







Docker应该也属于交付之间的环节,最终交付之后还是要提供给应用,如何更好提供的服务,就需要去了解Docker不同的运行环境和运行状态。
利用率、内存使用率,以及整个对于网络的情况是什么样的,可以通过一些文件来获得状态信息。比如CPU的文件,以及用网卡做监控的时候怎么做网络的协同。下面有一个链接,有一些公开的脚本,可以拿这些脚本定期的去跑,这样就是说可以拿到Docker基础的状态。如果说Docker里面的服务出现了问题,提供的服务出现了问题怎么办?以往我们做这种状态获取的时候,获取这种状态有几种方案。
首先,我们处在一个注重用户体验的时代,随处都可见的是在讲体验,不管是我们PC页面,还是软件的体验,从用户体验的角度来讲,它所带来的概念是说围绕着这个用户的价值能不能够提供一个很友好的交付页面,很畅快的体验,这里面有几个东西可以衡量。
-
性能(响应时间/用户感知/独占时间)
最主要的是拿性能来体验,比如说从Web容器到应用容器,有一些排队时间,这个时间是说通过WebServer到APPServer,它最终所提供的服务是以应用服务器所提供的服务,这个之间一些转化规则,附载规则都可能会影响到应用的性能。我们刚才也讲到,微服务这种架构越来越流行,大家也慢慢的采用微服务的架构,服务会独立的部署,服务与服务之间的工序是不可避免的。从A服务到B服务的时间,B所产生的消耗对于A应用所带来的时间,也是一个衡量你整个应用体验的一个关键,我们称为External时间,可以基于HTTP、RPC、REST,除了这些还有更多的协议,我们跨平台的协议,包括国内有一些服务。 -
可用性(异常/错误)
除了性能还有一个比较关注的地方,如果你的服务出现了短暂的停顿,就要说到可用性。服务是不是出现了错误,页面是不是出现了异常,每个APP上出现了崩溃的信息。 -
流量(PV/UV/吞吐量)
Docker有一个特点是可以做扩容,其中依据是什么呢?流量的信息,不管是你PV、UV、吞吐量的信息,它有可能提供一个扩容的机制数据,提醒我知道流量到达了多少的时候该去扩容设备。 -
拓扑结构
拓扑结构是什么概念呢?不管是研发人员或者运营人员、技术人员,这种微服务上线之后服务关系变得越来越复杂,怎么能一目了然的知道为哪个服务提供服务,这个服务调动了多少次服务,逻辑上的拓扑结构也能够帮助我们定位问题,提供给我们扩容的一些基本数据。
除了刚才讲的CPU信息、内存信息,内存的利用率,包括整个服务领域的数量也会影响到服务的状态。
以往我们应用的来源是说有用户投诉了,到你的服务不可用了,然后客服部门会找到技术团队说你的技术不能用,这是一个应用状态来源。
另外一个是我们更多常规的采用应用的日志,会对技术做一些汇集,把各种应用状态分析出来。但是微服务的架构下,在当前的容器下应用的日志会越来越多,每一个Docker容器会产生一到多个日志文件,我们怎么样把这个文件更好的结合在一起,怎么把应用的关系串联起来,其实是有一定的难度。就算能够将这些信息串联起来,也有可能会碰到比如说这是突发性的故障,我们根本以前没有遇到过,或者偶尔几个月才能遇到一次,这个错误出来之后不能得知原因,也不知道它到底代表什么,可能去找研发人员之后一步一步的去尝试,难道没有一个更好的方式吗?
随着技术的发展,APM技术能够帮我们做一些事情。APM其实有两个含义,我们更多的理解它是一个管理,为什么是管理?应用的状态不是一个点,也不是一个时间段的问题,它是一整个软件生命周期的问题,所以对于应用性能的是软件周期中的一个关键点。
这是一张拓扑图
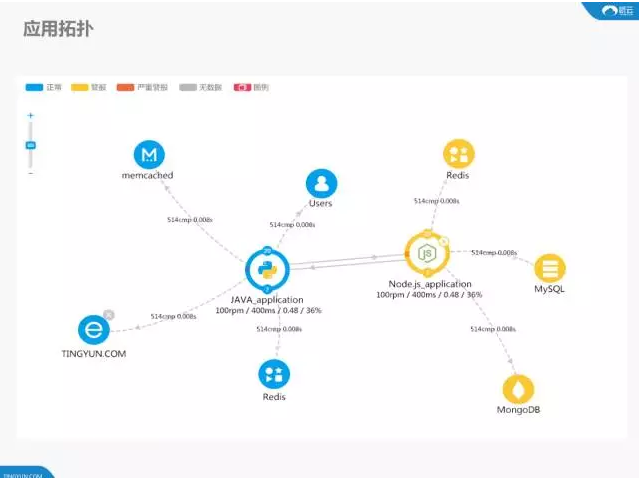
用户所能体现的,对应用的直观感受是什么样的?它所获取到的时间是什么样的?以入口服务为主,这个入口服务调用了哪些服务?这个下面调用了数据库的服务,在这个服务上访问了一些其他网站。根据业务关系可能会更加复杂,每一个服务上面是什么样的?会通过一定的基准值表现出来,是因为某一个服务出现了问题导致整个服务有问题,这是一个应用的逻辑,它能够告诉你当前应用下你所部署的关系,以及应用和应用之间的关系。
下图可以看到其中一个应用,它在一个打分的情况下出现了54分。
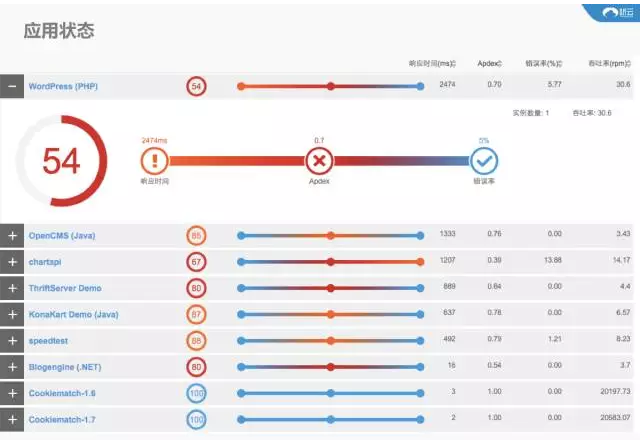
由于应用的响应时间超过了2秒,这时会出现一些用户体验的问题,用户投诉也会随之而来。如果能在用户投诉来之前就解决这个问题是现在互联网企业比较关心的问题。根据这个图来可以了解到应用出现了哪些问题,响应时间超过了2秒,而这2秒花在哪个地方呢?我们通过另外一个图
可以看到这个2.5秒绝大部分花在应用层时间,此外还有APP服务的时间,这个外部服务时间是它调动了其他的服务出现的问题。其实这个时间还不能明确的表现出到底是应用层还是哪段代码出现了问题。
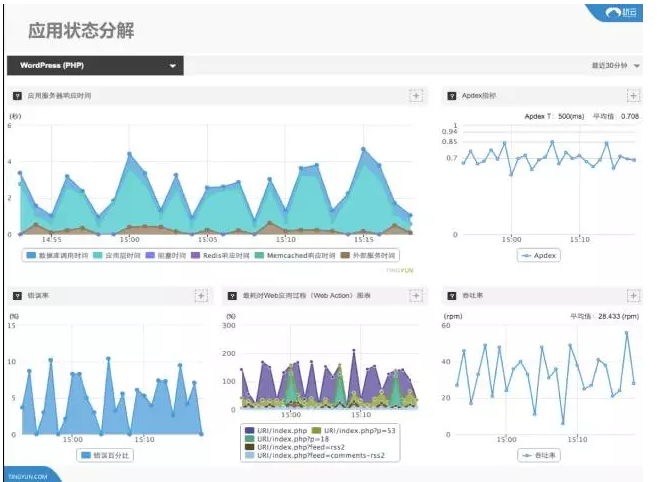
再一步一步的往下看,能够看到错误率达到了5%,高的时候可能超过了10%,如果你有100个用户,其中有10个用户受到了影响,他访问服务的时候已经出现了中断。接下来要单独的去分析到底是什么导致了问题。
对于这个应用来讲能够看到是应用代码和外部服务时间出现了问题,到底能不能了解到在这个应用下有哪些服务出现了问题,图中可以看到这个服务调动了很多包括调用了OpenCMS以及这条线上会有OpenCMS享受的服务,OpenCMS调用了另外一个服务。这里面包括每一个服务对于吞吐率、错误率等等的指标,由此就能得知到底是本身的业务出现的问题,还是因为调用了其他的服务出现的问题。
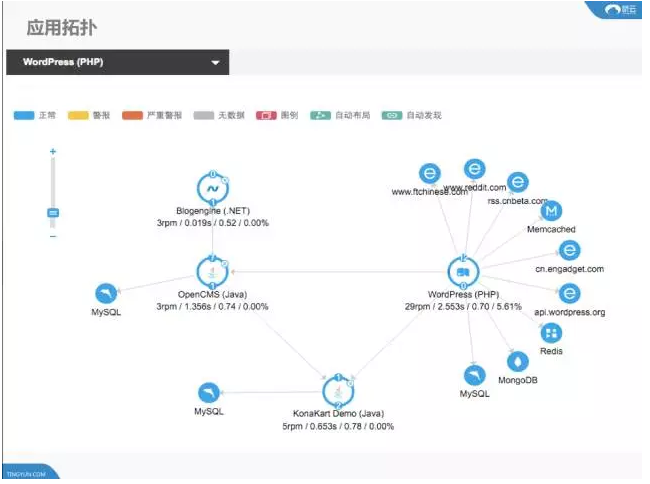
在这个应用里面其中的几个服务是最慢的,拿其中的一个来分析:
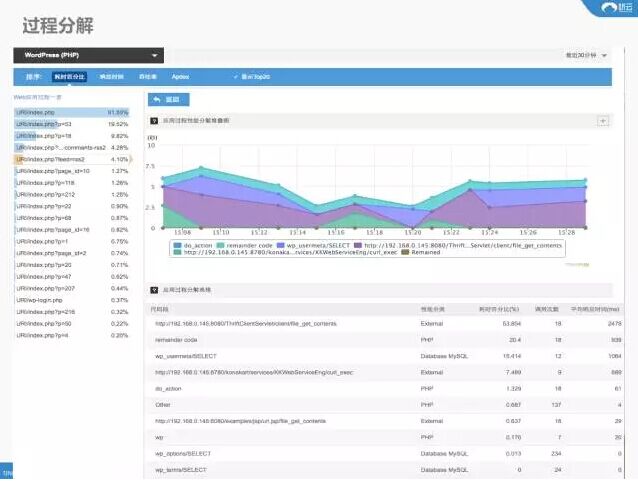
这个叫RSS2的服务,URL对应的服务是什么,可能是和本身业务相关的,而能不能知道在这个服务中它到底调用了哪些代码?整个调用链里面出现了哪些有可能产生性能的问题呢?除了能看到这个服务的调用所占比达到了50%以上以及对数据库的访问也占了15%的情况之外,也可以从单一用户场景下出现的问题分析。
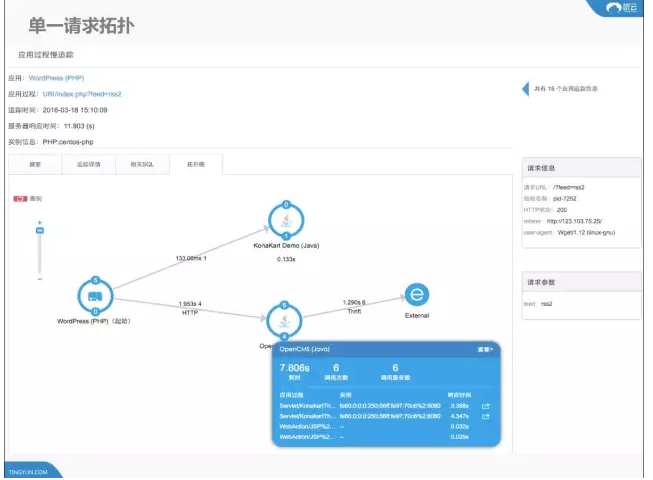
上图能看到这一次请求里面,在SPP这个服务里面消耗的时间是11秒,这11秒的时间通过这个拓扑图来看调用的这个应用所消耗的是133毫秒,OpenCMS消耗的应用在四个时间里面平均是1.9秒,总共消耗了7秒,在11秒里面有7.8秒是因为OpenCMS效应过慢导致了对外服务的应用出现了缓慢的问题。再去看OpenCMS,总共调用了四次的OpenCMS,OpenCMS对应的是哪些服务?它这个服务到底发生在哪个虚拟的环境下面?这个虚拟的环境下所产生的是什么样的?是因为OpenCMS的问题,导致我整个服务出现了问题。
整个供应链里面,因为其中一个函数调用了OpenCMS的URL,对应OpenCMS应用的实例是这台主机,我们能得知在这台容器里面它发生的时间主要是在外部服务,也就是说OpenCMS在这4秒里面所消耗的时间,绝大部分是发生在外部服务里,通过一步步的钻取,可以看到在当时的场景下调用了这个服务,这4秒花在了什么地方。
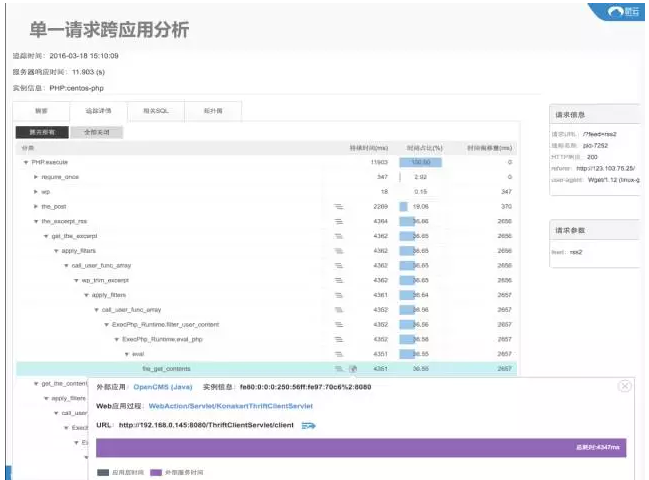
接下来到了OpenCMS的应用,也在这个时间点看到了对应的请求类别,在这里面我们可以看到当时是因为它调用了这个里面的服务所产生了问题,原因是方法在文件的127行调用的服务。从以上的这两个图来看,我们既可以知道是因为什么样的服务出现了问题,也可以告知是因为哪一行代码调用了这个所产生的问题。
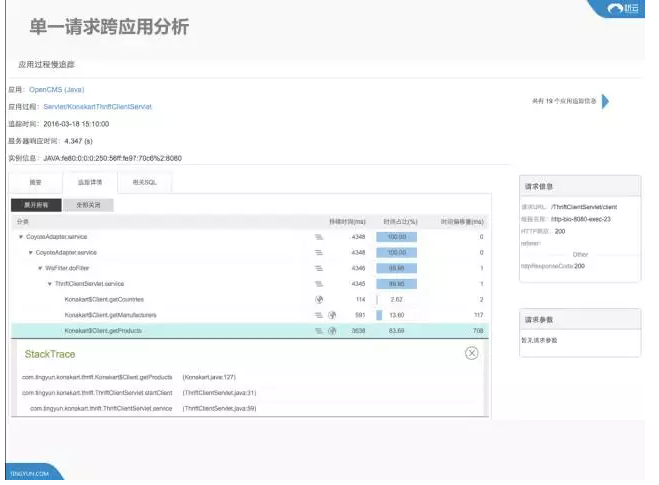
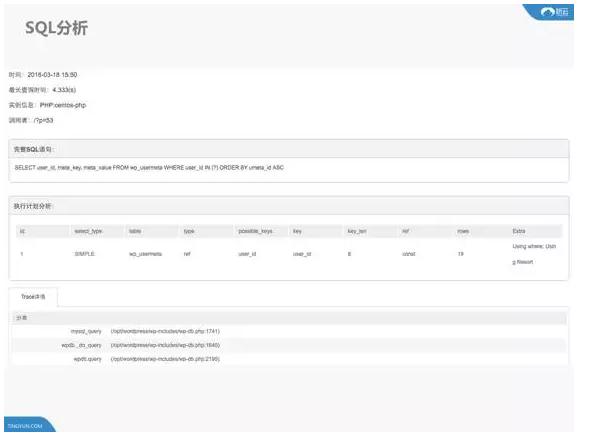
由刚才的图可以看到在这个时间点里面有一次调用所执行的是这个SQL,这个SQL在当时的执行计划是什么样的,是因为单表数据量过大而导致了数据库的反应过慢还是其他原因,有了这个信息就可以提供一些优化依据来提升我们的的质量。
刚才有大约10%的用户受到了服务的影响,这10%当时是不可用的,这些不可用的情况下到底发生了什么样的错误?也许会看到绝大部分是因为404,也有一些情况是因为编辑的问题,以往这些问题只能通过点去查,或者是没有日志出错的情况下很难定位这个问题。当一步一步看这个错误的时候,可以看到错误详情以及当时的调用情况,请求信息所带来的是什么样的,包括出现问题的代码和数据,这样就可以快速的告诉研发哪段代码出现了问题赶紧修改,立马上线,就免于其他更复杂的服务,对10%的用户可以看到正常的服务。
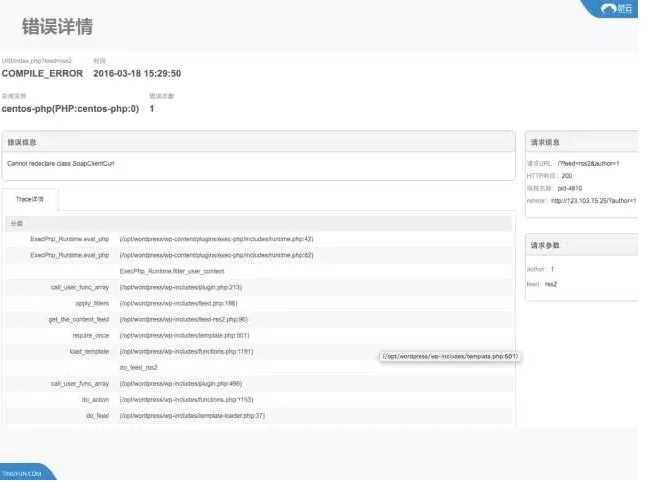
通过以上,可以看到APM的技术能够帮助我们快速的了解应用状态,根据这些应用状态以及其他信息来获取依据,作为去调整服务的依据。















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









