdfs dfs -ls /user/hive/warehouse/myhive.db
##查看course表中有无数据
hdfs dfs -ls /user/hive/warehouse/myhive.db/course
可以看到

我们需要注意:
分桶表的数据加载,由于分桶表的数据加载通过load data无法执行,只能通过insert select.
所以插入数据的方式为:
-
创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
##创建临时表,起到数据中转的作用 create table course_common ( c_id string, c_name string, t_id string ) row format delimited fields terminated by '\t'; ##加载数据进入临时表当中 load data local inpath '/export/test/course.txt' into table course_common;可以看到数据已经成功的插入中转表了。
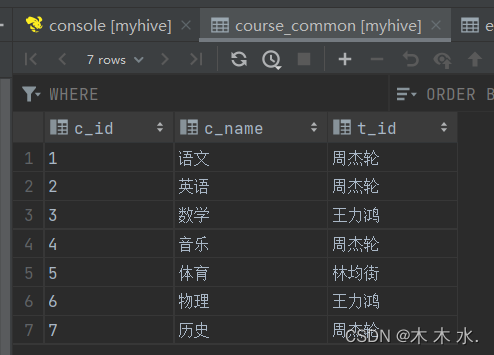
-
然后通过insert select 从临时表向桶表插入数据
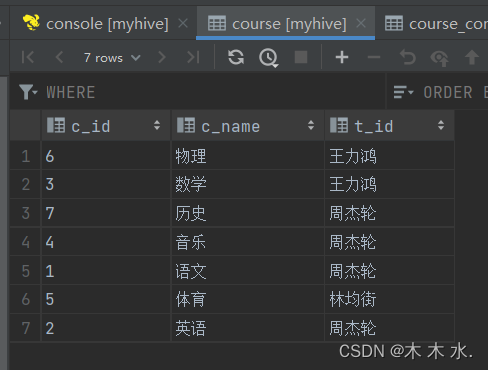
##将中间表的数据插入分桶表 insert overwrite table course select * from course_common cluster by (c_id);注意,在向分桶表插入数据的时候,需要我们使用
cluster by关键字,使其符合我们创建分桶表时的字段一致。可以看到中转表的数据已经插入分桶表了。
此时我们再次查看此分桶表在HDFS当中的存储:
hdfs dfs -ls /user/hive/warehouse/myhive.db/course

可以看到分桶表按照我们的clusered by 进行分桶,分成了三个文件进行存储。
分桶表进阶
为什么不可以使用load data ,必须使用insert select 插入数据
如果没有分桶设置,插入(加载)数据只是简单的将数据放入到:
- 表的数据存储文件夹中(没有分区)
- 表指定分区的文件夹中(带有分区)
没有分桶的情况下,只是将文件存储到对应的位置即可,有分区就存放到对应的分区即可
但是一旦有了分桶,情况就不一样了。
比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3,当数据插入的时候,需要一分为3,进入三个桶文件内。
数据划分的规则(重点)
数据的三份划分基于分桶列的值进行hash取模来决定
由于load data不会触发MapReduce,也就是没有计算过程(无法执行Hash算法),只是简单的移动数据而已,所以无法用于分桶表数据插入。
Hash取模(重点)
Hash算法是一种数据加密算法,我们只需要知道其主要特征:
-
同样的值被Hash加密后的结果是一致的
-
比如字符串“hadoop”被Hash后的结果是12345(仅作为示意),那么无论计算多少次,字符串“hadoop”的结果都会是12345。
-
比如字符串“bigdata”被Hash后的结果是56789(仅作为示意),那么无论计算多少次,字符串“bigdata”的结果都会是56789。
基于如上特征,在辅以有3个分桶文件的基础上,将Hash的结果基于3取模(除以3 取余数)
无论什么数据,得到的取模结果均是:0、1、2 其中一个
同样的数据得到的结果一致,如hadoop hash取模结果是1,无论计算多少次,字符串hadoop的取模结果都是1
所以,必须使用insert select的语法,因为会触发MapReduce,进行hash取模计算。
综上所述,对应分桶表的列,不同的值可能在同一个桶当中,也可能在不同的桶当中,但是相同的桶一定在一个桶当中。
分桶表的性能提升
- 分区表的性能提升是:在指定分区列的前提下,减少被操作的数据量,从而提升性能。
- 分桶表的性能提升就是:基于分桶列的特定操作,如:过滤、JOIN、分组,均可带来性能提升。
就像下图一样:
- 查询时,需要过滤出hadoop这个单词,我们只需要对hadoop仅需取模再取余,得出hadoop在第一个文件里面,即可排除剩余的文件。分桶的数量越多,减少的无效操作越多。
- 进行多表联查时,
join可极大程度的减少join的次数。 - 使用
group by时,其实已经自动的归并为一个文件了,不需要再去查询其他文件了
以上的所有关于分桶表的性能提升操作,都需要一个前提,那就是所有操作都要基于分桶列进行操作。
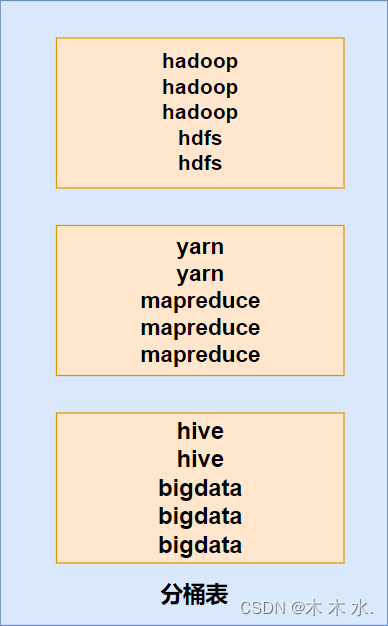
以上就是本篇文章关于分桶表的学习了。
结尾
恭喜小伙伴完成本篇文章的学习,相信文章的内容您已经掌握得十分清楚了,如果您对大数据的知识十分好奇,请接下来跟着学习路径完成大数据的学习哦,相信你会做到的~~~
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











