







前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
上一篇文章我们已经讲了Hive的DQL操作,学习了Hive的基础查询语句,学习了Hive的Union和Join查询,同时也学习了正则表达式的使用,今天我们来学习Hive的高阶的抽样查询数据和虚拟列的使用。

数据抽样
为什么要进行数据抽样
对表进行随机抽样是非常有必要的。
大数据体系下,在真正的企业环境中,很容易出现很大的表,比如体积达到TB级别。
对这种表一个简单的SELECT * 都会非常的慢,哪怕LIMIT 10想要看10条数据,也会走MapReduce流程,这个时间等待是不合适的。
Hive提供的快速抽样的语法,可以快速从大表中随机抽取一些数据供用户查看。
在Hive中,抽样表数据是为了在大规模数据集上进行快速预览和分析,而无需处理整个数据集。抽样可以带来以下好处:
- 加速查询速度:对于大型数据集,对整个数据集进行查询可能会非常耗时。通过在抽样数据上进行查询,可以加速查询速度,提供更快的结果响应时间。
- 节省计算资源:处理大规模数据集需要消耗大量的计算资源和存储空间。通过抽样表数据,在处理阶段只需处理部分数据,从而节省了计算资源和存储成本。
- 快速数据探索:对于未知的数据集,抽样表数据可以用于快速了解数据的特征、分布和结构。通过对抽样数据进行可视化、汇总和统计分析,可以帮助我们更好地理解和探索整个数据集。
- 测试和调试:在开发和测试阶段,抽样表数据可以作为样本数据,用于验证查询逻辑、调试代码和评估性能。这可以在处理高成本操作之前进行快速迭代和验证。
基于桶抽样
进行随机抽样,本质上就是用TABLESAMPLE函数
基于 随机分桶抽样 的语法:
SELECT ... FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
- y表示将表数据随机划分成y份(y个桶)
- x表示从y里面随机抽取x份数据作为取样
- colname表示随机的依据基于某个列的值
- rand()表示随机的依据基于整行
例子:
从我们之前的orders表当中抽出3个数据。
select username, orderId, totalMoney
from orders tablesample (bucket 3 out of 10 on username);
bucket 3 out of 10: 10个桶里面抽取三个值on username: 对username进行hash取模,这个值一旦计算,就是固定的。- 如果此时这张表分桶是按照username进行分桶的话,那么这个根据列的抽样的速度将会非常快。
select username, orderId, totalMoney
from orders tablesample (bucket 3 out of 10 on rand());
on rand(): 这个rand()就会导致每次运行的结果一直发生变化
基于块抽样
语法:
SELECT ... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
- num ROWS 表示抽样num条数据
- num PERCENT 表示抽样num百分百比例的数据
- num(K|M|G) 表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
注意:
使用这种语法抽样,条件不变的话,每一次抽样的结果都一致
即无法做到随机,只是按照数据顺序从前向后取。
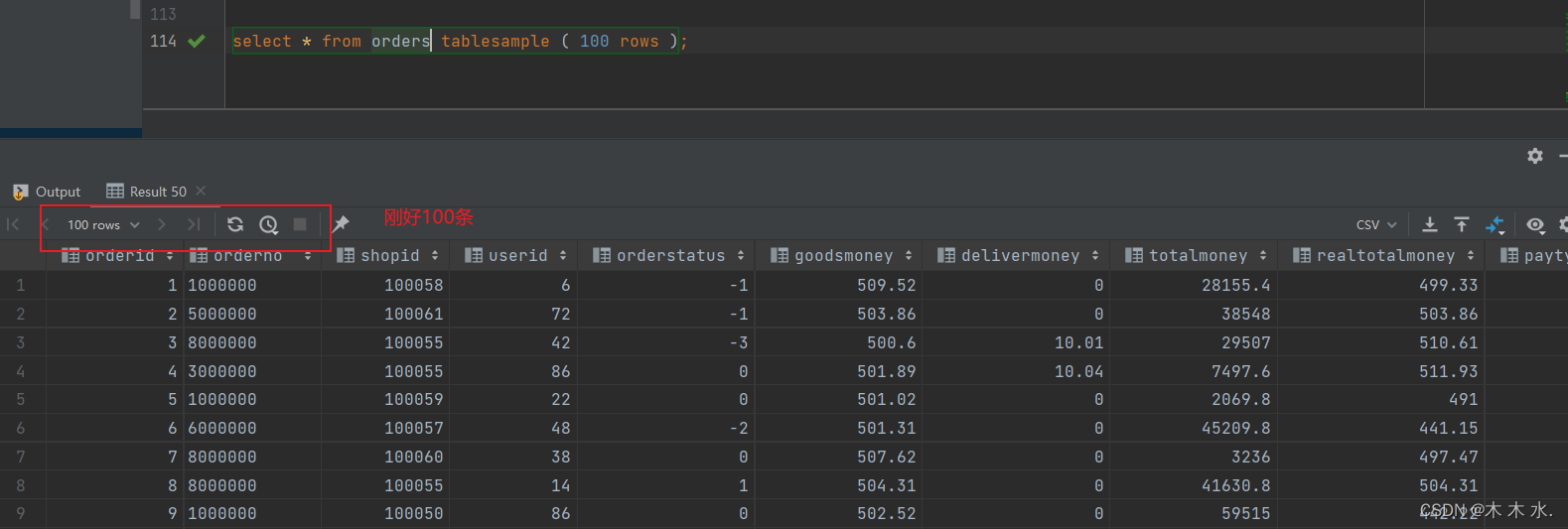
例子,抽取100条数据:
select * from orders tablesample ( 100 rows );
并且这条命令不论执行多少次,条件不变,结果就不会改变。
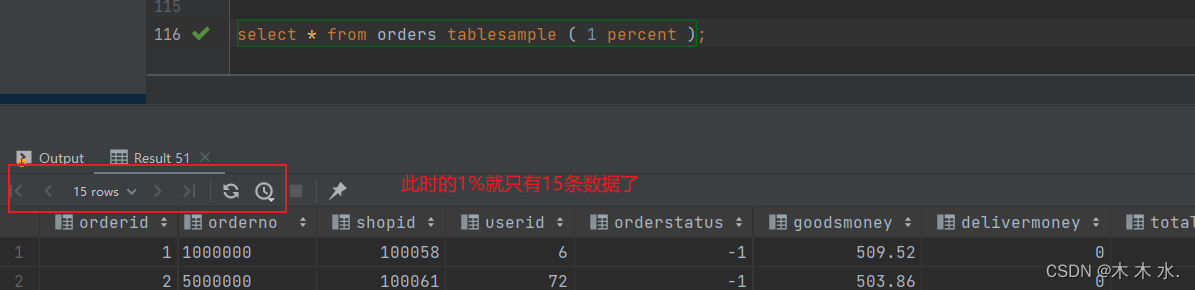
例子,取1%的数据
select * from orders tablesample ( 1 percent );
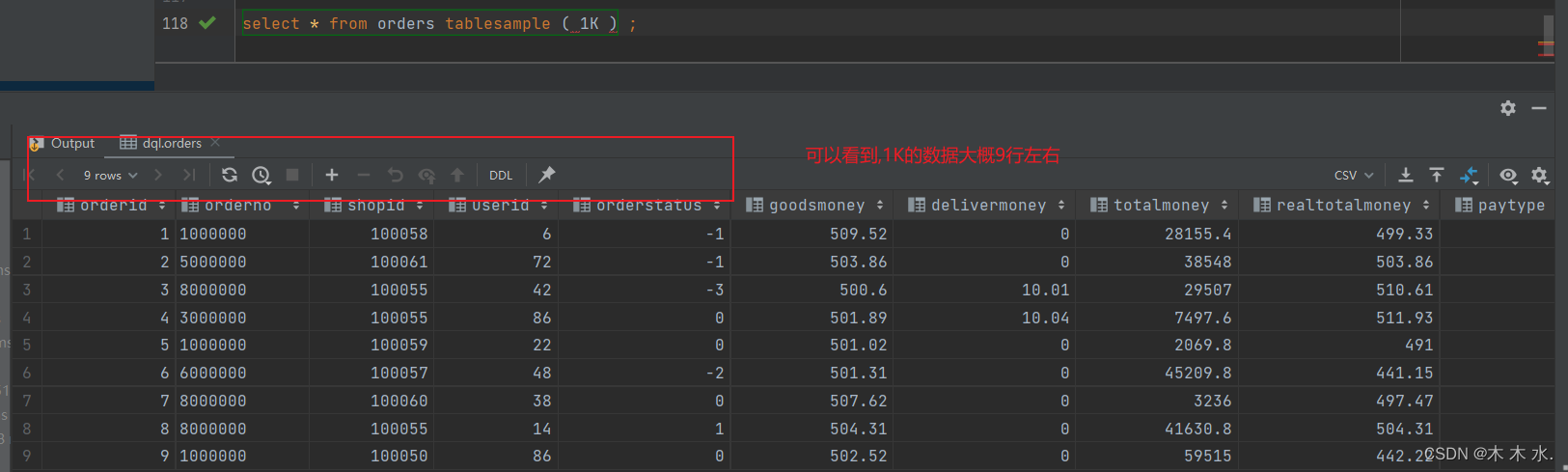
例子,取1KB大小的数据
select * from orders tablesample(1K);
虚拟列
什么是虚拟列
Hive的虚拟列(Virtual Columns)是一种特殊类型的列,它们不是存储在表中的实际列,而是根据表的其他列及其元数据计算得出的。虚拟列可以用于提供对表数据的额外元信息或在查询中进行运算和转换。
Hive中常见的虚拟列包括:
INPUT__FILE__NAME:这是一个隐含的虚拟列,它代表当前处理的输入文件的名称。它可以在查询中使用,以了解数据来自哪个文件或文件路径。BLOCK__OFFSET__INSIDE__FILE:这是另一个隐含的虚拟列,它表示当前行在其所在文件中的字节偏移量。它通常与INPUT__FILE__NAME一起使用,以获得更详细的位置信息。ROW__ID:这是虚拟列,它提供每一行的唯一标识符。ROW__ID的值由底层存储格式决定(如Parquet或ORC),它可以作为行级别的唯一标识符或排序依据。分区列(Partition Columns):当表使用分区时,分区列本身就是一种虚拟列。分区列可用于过滤和查询特定分区的数据,以及将数据映射到相应的分区。
实际操作
语法
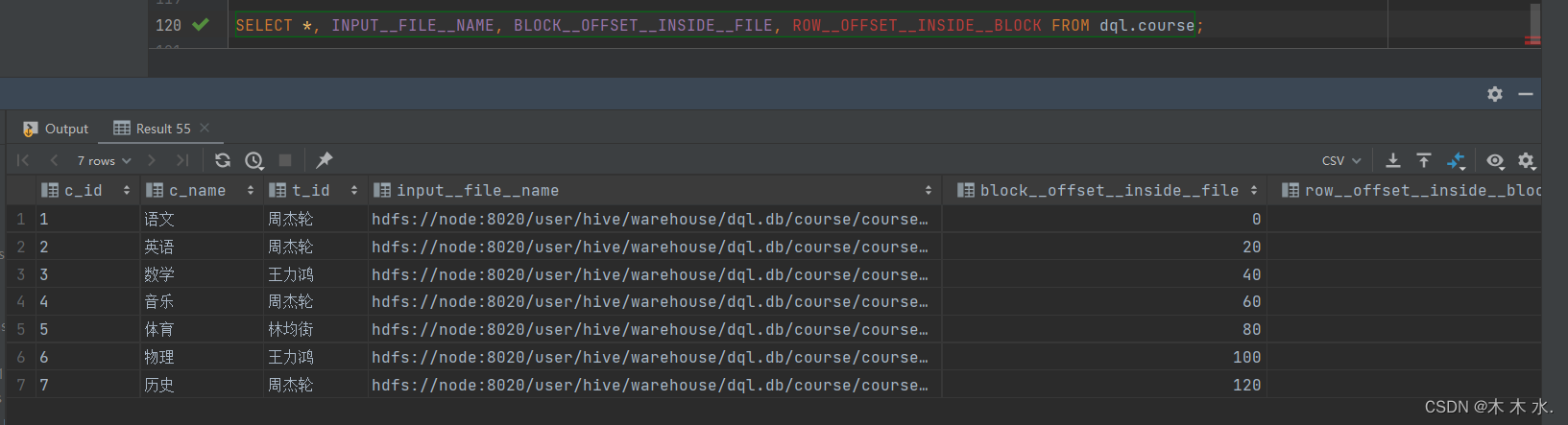
我们拿前篇文章的course表举例:
SELECT *, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM course;
注意:
==ROW__OFFSET__INSIDE__BLOCK 这个虚拟列需要我们开启SET hive.exec.rowoffset=true==这个命令才能显示出来,不然执行报错。
虚拟列是可以参与计算,参数where , group by 等等条件查询。
以上就是Hive的数据抽样与虚拟列的学习了,我们下一篇文章学习函数。
结尾
恭喜小伙伴完成本篇文章的学习,相信文章的内容您已经掌握得十分清楚了,如果您对大数据的知识十分好奇,请接下来跟着学习路径完成大数据的学习哦,相信你会做到的~~~
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











