










Java高级技术:Redis(二)
Redis 的数据持久化 :
1、RDB 方式 :
对内存中数据库状态进行快照
RDB 方式:将 Redis 在内存中的数据库状态保存到磁盘里面,RDB 文件是一个经过压
缩的二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态(默认下,持久化到dump.rdb 文件,并且在 redis 重启后,自动读取其中文件,据悉,通常情况下一千万的字
符串类型键,1GB 的快照文件,同步到内存中的 时间是 20-30 秒) RDB 的生成方式:
1)执行命令手动生成
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE SAVE
命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服
务器不能处理任何命令请求,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建
RDB 文件,服务器进程(父进程)继续处理命令请求,创建 RDB 文件结束之前,客户端发
送的 BGSAVE 和 SAVE 命令会被服务器拒绝
2)通过配置自动生成
可以设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命
令,可以通过 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会
执行 BGSAVE 命令
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行
服务器在 900 秒之内,对数据库进行了至少 1 次修改
服务器在 300 秒之内,对数据库进行了至少 10 次修改
服务器在 60 秒之内,对数据库进行了至少 10000 次修改2.2AOF 方式
AOF 持久化方式在 redis 中默认是关闭的,需要修改配置文件开启该方式。
AOF:把每条命令都写入文件,类似 mysql 的 binlog 日志
AOF 方式:是通过保存 Redis 服务器所执行的写命令来记录数据库状态的文件。
AOF 文件刷新的方式,有三种:
appendfsync always - 每提交一个修改命令都调用 fsync 刷新到 AOF 文件,非常非常
慢,但也非常安全 。
appendfsync everysec - 每秒钟都调用 fsync 刷新到 AOF 文件,很快,但可能会丢失一秒以内的数据 。
appendfsync no - 依靠 OS 进行刷新,redis 不主动刷新 AOF,这样最快,但安全性就差
默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾
AOF 数据恢复方式
服务器在启动时,通过载入和执行 AOF 文件中保存的命令来还原服务器关闭之前的数
据库状态,具体过程:
载入 AOF 文件 。
创建模拟客户端 。
从 AOF 文件中读取一条命令 。
使用模拟客户端执行命令 。
循环读取并执行命令,直到全部完成 。
如果同时启用了 RDB 和 AOF 方式,AOF 优先,启动时只加载 AOF 文件恢复数据。Redis 集群介绍 :
Redis3.0 版本之后支持 Cluster。集群要求集群节点中必须要支持主备模式,也就说集中的主节点(Master)至少要有一个从节点(Slave)
每一个蓝色的圈都代表着一个 redis 集群中的主节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。
对其进行存取和其他操作。Redis-Cluster 架构图
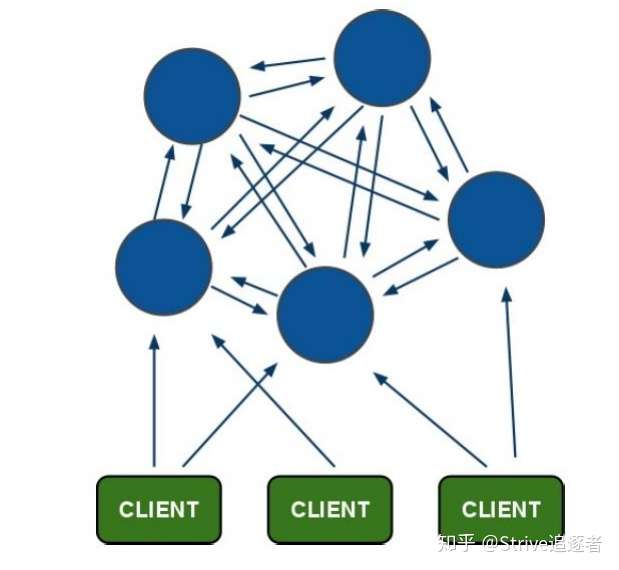
Redis-Cluster 选举:容错
Redis 之间通过互相的 ping-pong 判断是否节点可以连接上。如果有一半以上的节点去ping 一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的从节点。
如果某个节点和所有从节点全部挂掉,我们集群就进入 fail 状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入 fail 了状态。这就是我们的 redis 的投票机制,具体原
理如下图所示: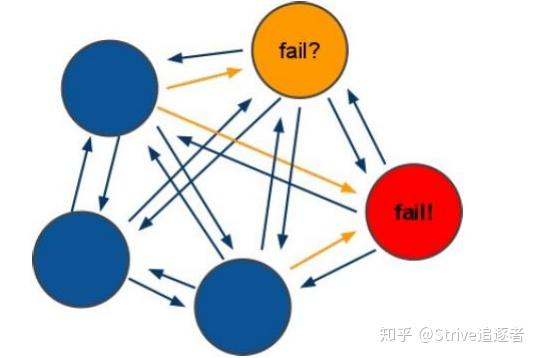
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超时(cluster-node-timeout),认为当前 master 节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
1) 如果集群任意 master 挂掉,且当前 master 没有 slave。此时集群进入 fail 状态,也可
以理解成集群的 slot 映射[0-16383]不完整时进入 fail 状态。
2) 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态. Redis-Cluster 数据存储 :
当我们的存取的 key 到达的时候,redis 会根据 crc16 的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存
取操作。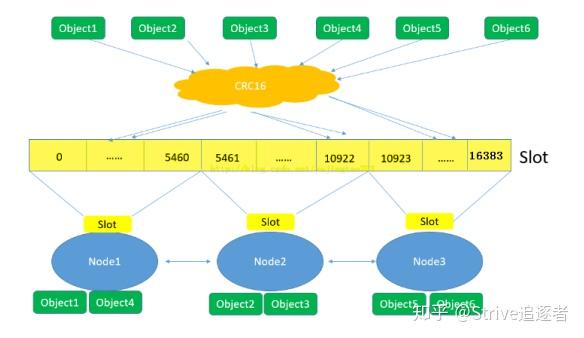
在 Node1 执行 set name kevin
1. 使用 CRC16 算法对 key 进行计算,得到一个数字,然后对数字进行取余。
CRC16 : name = 26384
26384%16384 = 10000
2. 查找到包含 10000 插槽的节点,比如是 node2,自动跳转到 node2
3. 在 node2 上执行 set name kevin 命令完成数据的插入
4. 如果在 node1 上执行 get name,先使用 CRC16 算法对 key 进行计算,在使用
16384 取余,得到插槽的下标,然后跳到拥有该插槽的 node2 中执行 get name 命令,并返回结果。
Java高级技术:Redis(二)
![]()
奔跑者
关注他
Redis 的数据持久化 :
1、RDB 方式 :
对内存中数据库状态进行快照
RDB 方式:将 Redis 在内存中的数据库状态保存到磁盘里面,RDB 文件是一个经过压
缩的二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态(默认下,持久化到dump.rdb 文件,并且在 redis 重启后,自动读取其中文件,据悉,通常情况下一千万的字
符串类型键,1GB 的快照文件,同步到内存中的 时间是 20-30 秒) RDB 的生成方式:
1)执行命令手动生成
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE SAVE
命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服
务器不能处理任何命令请求,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建
RDB 文件,服务器进程(父进程)继续处理命令请求,创建 RDB 文件结束之前,客户端发
送的 BGSAVE 和 SAVE 命令会被服务器拒绝
2)通过配置自动生成
可以设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命
令,可以通过 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会
执行 BGSAVE 命令
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行
服务器在 900 秒之内,对数据库进行了至少 1 次修改
服务器在 300 秒之内,对数据库进行了至少 10 次修改
服务器在 60 秒之内,对数据库进行了至少 10000 次修改2.2AOF 方式
AOF 持久化方式在 redis 中默认是关闭的,需要修改配置文件开启该方式。
AOF:把每条命令都写入文件,类似 mysql 的 binlog 日志
AOF 方式:是通过保存 Redis 服务器所执行的写命令来记录数据库状态的文件。
AOF 文件刷新的方式,有三种:
appendfsync always - 每提交一个修改命令都调用 fsync 刷新到 AOF 文件,非常非常
慢,但也非常安全 。
appendfsync everysec - 每秒钟都调用 fsync 刷新到 AOF 文件,很快,但可能会丢失一秒以内的数据 。
appendfsync no - 依靠 OS 进行刷新,redis 不主动刷新 AOF,这样最快,但安全性就差
默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾
AOF 数据恢复方式
服务器在启动时,通过载入和执行 AOF 文件中保存的命令来还原服务器关闭之前的数
据库状态,具体过程:
载入 AOF 文件 。
创建模拟客户端 。
从 AOF 文件中读取一条命令 。
使用模拟客户端执行命令 。
循环读取并执行命令,直到全部完成 。
如果同时启用了 RDB 和 AOF 方式,AOF 优先,启动时只加载 AOF 文件恢复数据。Redis 集群介绍 :
Redis3.0 版本之后支持 Cluster。集群要求集群节点中必须要支持主备模式,也就说集中的主节点(Master)至少要有一个从节点(Slave)
每一个蓝色的圈都代表着一个 redis 集群中的主节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。
对其进行存取和其他操作。Redis-Cluster 架构图
Redis-Cluster 选举:容错
Redis 之间通过互相的 ping-pong 判断是否节点可以连接上。如果有一半以上的节点去ping 一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的从节点。
如果某个节点和所有从节点全部挂掉,我们集群就进入 fail 状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入 fail 了状态。这就是我们的 redis 的投票机制,具体原
理如下图所示:
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超时(cluster-node-timeout),认为当前 master 节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
1) 如果集群任意 master 挂掉,且当前 master 没有 slave。此时集群进入 fail 状态,也可
以理解成集群的 slot 映射[0-16383]不完整时进入 fail 状态。
2) 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态. Redis-Cluster 数据存储 :
当我们的存取的 key 到达的时候,redis 会根据 crc16 的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存
取操作。
在 Node1 执行 set name kevin
1. 使用 CRC16 算法对 key 进行计算,得到一个数字,然后对数字进行取余。
CRC16 : name = 26384
26384%16384 = 10000
2. 查找到包含 10000 插槽的节点,比如是 node2,自动跳转到 node2
3. 在 node2 上执行 set name kevin 命令完成数据的插入
4. 如果在 node1 上执行 get name,先使用 CRC16 算法对 key 进行计算,在使用
16384 取余,得到插槽的下标,然后跳到拥有该插槽的 node2 中执行 get name 命令,并返回结果。
发布于 2019-05-11
Java高级技术:Redis(二)
![]()
奔跑者
关注他
Redis 的数据持久化 :
1、RDB 方式 :
对内存中数据库状态进行快照
RDB 方式:将 Redis 在内存中的数据库状态保存到磁盘里面,RDB 文件是一个经过压
缩的二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态(默认下,持久化到dump.rdb 文件,并且在 redis 重启后,自动读取其中文件,据悉,通常情况下一千万的字
符串类型键,1GB 的快照文件,同步到内存中的 时间是 20-30 秒) RDB 的生成方式:
1)执行命令手动生成
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE SAVE
命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服
务器不能处理任何命令请求,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建
RDB 文件,服务器进程(父进程)继续处理命令请求,创建 RDB 文件结束之前,客户端发
送的 BGSAVE 和 SAVE 命令会被服务器拒绝
2)通过配置自动生成
可以设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命
令,可以通过 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会
执行 BGSAVE 命令
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行
服务器在 900 秒之内,对数据库进行了至少 1 次修改
服务器在 300 秒之内,对数据库进行了至少 10 次修改
服务器在 60 秒之内,对数据库进行了至少 10000 次修改2.2AOF 方式
AOF 持久化方式在 redis 中默认是关闭的,需要修改配置文件开启该方式。
AOF:把每条命令都写入文件,类似 mysql 的 binlog 日志
AOF 方式:是通过保存 Redis 服务器所执行的写命令来记录数据库状态的文件。
AOF 文件刷新的方式,有三种:
appendfsync always - 每提交一个修改命令都调用 fsync 刷新到 AOF 文件,非常非常
慢,但也非常安全 。
appendfsync everysec - 每秒钟都调用 fsync 刷新到 AOF 文件,很快,但可能会丢失一秒以内的数据 。
appendfsync no - 依靠 OS 进行刷新,redis 不主动刷新 AOF,这样最快,但安全性就差
默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾
AOF 数据恢复方式
服务器在启动时,通过载入和执行 AOF 文件中保存的命令来还原服务器关闭之前的数
据库状态,具体过程:
载入 AOF 文件 。
创建模拟客户端 。
从 AOF 文件中读取一条命令 。
使用模拟客户端执行命令 。
循环读取并执行命令,直到全部完成 。
如果同时启用了 RDB 和 AOF 方式,AOF 优先,启动时只加载 AOF 文件恢复数据。Redis 集群介绍 :
Redis3.0 版本之后支持 Cluster。集群要求集群节点中必须要支持主备模式,也就说集中的主节点(Master)至少要有一个从节点(Slave)
每一个蓝色的圈都代表着一个 redis 集群中的主节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。
对其进行存取和其他操作。Redis-Cluster 架构图
Redis-Cluster 选举:容错
Redis 之间通过互相的 ping-pong 判断是否节点可以连接上。如果有一半以上的节点去ping 一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的从节点。
如果某个节点和所有从节点全部挂掉,我们集群就进入 fail 状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入 fail 了状态。这就是我们的 redis 的投票机制,具体原
理如下图所示:
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超时(cluster-node-timeout),认为当前 master 节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
1) 如果集群任意 master 挂掉,且当前 master 没有 slave。此时集群进入 fail 状态,也可
以理解成集群的 slot 映射[0-16383]不完整时进入 fail 状态。
2) 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态. Redis-Cluster 数据存储 :
当我们的存取的 key 到达的时候,redis 会根据 crc16 的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存
取操作。
在 Node1 执行 set name kevin
1. 使用 CRC16 算法对 key 进行计算,得到一个数字,然后对数字进行取余。
CRC16 : name = 26384
26384%16384 = 10000
2. 查找到包含 10000 插槽的节点,比如是 node2,自动跳转到 node2
3. 在 node2 上执行 set name kevin 命令完成数据的插入
4. 如果在 node1 上执行 get name,先使用 CRC16 算法对 key 进行计算,在使用
16384 取余,得到插槽的下标,然后跳到拥有该插槽的 node2 中执行 get name 命令,并返回结果。
Java高级技术:Redis(二)
![]()
奔跑者
关注他
Redis 的数据持久化 :
1、RDB 方式 :
对内存中数据库状态进行快照
RDB 方式:将 Redis 在内存中的数据库状态保存到磁盘里面,RDB 文件是一个经过压
缩的二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态(默认下,持久化到dump.rdb 文件,并且在 redis 重启后,自动读取其中文件,据悉,通常情况下一千万的字
符串类型键,1GB 的快照文件,同步到内存中的 时间是 20-30 秒) RDB 的生成方式:
1)执行命令手动生成
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE SAVE
命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服
务器不能处理任何命令请求,BGSAVE 命令会派生出一个子进程,然后由子进程负责创建
RDB 文件,服务器进程(父进程)继续处理命令请求,创建 RDB 文件结束之前,客户端发
送的 BGSAVE 和 SAVE 命令会被服务器拒绝
2)通过配置自动生成
可以设置服务器配置的 save 选项,让服务器每隔一段时间自动执行一次 BGSAVE 命
令,可以通过 save 选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会
执行 BGSAVE 命令
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE 命令就会被执行
服务器在 900 秒之内,对数据库进行了至少 1 次修改
服务器在 300 秒之内,对数据库进行了至少 10 次修改
服务器在 60 秒之内,对数据库进行了至少 10000 次修改2.2AOF 方式
AOF 持久化方式在 redis 中默认是关闭的,需要修改配置文件开启该方式。
AOF:把每条命令都写入文件,类似 mysql 的 binlog 日志
AOF 方式:是通过保存 Redis 服务器所执行的写命令来记录数据库状态的文件。
AOF 文件刷新的方式,有三种:
appendfsync always - 每提交一个修改命令都调用 fsync 刷新到 AOF 文件,非常非常
慢,但也非常安全 。
appendfsync everysec - 每秒钟都调用 fsync 刷新到 AOF 文件,很快,但可能会丢失一秒以内的数据 。
appendfsync no - 依靠 OS 进行刷新,redis 不主动刷新 AOF,这样最快,但安全性就差
默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾
AOF 数据恢复方式
服务器在启动时,通过载入和执行 AOF 文件中保存的命令来还原服务器关闭之前的数
据库状态,具体过程:
载入 AOF 文件 。
创建模拟客户端 。
从 AOF 文件中读取一条命令 。
使用模拟客户端执行命令 。
循环读取并执行命令,直到全部完成 。
如果同时启用了 RDB 和 AOF 方式,AOF 优先,启动时只加载 AOF 文件恢复数据。Redis 集群介绍 :
Redis3.0 版本之后支持 Cluster。集群要求集群节点中必须要支持主备模式,也就说集中的主节点(Master)至少要有一个从节点(Slave)
每一个蓝色的圈都代表着一个 redis 集群中的主节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。
对其进行存取和其他操作。Redis-Cluster 架构图
Redis-Cluster 选举:容错
Redis 之间通过互相的 ping-pong 判断是否节点可以连接上。如果有一半以上的节点去ping 一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的从节点。
如果某个节点和所有从节点全部挂掉,我们集群就进入 fail 状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入 fail 了状态。这就是我们的 redis 的投票机制,具体原
理如下图所示:
投票过程是集群中所有 master 参与,如果半数以上 master 节点与 master 节点通信超时(cluster-node-timeout),认为当前 master 节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
1) 如果集群任意 master 挂掉,且当前 master 没有 slave。此时集群进入 fail 状态,也可
以理解成集群的 slot 映射[0-16383]不完整时进入 fail 状态。
2) 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态. Redis-Cluster 数据存储 :
当我们的存取的 key 到达的时候,redis 会根据 crc16 的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存
取操作。
在 Node1 执行 set name kevin
1. 使用 CRC16 算法对 key 进行计算,得到一个数字,然后对数字进行取余。
CRC16 : name = 26384
26384%16384 = 10000
2. 查找到包含 10000 插槽的节点,比如是 node2,自动跳转到 node2
3. 在 node2 上执行 set name kevin 命令完成数据的插入
4. 如果在 node1 上执行 get name,先使用 CRC16 算法对 key 进行计算,在使用
16384 取余,得到插槽的下标,然后跳到拥有该插槽的 node2 中执行 get name 命令,并返回结果。
小编是一个有着5年工作经验的java'开发工程师,关于java'编程,自己有做材料的整合,一个完整的java编程学习路线,学习材料和工具,能够进我的群收取,免费送给**830783865**大家,希望你也能凭着自己的努力,成为下一个优秀的程序员。














 5788
5788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









