






架构设计的目标是为了解决目前或者未来软件系统由于复杂度可能带来的问题。就目前而言,架构设计主要是为了识别、梳理用例模型交互、功能模块实现、接口设计和概念模型设计等涉及到的复杂点,再针对这些复杂点制定处理方案,从而通过设计来增强效用、减少成本,降低复杂度。而就未来而言,系统架构设计将随着业务发展不断演变、完善,以解决未来软件系统由于复杂度可能带来的问题。
模块分析
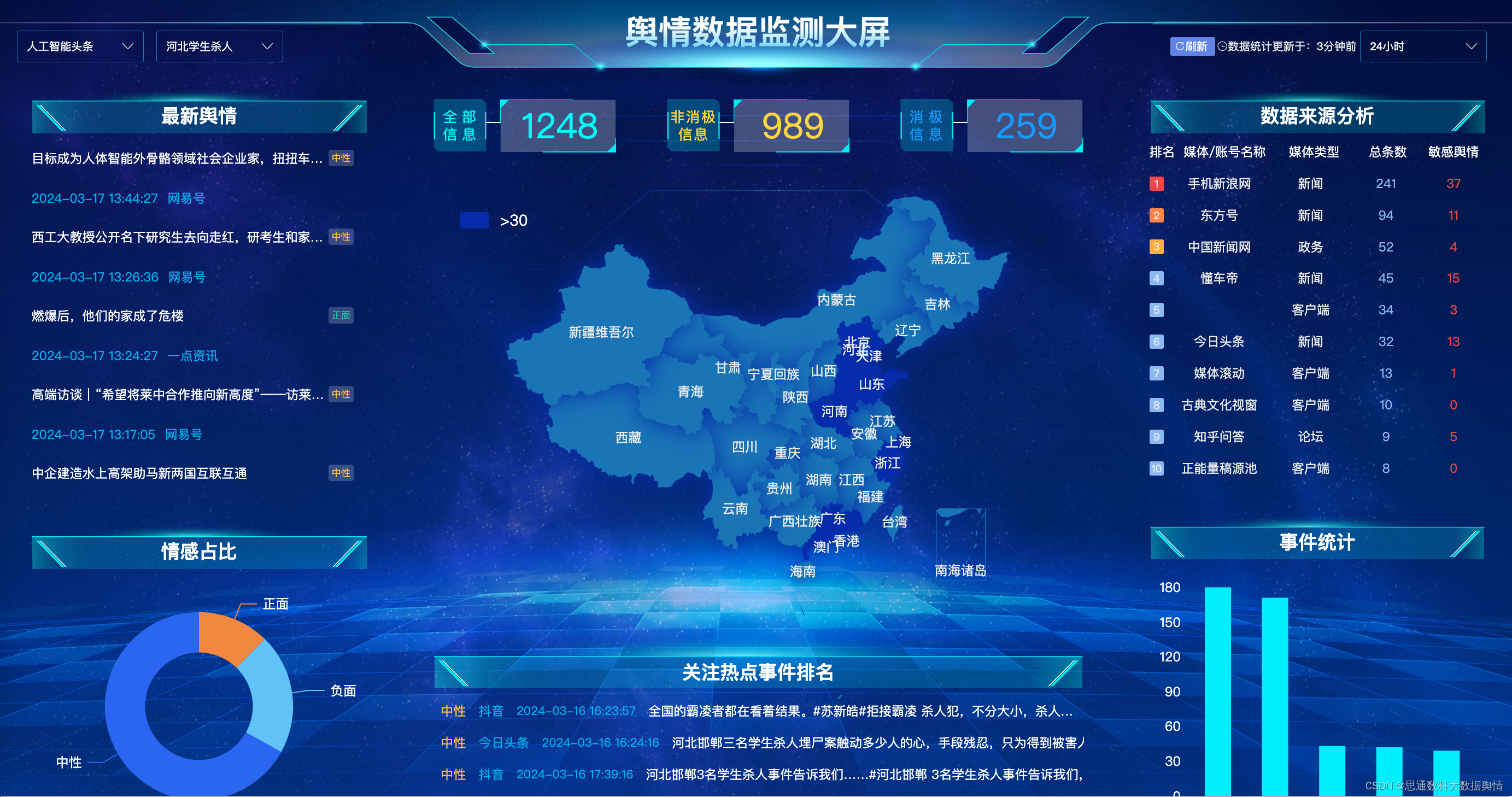
(1)数据采集
舆情系统中数据采集是本项目的关键构成部分,此部分功能的核心技术由爬虫技术框架构建。目前本项目的数据采集模块已经是一个“爬虫工厂”,这是一个低代码化开发的平台。更准确的说,我们不是在上面开发,而且在上面进行爬虫配置对数据采集抓取。
- 站点画像:采用模拟浏览器请求技术实现深度和广度抓取算法,对整个站点进行全站扫描、数据储存、特性分析。
- 自动抓取:有了网站的画像属性,就知道匹配那种采集抓取策略了,大部分网站就能自动抓取就自动识别抓取数据,无需人工干预。
- 人工配置:有的网站抓取难度大,采用可视化技术将整个站点的标签提取出来给开发工程师,他们将可以快速的对网站的抓取进行配置。我们在采集任何一个网站的时候将会有各种“探头”对网站的结构,广告位,关键性内容,导航栏,分页,列表,站点特性,站点数据量,抓取难易度,站点更新频率,等等。
- 采集模板:为了简化人工操作,提高工作效率,还提供了爬虫模板。爬虫模板的意义在于,用户遇到一个配置繁琐的站点,不用从头开始,只需要到爬虫模板库里面找类似的模板即可。
- 数据暂存:如果把数据直接储存到系统大数据库里,一旦有大量采集的脏数据下来就是浪费时间和精力,所有数据都会预演储存一遍,储存完成后会有程序对此核对监测,以免数据字段漏存、错存。
- 预警:如果在暂存环节发现储存错误,将会及时通过邮件发送对研发工程师提醒,告知错误内容,让其对此修正。

(2)数据处理
舆情系统的数据处理部分我们定义为:数据工厂。数据工厂是一套多组件化数据清洗加工及数据存储管理平台,同时能够管理所有的数据库的备份方案。支持多数据源类型的数据同步实现和数据仓库其他的数据源互通。对接收数据进行解压,对外提供压缩后的数据。
- 数据储存
- 数据标记
- 数据挖掘
(3)可视化数据分析
经过数据处理后,对客户需要的数据进行可视化展示,更加直观的了解舆情结果。
- 今日热点
- 检测分析
- 数据检测
- 监测管理
- 事件分析
(4)系统后端
对整个舆情检测系统进行管理,主要包括如下4个部分:
- 组织管理:可以创建一个企业或组织,在这个组织下可以创建多个舆情用户。
- 用户管理:在组织管理基础上可创建多个用户,每个用户可创建不同的方案,以及对多个不同用户的状态和密码管理。
- 方案管理:管理员可以对用户配置的方案进行管理,以及查看方案配置详情。
- 日志管理:管理员可以查看用户的登录次数以及用户具体操作了哪些功能菜单。
模块结构
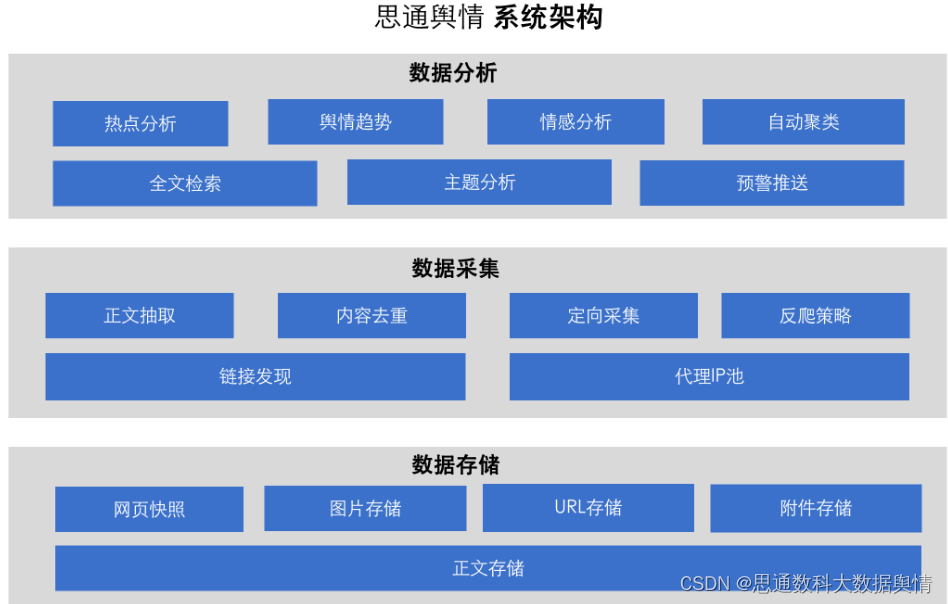
整个系统的功能架构图请看https://gitee.com/stonedtx/yuqing?_from=gitee_search,本文网络舆情数据分析和可视化系统是整个系统的一部分。

















 4010
4010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









