







为方便以后的学习,在此记下Linux内核笔记
希望大家能多多指正其中的错误,本人会悉心学习改正错误。
一. 进程的概念
二. 任务结构
三. 进程状态
四. 进程家族树
五. 进程创建
六. 进程结束
一. 进程的概念
进程是系统进行资源分配和调度的单位,通常是可执行程序代码、打开的文件、挂起的信号、数据、处理器状态等的合集。
对于Linux内核来说,一个进程也可以叫做一个Task,进程合集也就是进程列表(tasklist),是用一个节点为structtask_struct的双向循环链表实现的。
对于进程而言,进程总是会觉的自己在独享处理器和独享整个系统内存资源,这就是虚拟处理器和虚拟内存机制。
二. 任务结构
刚刚说过,内核用一个双向链表来存放任务列表,每一个节点是一个struct task_struct
这个结构体在32位机器上大约占空间1.7kb,包含了内核管理一个进程的全部信息,他大概是这个样子的:
struct task_struct
{//没有按照内核排列顺序
…
unsignedlong state; //定义当前进程的状态
…
structtask_struct *parent; //指向该进程的父进程
structlist_head children; //该进程子进程链表的头结点
…
pid_tpid; //进程描述符
…
void*stack; //进程内核栈指针
…
unsignedint flags; //进程标志,有固定取值
…
intprio; //进程调度优先级
unsigned long policy; //进程调度策略
…
}//没有按照内核排列顺序
这个结构体是在<linux/sched.h>中定义的。
进程通常有两种状态,内核态和用户态,进程通常在用户态下工作,当进程开始系统调用或者触发了某个异常则会陷入内核态,此时内核代表进程执行,进程所使用的栈空间是内核栈,也就是上述结构体中的stack指针。
在内核栈中,为了更加方便的找到当前进程的struct task_struct,在栈顶的位置(低地址)分配了一块空间存放下面这个struct thread_info:(定义在<asm/thread_info.h>)
structthread_info
{
struct task_struct *task;
…
…
…
}
那么存放该thread_info的内核栈又是怎么定义的呢:
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
}可以看到,这个内核栈是用一个共用体表示的,也就说内核栈的大小是固定的。而且,不会是thread_info的大小(因为thread_info其实只有几行大小)。到底是多大呢,我们看下下面那个定义为unsigned long的数组,不难发现这个数组的实际大小为:
THREAD_SIZE /sizeof(long) * sizeof(unsigned long) = THREAD_SIZE
也就是说内核栈的大小是固定的大小为THREAD_SIZE。通常为8192或者4096个字节。
看到这里应该还是一脸懵,我们用一张图来描述一下内核栈,thread_info和task_struct的关系:(图片来源互联网)
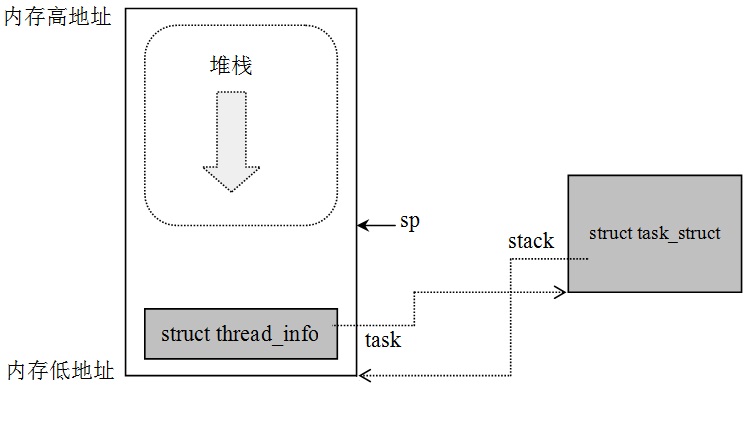
由图可知,threa_info可以找到task_struct,task_struct可以找到thread_info和栈。
因为内核中大部分处理进程的代码都是通过task_struct来完成的,所以找到task_struct的速度就显得尤为重要,这个过程通过current宏来实现。current先通过屏蔽栈指针的后13或者12位bit(对应8k和4k的栈)来实现算出thread_info地址的目的,再通过
current_thread_info()->task; 来找到当前task_struct的地址。
对于pid_t这个大家再熟悉不过了,其实就是一个int,为了与老版本兼容,PID的默认最大值位32768(short int最大值)。如果需要修改,可以通过修改/proc/sys/kernel/pid_max来提高最大值。
三. 进程状态
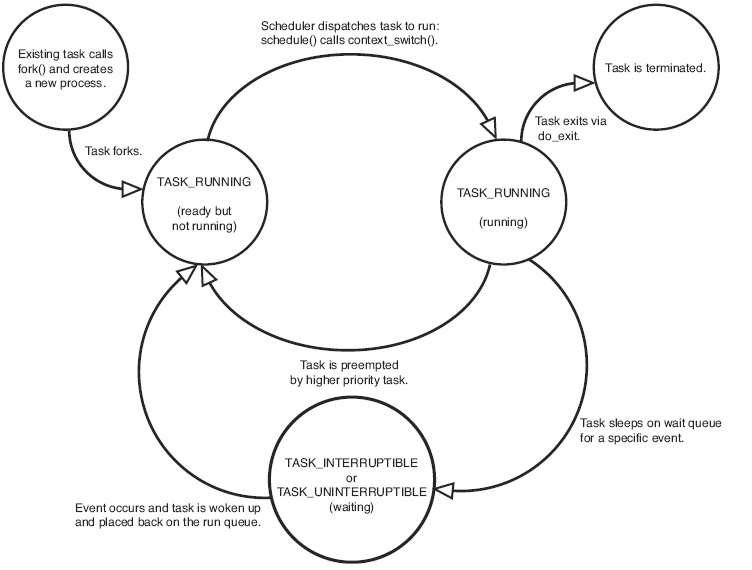
task_struct中的status描述了当前进程的状态,状态包括5种:
1. TASK_RUNNING(运行或者等待运行) :
这个是在用户空间执行的唯一可能状态,也可以运用到内核态中的进程。
2. TASK_INTERRUPTIBLE(睡眠或者等待条件达成) :
一旦条件达或者接收到信号成就会进入状态1。
3. TASK_UNINTERRUPTIBLE(不会因为信号或者条件达成唤醒) :
接收到信号或者条件达成也不会被唤醒,通常是必须等待时不受干扰出现,其他与状态2一致。
4. __TASK_TRACED(被跟踪调试) :
5. __TASK_STOPPED(停止) :
此状态不能投入运行,常是出现了SIGSTOP、SIGTSTP、SIGTTIN、SIGTTOU等信号时出现。
用一张图来描述一下几种状态间的切换:
四. 进程家族树
Linux中所有的进程都有继承关系,所有的进程都是PID为1的init进程的后代。并且每一个进程都必须有父进程。可以存在多个或者没有子进程,对于相同父进程的进程成为兄弟。list_head存放的就是一个进程所有的子进程,在这个链表中的进程都是兄弟关系。
访问一个进程的父进程:
struct task_stuct *my_parent = current->parent;
也可以通过以下代码遍历子进程链表:
CODE
structtask_struct *task;
struct list_head*list;
list_for_each(list,¤t->children)
{//这是一个宏定义函数
task = list_entry(list, structtask_struct, sibling);
//这也是一个宏定义函数
}
CODE从上述代码中我们看到用了两个宏定义,一个foreach与Java、C#中的foreach类似,提供一个迭代器,然后取sibling的容器也就是整个task_struct给list最后给到task身上。
听起来有点复杂,毕竟是宏定义的,不太直观。
init进程是系统启动由init_task静态分配的。
总之所有的进程就是一个以init为根节点的进程树。
最后提供一个遍历所有进程的宏例子:
structtask_struct *task;
for_each_progress(task)
{
… ;//task指向一个进程
}当然这个操作是相当累计算机的,所以不要轻易使用。
五. 进程创建
或许这个部分才是最重要的,但是前面的不知道的话并不能很好的去理解后面的内容。
Linux创建进程的方法可以分成两步:拷贝一个进程-->加载代码。
拷贝代码的系统调用大家也很熟悉了,就是fork()和vfork()。
但是不论是fork或是vfork甚至是pthread_create,都是调用clone来实现一个进程的拷贝的。
1. clone()
函数原型为
int clone(int(*fn)(void *), void *child_stack, int flags, void *arg);
第一个参数是执行代码的函数指针,第二个参数是栈空间的指针,第三个参数十几个标志位,第四个参数是传递过去的参数。
clone第三个参数可以传递一些位标志来指明需要共享的参数。其中主要参数如下:
CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子”
CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umask
CLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表
CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchy
CLONE_SIGHAND 子进程与父进程共享相同的信号处理(signalhandler)表
CLONE_PTRACE 若父进程被trace,子进程也被trace
CLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源
CLONE_VM 子进程与父进程运行于相同的内存空间
CLONE_PID 子进程在创建时PID与父进程一致
大概看一下,再结合我们之前所学习的fork和vfork或许能看出他们是怎么调用clone的了。
fork :SIGCHLD //同样的信号处理程序
vfork :SIGCHLD | CLONE_VFORK | CLONE_VM
//同样的信号处理,同样的地址空间
2. fork()
了解了clone之后,再来大致了解下fork的流程
clone()àdo_fork()àcopy_progress()à运行
这个函数最有意思的地方还是返回值:
两次返回,三种返回值:
分别返回给子进程和本进程,返回值可能是-1,0,和一个正整数,这一部分的内容比较基础就不在此记录了。
说道fork就不得不说写时拷贝技术了,大体上来说就是改变了传统的什么都拷贝的方案,毕竟很多情况下fork之后会立马执行exec()把执行代码全部换掉,如果什么都拷贝的话就实在是吃力不讨好了。所谓写时拷贝就是说fork之后不拷贝数据,而是以只读的方案分享数据,只有在发生数据更改的情况下才发生数据拷贝。这样做fork的实际开销只有一个描述符和父进程的页表,执行exec()后没有多做任何冤枉事,大大提高了进程的创建速度。
3. vfork()
所谓vfork就是变了形的fork,在clone阶段的区别已经说过了,这个区别就导致了数据使用的区别——vfork会共享数据。
另外一个重大的区别就是运行顺序,vfork创建的子进程的过程会让父进程阻塞,直到执行完mm_release()才唤醒父进程,也就说父进程要等到exit或者exec才能运行,这点在clone的属性里面也体现了。
看过很多地方都说尽量不要用vfork。因为一是fork的写时拷贝大幅降低系统开销,两者开销差别不大。二是vfork的子进程如果需求父进程的资源会导致死锁,或者子进程执行一个死循环父进程就无法执行。(这个地方不太确定,还需要深究)。
不论是fork还是vfork系统都会优先调用子进程,只不过,在fork的时候,系统还是经常去优先执行父进程,而vfork是确保子进程先执行的。
下面这段简单的代码可以去试下
int main()
{
intres = -1;
if((res= vfork()) == 0) //Change to fork()
{
while(1)
{
puts("child");
sleep(1);
}
}
elseif(res > 0)
{
while(1)
{
puts("parent");
sleep(1);
}
}
else
{
perror("forkerror :");
}
return0;
}
六. 进程结束
1. exit()
对于main函数来说,我们不写return0或者exit()都能成功推出,原因是编译器在结束后放置了exit()。
简单说下执行过程,简化下来就这么几步:
1). 释放内存空间
2). 退出IPC队列
3). 关闭所有的文件描述符
4). 重新寻找养父,并设置位ZOMBIE状态
5). 切换到其他进程
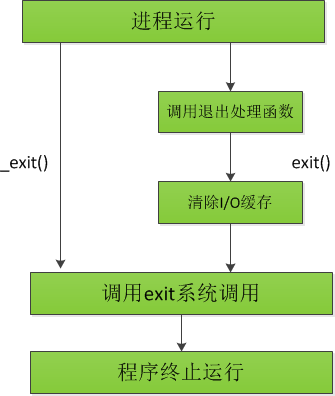
这里需要注意的是_exit()和exit()函数的区别:
简单点说最大的区别就是_exit()不去清理IO缓存,在使用vfork的时候需要格外注意这一点。(图片来源互联网)
2. wait()
从刚刚的过程可以清楚地看到,进程执行完后只是变成了ZOMBIE状态,所谓僵尸进程,就是指那些已经执行完不能再运行却还没有回收掉,保留了进程描述符的进程。所以说过多的僵尸进程会占用大量的内存空间,我们需要及时的回收掉僵尸进程。这个函数就是wait()。
它的主要工作如下:
1). 删除pid、删除任务列表中的任务
2). 释放剩余空间并统计记录
3). 检查进程组内是否还有进程,如果没有通知僵死的领头进程的父进程
4). 释放slab空间、释放页面资源、释放内核栈
3. 孤儿进程
对于无法找到父进程或者子进程未退出而父进程先退出的孤儿进程来说,它们执行完了就只能成为僵尸进程浪费资源。所以Linux提供了一种机制来为他们寻找父进程。
简单来说就是依次遍历进程组内其他进程,如果有就认它为父进程,如果没有,就返回init做为父进程。
七. Linux线程
对于Windows来说,线程与进程从本质上就不太一样,线程叫做是轻量级的进程,然而对于Linux这种已经非常轻量级的操作系统来说,线程本质上就是一种特殊的进程。
clone的选项告诉我们这一点,一个线程的创建方式往往如下:
CLONE_VM |CLONE_FS | CLONE_FILES | CLONE_SIGHAND
所以本质上,线程是一种共享地址空间,文件系统,文件描述符,信号处理程序的进程。
当然这并不影响我们按照原先的思维继续的去使用线程。
八. 总结
Linux管理进程的最主要的数据结构是struct task_struct的链表,它与内核栈有着重要的联系,并能通过内存栈中的thread_info也就是current宏查询到节点地址。
Linux中的进程拥有树状结构,可以通过这种结构找到父进程子进程和兄弟进程。
Linux中进程的创建主要通过fork和vfork,他们都是用过clone等系统调用实现的。
进程结束需要调用exit(),并在必要时刻使用_exit()。
进程结束需要使用wait来清除僵尸进程。防止造成孤儿进程。
Linux中的线程本质上就是进程。















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









