









最近工作中使用到了Hive, 并对Hive 的数据库,表完成创建。
创建的表为分区表,也涉及到了分区表 的按天动态增加分区。
代码组织结构:
创建数据库:
create_dmp.hql
-- dmp 数据库存储了dmp所需要的数据
CREATE DATABASE IF NOT EXISTS `dmp`
WITH DBPROPERTIES ( 'creator' = 'sunzhenhua', 'create_date' = '2018-06-07');执行创建命令
hive -f create_dmp.hql
创建表:
create_clearlog.hql
-- dmp_clearlog 存放了清洗过后的投放信息
-- 分区表: 按天分区
-- 外部表
USE dmp;
CREATE EXTERNAL TABLE IF NOT EXISTS `dmp_clearlog` (
`date_log` string COMMENT 'date in file',
`hour` int COMMENT 'hour',
`device_id` string COMMENT '(android) md5 imei / (ios) origin mac',
`imei_orgin` string COMMENT 'origin value of imei',
`mac_orgin` string COMMENT 'origin value of mac',
`mac_md5` string COMMENT 'mac after md5 encrypt',
`android_id` string COMMENT 'androidid',
`os` string COMMENT 'operating system',
`ip` string COMMENT 'remote real ip',
`app` string COMMENT 'appname' )
COMMENT 'cleared log of origin log'
PARTITIONED BY (
`date` date COMMENT 'date used by partition'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
TBLPROPERTIES ('creator'='szh', 'crate_time'='2018-06-07')
;在编写复杂创建表语句的时候着实遇到了很多问题,创建表的语句的书写格式是要遵循规范的。
具体的规范定义,参考我的博客:
https://blog.csdn.net/u010003835/article/details/80671367
这里我们编写了一个为 dmp.dmp_clearlog 动态增加分区的脚本:
脚本主要实现了以下几种功能:
1.对传入的日期参数进行校验 ,1)可以创建指定日期的分区,2)日期参数必须为yyyy-MM-dd格式
2.向hive执行传递参数
3.使用hive 新版的cli 工具,beeline执行 hql 文件 ,下面脚本包含了两种模式 hive-cli, beeline
延伸内容:
beeline 执行的详细讲解见我的另一篇博客
shell 中对字符串按指定分隔符进行划分的三种方法
shell 中正则表达式的应用
日期判断正则
date_pattern='^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$'
下面是我的脚本
load_hdfs_data_into_dmp_clearlog.sh
#! /bin/bash
set -o errexit
source /etc/profile
source ~/.bashrc
ROOT_PATH=$(dirname $(readlink -f $0))
echo $ROOT_PATH
date_pattern_old='^[0-9]{4}-[0-9]{1,2}-[0-9]{1,2}$'
date_pattern='^[0-9]{4}-((0([1-9]{1}))|(1[1|2]))-(([0-2]([0-9]{1}))|(3[0|1]))$'
#参数数量
argsnum=$#
#一些默认值
curDate=`date +%Y%m%d`
partitionDate=`date -d '-1 day' +%Y-%m-%d`
fileLocDate=`date -d '-1 day' +%Y-%m-%d`
#日志存放位置
logdir=load_hdfs_data_logs
function tips() {
echo "Usage : load_data_into_dmp_clearlog.sh [date]"
echo "Args :"
echo "date"
echo " date use this format yyyy-MM-dd , ex : 2018-06-02"
echo "============================================================"
echo "Example :"
echo " example1 : sh load_data_into_dmp_clearlog.sh"
echo " example2 : sh load_data_into_dmp_clearlog.sh 2018-06-02"
}
if [ $argsnum -eq 0 ] ; then
echo "No argument, use default value"
elif [ $argsnum -eq 1 ] ; then
echo "One argument, check date pattern"
arg1=$1
if ! [[ "$arg1" =~ $date_pattern ]] ; then
echo -e "\033[31m Please specify valid date in format like 2018-06-02"
echo -e "\033[0m"
tips
exit 1
fi
#echo $arg1 |tr "-" " "
dateArr=($(echo $arg1 |tr "-" " "))
echo "dateArr length is "${#dateArr[@]}
partitionDate=${dateArr[0]}-${dateArr[1]}-${dateArr[2]}
fileLocDate=${dateArr[0]}"-"${dateArr[1]}"-"${dateArr[2]}
else
echo -e "\033[31m Not valid num of arguments"
echo -e "\033[0m"
tips
exit 1
fi
if [ ! -d "$logdir" ]; then
mkdir -p $logdir
fi
echo ${partitionDate}
cd $ROOT_PATH
#nohup hive -hivevar p_date=${partitionDate} -hivevar f_date=${fileLocDate} -f hdfs_add_partition_dmp_clearlog.hql >> $logdir/load_${curDate}.log
nohup beeline -u jdbc:hive2://10.180.0.26:10000 -n cloudera-scm --color=true --silent=false --hivevar p_date=${partitionDate} --hivevar f_date=${fileLocDate} -f hdfs_add_partition_dmp_clearlog.hql >> $logdir/load_${curDate}.log
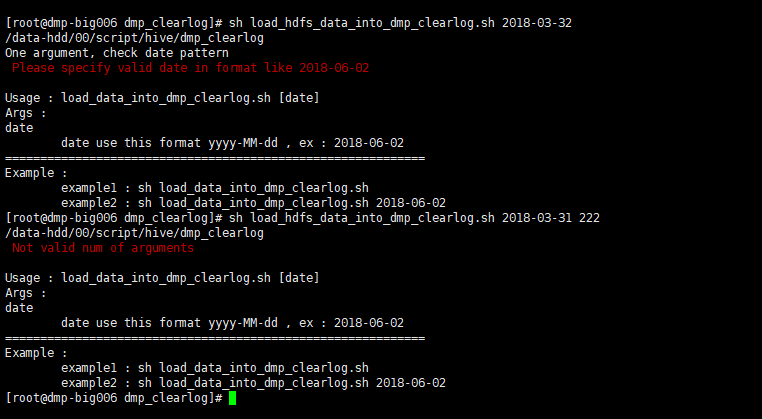
执行脚本示例: (参数校验)
最后动态增加分的脚本
USE dmp;
ALTER TABLE `dmp_clearlog` ADD IF NOT EXISTS PARTITION (`date`='${hivevar:p_date}') LOCATION 'hdfs://dmp-big001.a1.bj.jd:8020/bigdata/clearedLog/Device/${hivevar:f_date}';留一篇备份,方便以后完成类似的功能~

















 8120
8120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









