







Storm工作原理:
 Storm 编程模型
Storm 编程模型
Storm是一个开源的分布式实时计算系统,常被称为流式计算框架。什么是流式计算呢?通俗来讲,流式计算顾名思义:数据流源源不断的来,一边来,一边计算结果,再进入下一个流。例如一般金融系统一直不断的运行,金融交易、用户所有行为都记录进日志里,日志分析出网站运维、猎户信息;海量数据使得单节点处理不过来,所以就用到分布式计算机型,storm 是其中的典型代表之一,一般应用场景是:中间使用一个消息队列系统如kafka,先将消息缓存起来,storm 中有很多的节点,分布式并行运行处理程序,进行数据处理。
只要不是人为干预,storm 就一直实时不断地进行数据处理。值得注意的是:并不是storm去处理,而是它可以将我们程序的很多jar包,业务程序,同时放到不同的服务器中并发的运行, 最终得到的结果就是不同系统的海量数据就会分散到不同的服务器中并发的进行处理,负载能力很强。 所以真正进行数据处理的是我们写好的数据处理程序,storm的强大作用之一就是它为这些程序提供了运行温床,将应用程序上传到storm 集群中,在多台机器上并发运行,这样就可以扩展程序的负载处理能力,实现流式计算。
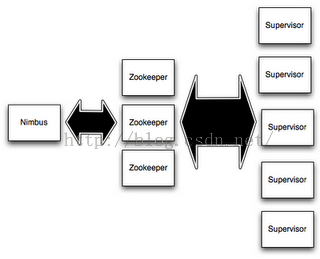
Storm 集群组件:
集群角色:
Nimbus:集群主节点,主要负责任务分配、响应客户端提交topology请求以及任务失败的调度
Supervisor:集群从节点,主要负责启动、停止业务逻辑组件程序进程
主从节点之间通过zookeeper集群进行连接,主从节点之间是fail-fast(java的一种错误机制)、无状态的,主从节点的状态信息均保存到zookeeper中或者本地硬盘里。这样的好处就在于,哪怕是主节点kill掉了,storm会自动起一个备份主节点,因为无状态的关系,所以任意一个节点都可以充当Nimbus一角。这种设计使得storm十分稳定。【译自apache storm官网】
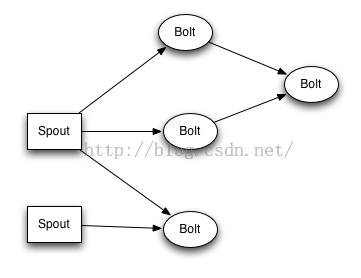
Topology
业务处理模型
Spout
数据源组件,用于获取数据,可通过文件或者消息队列【kafka、activeMQ】中获取数据
Bolt
逻辑处理组件
简单理解,topology【拓扑结构】就是包含了数据源、逻辑处理组件的一个外在集合框架,使用storm可以定义一个topology里set多少个数据源组件,多少个逻辑处理组件。下面通过demo来具体解释Storm编程模型的几个主要元组
例如现在需要对一组数据进行处理,将数据中所有的英文转成大写,再加上标识后缀,最后保存到本地文本中,当然这只是一个特别简单的数据处理逻辑,仅用于帮助大家理解Storm编程模型。 那根据Storm的编程模型,实现这个数据处理需求需要建立1个数据源Spout组件,2个业务逻辑组件Bolt,以及一个Topology结构,将这3个组件加入到这个topology结构中.
[Java]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
public
class
RandomSpout
extends
BaseRichSpout{
SpoutOutputCollector collector=
null
;
String[] goods={
"iphone"
,
"xiaomi"
,
"meizu"
,
"zhongxing"
,
"huawei"
,
"moto"
,
"sumsung"
,
"simens"
};
/*
* 获取消息并发送给下一个组件的方法,会被storm 不断地调用
* 从goods 数组中随机获取一个商品名封装到tuple中去
*/
@Override
public void nextTuple() {
Random random=new Random();
String good=goods[random.nextInt(goods.length)];
//封装到tuple中发送给下一个组件
collector.emit(new Values(good));
}
//进行初始化,只在开始时调用一次
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
/*
* 定义tunple的schema
*
*/
@Override
public
void
declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(
new
Fields(
"src_word"
));
}
}
|
数据源Spout组件通过继承Storm基类,重写三个最核心的方法,分别是open、nextTuple、和delcare方法;open是在将执行数据传递之前所执行的方法,用于初始化数据;nextTuple中核心方法就是collector的emit方法,用于将数据传递给下一个元组。delcare用于成名元组传递、接收数据的格式,可以简单的理解为给传递的数据加上一个标识键。
[Java]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public
class
UpperBolt
extends
BaseBasicBolt {
//每来一个消息元组tuple,都会被执行一次该方法
@Override
public
void
execute(Tuple tuple,BasicOutputCollector collector) {
//从tuple 中拿到数据--原始商品名
String src_word=tuple.getString(
0
);
//获取下标第一个消息
String upper=src_word.toUpperCase();
//发送出去
collector.emit(
new
Values(upper));
}
//给消息申明一个字段名
@Override
public
void
declareOutputFields(OutputFieldsDeclarer declare) {
declare.declare(
new
Fields(
"upper"
));
}
}
|
这个逻辑处理bolt 用于将spout数据源组件中传递的元组转成大写格式,先获取tuple的数据,然后emit发送给下一个元组。
[Java]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
/*
* 给商品名称添加后缀,然后写入文件中
*/
public
class
SuffixBolt
extends
BaseBasicBolt{
FileWriter file =
null
;
@Override
public
void
prepare(Map stormConf, TopologyContext context) {
try
{
}
catch
(IOException e) {
e.printStackTrace();
}
}
//每一次执行都去new 一个writer ,应该在调用excute 之前先把writer 初始化好==持续运行
@Override
public
void
execute(Tuple tuple, BasicOutputCollector collector) {
//从消息元组中拿到上一个组件发送过来的数据
String upper=tuple.getString(
0
);
String result=upper +
"_suffix"
;
try
{
file.append(result);
file.append(
"/n"
);
}
catch
(IOException e) {
e.printStackTrace();
}
}
//声明该组件要发送出去的tuple的字段定义
@Override
public
void
declareOutputFields(OutputFieldsDeclarer declare) {
}
}
|
bolt和spout一样,继承storm基类之后,也会有prepare方法用于准备数据,初始化一些对象;excute方法则是每每传递过来一个元组,便会触发执行一次,这个bolt的作用在于将上一个元组传递过来的数据加上后缀处理,然后写入本地文件中。
那么,写好了这些基础的数据源和业务逻辑处理元组,如何组织他们的数据传递关系,这就是Topology类的职责。
[Java]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
/*
* 描述topology的结构,以及创建topology并提交给集群
*/
public
class
TopoMain {
public
static
void
main(String[] args)
throws
AlreadyAliveException, InvalidTopologyException {
TopologyBuilder builder=
new
TopologyBuilder();
//设置消息源组件 4表示spout进程个数
builder.setSpout(
"randomSpout"
,
new
RandomSpout(),
4
);
//设置逻辑处理组件
//shuffleGrouping 指定接收哪个组件传过来的消息
builder.setBolt(
"upper"
,
new
UpperBolt(),
4
).shuffleGrouping(
"randomSpout"
);
builder.setBolt(
"result"
,
new
SuffixBolt(),
4
).shuffleGrouping(
"upper"
);
//创建一个topology
StormTopology topology=builder.createTopology();
Config config=
new
Config();
config.setNumWorkers(
4
);
//设置进程个数
config.setDebug(
true
);
//设置调试状态
config.setNumAckers(
0
);
//消息应答器,事务性不是很强,可设置为0
//提交topology到storm 定义一个名称,好在集群里去标识;通过配置对象传递参数给集群,集群根据这些参数,任务调度进行调整
StormSubmitter.submitTopology(
"demotopo"
, config, topology);
}
}
|
Topology类便将之前编写的1个spout 和2个bolt组装到一个topology中,并通过追加shuffleGrouping方法设置了他们之间的数据传递方向,以及进程个数。
通过这个实例应该对storm的编程模型和编码流程有了简单的认识。但这只是storm的大山一小角,例如zookeeper对storm集群主从节点的管理、storm与消息中间件的结合处理海量数据,复杂的数据处理流程,这些才是storm真正大展身手的地方。














 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









