









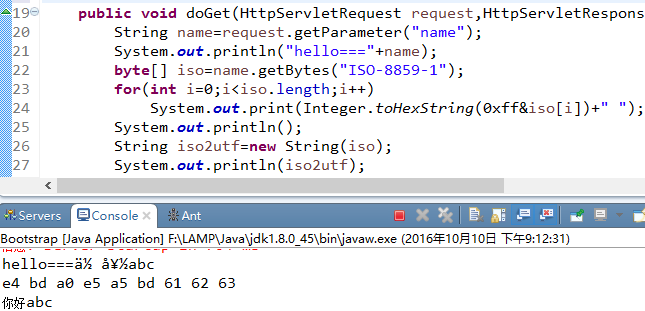
1、首先发送一个请求“http://localhost:8080/ServletDemo/Hi?name=你好abc,然后F12可以查看到下面按照utf-8后的编码,使用语句byte [] bytes=”nihao”.getBytes()也可以将“你好”转换为“e4bda0e5a5bd”:

2、我的tomcat版本为apache-tomcat-7.0.64-src,默认的编码是“ISO-8859-1”,又因为浏览器发送请求到server端是按照字节传输数据的,所以当我们使用request.getParameter(“name”)接收参数name时,将“e4 bd a0 e5 a5 bd 61 62 63 ”按照“ISO-8859-1”的编码翻译得到“ä½ å¥½abc”,这是因为“ISO-8859-1”是一个字节的编码,码表中只有0x00-0xff表示的256个字符,不支持中文,故而字符“你”即e4 bd a0编码3个字符为“ä½ ”,“好”e5 a5 bd编码为“好”:
3、从源码上看可以得到验证,在tomcat源码中,org.apache.catalina.connector.CoyoteAdapter的方法:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
// System.out.println("编码为"+enc);
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc, true);
request.setURIConverter(conv);
} else {
conv.recycle();
}
} catch (IOException e) {
log.error("Invalid URI encoding; using HTTP default");
connector.setURIEncoding(null);
}
if (conv != null) {
try {
conv.convert(bc, cc, true);
uri.setChars(cc.getBuffer(), cc.getStart(), cc.getLength());
return;
} catch (IOException ioe) {
// Should never happen as B2CConverter should replace
// problematic characters
request.getResponse().sendError(
HttpServletResponse.SC_BAD_REQUEST);
}
}
}
// Default encoding: fast conversion for ISO-8859-1
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}由上面的代码可以知道默认的编码为iso-8859-1,而且设置编码从connector.getURIEncoding()中获得,对于org.apache.catalina.connector.Connector类预测(后面遇到该问题再作深入吧)其与server.xml的connector对应。在server.xml中<Connector port="8080" />设置为<Connector port="8080" URIEncoding="UTF-8" useBodyEncodingURI="true"/>,再调试tomcat源码时可以知道输入的字符编码不再是null(为null时使用默认编码ISO-8859-1),而是“utf-8”。
response可以通过response.setCharacterEncoding(“utf-8”)来设置编码
注:还有一个问题没有解决,下面得到是“??????abc”,而不是类似上面的一样得到“ä½ å¥½abc”,有空了再来解决它:
byte[] bytes3="你好abc".getBytes("utf-8");
String str7=new String(bytes3,"ISO-8859-1");
System.out.println(str7);参考:
https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/#icomments















 6217
6217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









