







HBase的基本概念和定位
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
选择合适的HBase版本
官网版本:http://archive.apache.org/dist/hbase/
CDH版本(稳定,推荐):http://archive.cloudera.com/cdh5/
HBase的用途
- 海量数据存储
- 准实时查询
HBase的应用场景及特点
- 交通
- 金融
- 电商
- 移动(电话信息)等
HBase的特点
- 容量大
HBase单表可以有上百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。
2. 面向列
HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。
- 多版本
HBase每一个列的数据存储有多个Version(version)。
- 稀疏性
为空的列并不占用存储空间,表可以设计的非常稀疏。
- 扩展性
底层依赖于HDFS
- 高可靠性
WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS,HDFS本身也有备份。
7.高性能
底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够达到毫秒级别。
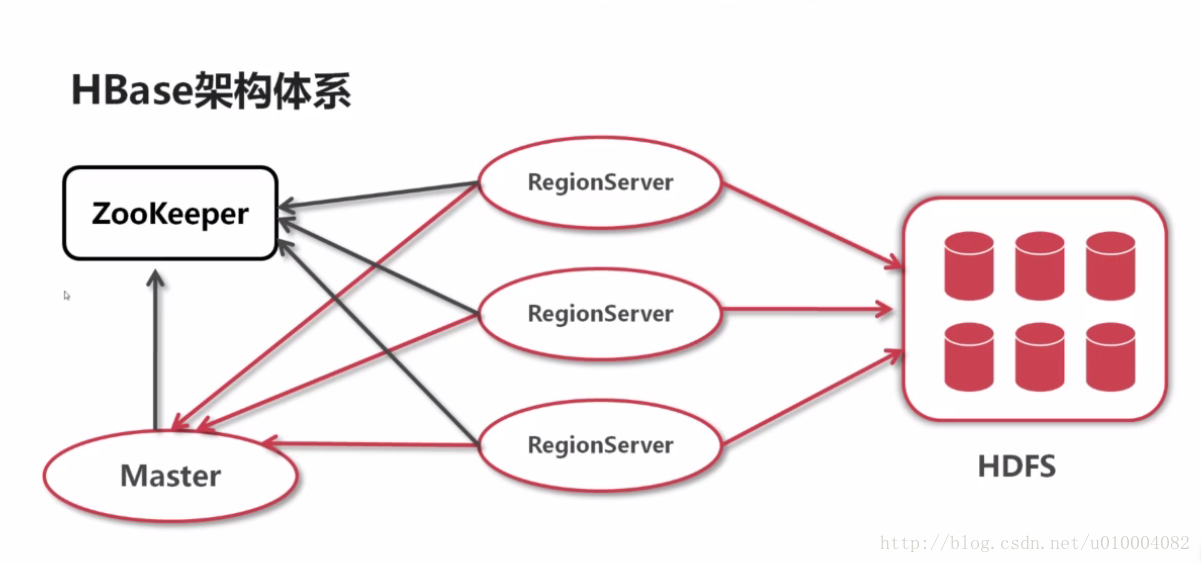
HBase架构体系与设计模型
HBase架构体系
HBase数据模型
- 一张表的列簇不会超过5个
- 每个列簇中的列数没有限制
HBase与关系型数据库表结构的对比
| HBase | 关系型数据库 |
|---|---|
| 列动态增加 | 列动态增加 |
| 数据自动切分 | 数据自动切分 |
| 高并发读写 | 高并发读写 |
| 不支持条件查询 | 复杂查询 |















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









