







为什么是Java SE 5?
目前已经到了JDK-8u74了,JDK7的主版本已经于2015年4月停止公开更新。
那为什么还要来说Java/JDK5呢?
Java SE在1.4(2002)趋于成熟,随着越来越多应用于开发企业应用,许多框架诞生于这个时期或走向成熟。
Java SE 5.0的发布(2004)在语法层面增加了很多特性,让开发更高效,代码更整洁。
- 自动装箱/拆箱、泛型、注解、for循环增强、枚举、可变参数等新特性让你的小手指少敲了不少代码,可以写更优雅的实现;
- API提供并发库大大减少并发编程的难度;
- 虚拟机层面改进了内存模型,增加虚拟机监控和管理相关的api和工具等等。
但是,语法层面的改变对应于JVM却没有多大变化,只是编译器在编译字节码时偷偷做了手脚。
所以我们应该了解下到底编译器干了啥坏事,有助于写更合理的代码,少踩坑,掉陷阱里也得知道怎么掉的。
另外原因,目前从各种各样的项目代码看,其实多数开发人员常用的还是Java SE 5.0 的特性,甚至习惯用Java SE 1.4及以前的语法特性。
学java也有几年了,许多特性也知道个一二,但是要写下来,还是得查阅不少文章,很多东西欠缺完整性和系统性。
码农写文章(更合理说是整理资料)也是一个学习的过程。
学习一门语言,一旦实际应用于实际开发中,了解背后的原理和理念,深入了解语言的特点,有好处没坏处。
注:javac XXXXX.java 编译命令
javap -c XXXXX 反编译命令
-c 反编译
-s 输出内部类型签名 需要看方法签名时 要加上这个参数
-v 输出附加信息 会输出比较多信息 包括常量表 line number table 等信息, 但没有-s的输出内容
一、自动装箱/拆箱
1、包装类型(存在于Java 1.5之前)
Java中,类型分成两大类,基本类型(Primitive Type)和引用类型(Reference Type)。基本类型是内定的,有确定的取值范围,值占有确定的内存空间。
有八大基本类型,分成两个浮点类型(float、double),五个整型(byte, short, int, long,char), 一个布尔型(boolean)。
没看错char也是整型,在语言规范中说明,char是一个16bit无符号整形,用来表示一个UTF-16编码的单元(在Java5中对应Unicode4.0,Java8中对应Unicode6.2)。
基本类型的值不是对象,最基本的对象(Object)方法(toString, hashCode, getClass, equals等)也不能调用。
为了把基本类型当引用类型来用,具备对象的特质,JDK中定义了各种基本类型相对应的包装类。
所谓装箱,就是将基本类型的值包装成(转换-conversion)对应的包装类型的对象,拆箱,就是讲包装类型的对象,转换成基本类型的值。
装箱和拆箱:
Integer i = 100;
int j = new Integer(250);| 基本类型 | 大小 | 数值范围 | 包装类型 | 默认值 |
|---|---|---|---|---|
| boolean | true, false | Boolean | false | |
| byte | 1字节(8bit) | -2^7 – 2^7-1 | Byte | 0 |
| char | 2字节(16bit) | \u0000–\uffff | Character | \u0000 |
| short | 2字节(16bit) | -2^15 – 2^15-1 | Short | 0 |
| int | 4字节(32bit) | -2^31 – 2^31-1 | Integer | 0 |
| long | 8字节(64bit) | -2^63 – 2^63-1 | Long | 0 |
| float | 4字节(32bit) | IEEE754 | Float | 0.0f |
| double | 8字节(64bit) | IEEE754 | Double | 0.0d |
2、自动装箱/拆箱背后
前面说了,语法特性的改变并没改变JVM的实现方式,那么我们可以看看背后编译器到底干了啥事情。
下面代码和编译后的反编译结果:
public void boxUnBox(){
Integer i = 100;
int j = new Integer(250);
}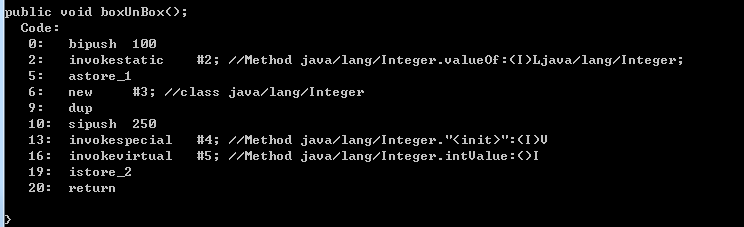
反编译结果可以看到,以上代码实际等同于以下代码的编译结果:
public void boxUnBox(){
Integer i = Integer. valueOf(100);
Integer t = new Integer(250);
int j = t .intValue();
}
八大基本类型的装箱操作都调用的是valueOf方法,拆箱操作调用各自赌赢的xxxValue()方法,有兴趣可以试试。
3、注意==比较的陷阱
在java中,计算类型的运算符,
先来看下比较的代码编译结果:
public void boxUnBoxCMP(){
Integer i = 100;
int j = new Integer(250);
if(j == i ){}
Integer h = new Integer(100);
Integer k = new Integer(100);
if(h == k ){}
}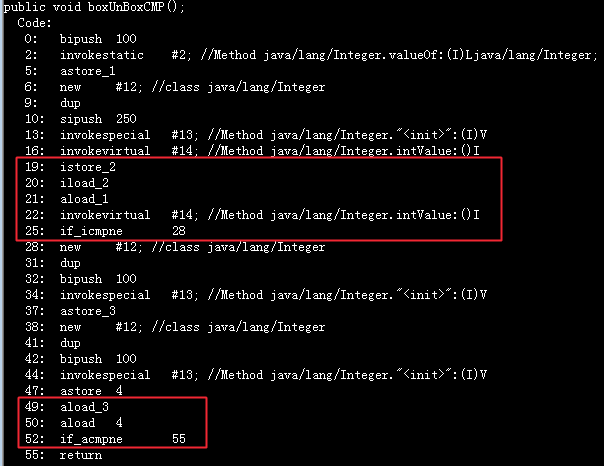
==第一个红框==是if(j == i ) 的反编译代码
从上面的反编译结果可以看出,包装类型的单目运算符计算其实是需要通过拆箱=>计算=>装箱实现的,
而双目运算符的运算也是需要将包装类型转换成基本类型,然后再参与运算。
但是,== 的比较要牢记它的本质,如果==比较两边都是引用类型,那么比较的是引用地址,如果其中一边是基本类型,那么非引用类型的值将转换成基本类型再做比较。
==第二个红框==中是引用比较,没有转换。
4、Cache带来的坑
我们看看自动装箱的valueOf的代码吧
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache. high)
return IntegerCache.cache[i + (-IntegerCache. low)];
return new Integer(i);
}
一眼就可以看到IntegerCache这个玩意,完整代码(JDK1.8的代码)如下:
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
// 根据配置获取缓存最大值,最大值配置范围 127 < h < Integer.MAX_VALUE-129
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt( integerCacheHighPropValue);
i = Math. max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math. min(i, Integer.MAX_VALUE - (- low) -1);
} catch( NumberFormatException nfe ) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h ;
cache = new Integer[(high - low) + 1];// 也许有人会疑惑为什么会有个+1,其实就是0这个数占了个坑
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k ] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache. high >= 127;
}
private IntegerCache() {}
}
IntegerCache的意思就是将low到high的值先缓存起来,low恒定是-128, high默认是127,可以配置成127<= high <= Interger.MAX_VALUE-129
注意缓存的是Integer对象,所以是引用对象。既然是引用对象,那么==的比较就会有问题了。
public static void trap(){
Integer i = 100;
Integer k = 100;
if(i == k ){System.out.println( "i == k");}
Integer j = 500;
Integer h = 500;
if(j == h ){System.out.println( "j == h");}else { System.out.println("j != h" );}
}
输出结果是什么呢?
i == k
j != h
因为i和k都是从IntegerCache中取得的缓存对象,引用是一样的,j和h没有缓存,必须valueOf必须重新new一个Integer对象,所以引用是不等的。
类型Byte、Short、Long和Integer类似,只是没有可配置的最大缓存值,Byte所有值都被缓存了,所以不存在==的坑。
Character缓存的是0~127。
Float和Double没有缓冲,也没办法缓存。
5、建议
- 不会参与运算的用包装, 比如数据库自增的记录ID,用Long类型
- 参与运算的,如果计算复杂,尽量先转成基本类型,计算后再转回对应的包装类对象;特别是频繁的单目运算符,如循环中的自增自减
- 参与比较,注意包装类的cache坑
- 记得所有集合中只能存对象类型,基本类型都是经过装箱/拆箱的
举个不好的例子吧:
public static Long bad(List<Integer> list){
Long sum = 0L;
for(Integer i : list ){
if(i % 2 == 0 ){
sum += i;
} else {
sum += i * 2;
}
}
return sum ;
}
有兴趣的童鞋可以反编译看下,类似于以下代码完成的事情:
public static Long badOrigin(List<Integer> list){
Long sum = Long. valueOf(0L);
Iterator<Integer> it = list.iterator();
Integer value = null;
long sumTmp = 0L;
while(it .hasNext()){
value = it.next();
if(value .intValue() % 2 == 0){
sumTmp = sum.longValue();
sumTmp = sumTmp+ value.intValue();
sum = Long. valueOf(sumTmp);
} else {
sumTmp = sum.longValue();
sumTmp = sumTmp+ value.intValue()*2;
sum = Long. valueOf(sumTmp);
}
}
return sum ;
}
按照建议来,可以改成以下代码:
public static Long good(List <Integer> list ){
long sum = 0L;
int value = 0;
for(Integer i : list ){
value = i.intValue();
if(value % 2 == 0 ){
sum += value;
} else {
sum += value * 2;
}
}
return sum ;
}
以上反编译下看看字节码,是不是清爽多了^^
二、for循环增强
for循环增强也是1.5里的一个语法糖,让大家写for循环更加便利,再加上IDE的代码模板,非常方便
1、先看看List的for循环增强怎么写:
public void iteratorForeach(){
List<String> list = new ArrayList<String>();
for (String str : list ) {
}
}
反编译结果如下,可以看出,其实就是调用Iterable接口的iterator方法,获得一个迭代器(Iterator), 利用迭代器进行遍历所有数据。
从这里也可以推出,只要实现Iterable接口的类型,都可以在for循环增强中使用:

比如自己实现一个只有add方法,只能通过iterator遍历的List:
public void myListForeach(){
MyList<String> myList = new MyList<>();
for (String str : myList ) {
}
}
public static class MyList<V> implements Iterable<V>{
private List<V> datas = new ArrayList<>();
public void add(V data ){
datas.add( data);
}
@Override
public Iterator<V> iterator() {
final Iterator<V> it = datas .iterator();
return new Iterator<V>() {
@Override
public boolean hasNext() {
return it .hasNext();
}
@Override
public V next() {
return it .next();
}
};
}
}2、再看看数组类型的for循环增强怎么写:
public void arrayForeach(){
String[] strs = new String[10];
for (String str : strs ) {
}
System. out.println();
String str = null ;
for(int i = 0; i < strs .length ; i ++){ //传统for循环写法
str = strs[ i];
}
}跟传统for循环相比,数组的for增强循环更加简洁,从反编译代码中也可以看出,用到的指令序列基本上是一样的。

3、不适应的地方
这么好的东西什么情况下用不了呢? 主要是for增强循环中没能得到下标也没能得到iterator对象引用导致的。
第一种是数组或者List集合类型,需要用到下标的情况;
第二种是需要调用到Iterator接口的remove方法的情况;
三、可变参数
Java SE 5.0中增加了可变参数特性,对于以往用数组表示的参数可以调整到最后一个参数,作为可变参数定义,
调用方省去显示创建数组,可空数组可以直接可以省略:
public static void varargs(String s, String... ss) {
}
public static void main(String[] args) {
varargs("aaa" );
varargs("aaa" , "bbb" );
varargs("aaa" , "bbb" , "ccc" , "ddd" );
varargs("", null) ;
varargs("aaa" , new String[]{"abc", "ccc", "ddd" });
}
可变参数背后编译器也是创建一个数组来传递参数的,可以方编译以上代码, varargs的方法签名中第二个参数就是一个string数组:
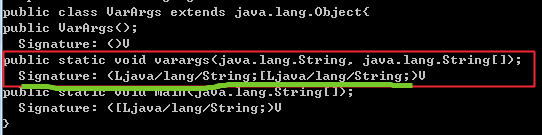
==注意事项:==
- 不能有多个可变参数,并且只能是最后一个参数;
- 因为可变参数是由数组实现的,调用方忽略可变参数时,可变参数为空数组;但是既然是数组,就可以设置成null,所以要注意空判断;
- 如果被调用的方法,既匹配了可变参数方法,有匹配了固定参数方法,固定参数方法将被调用;
- 尽量避免可变参数方法的重载(overload):
- 可变参数类型与前一个参数的类型一样时,与只有可变参数类型方法重载冲突,会导致调用不明确;
- 可变参数类型不同,但可变参数为空时,可以省略,或者设置成null,都会导致被调用方法不明确;
- 可变参数类型是基本类型或包装类型,重载会因为自动装箱/拆箱导致调用不明确
- override的方法参数类型和形式必须一致,不能将可变参数改成数组,虽然背后实现是一样的;
/**不能有多个可变参数,并且只能是最后一个参数**/
public static void varargs10(Object ... objs, String abc){ //编译出错
}
public static void varargs11(String abc, Object ... objs){
}
/**因为可变参数是由数组实现的,调用方忽略可变参数时,可变参数为长度为0的数组;但是既然是数组,就可以设置成null,所以要注意null判断;**/
public static void varargs2Test(){
varargs2();
varargs2(null); //NullPointerException
}
public static void varargs2(String...strs){
//strs 可能为null, 应该做 strs是否为空的判断
for (String str : strs ) {
}
}
/**如果被调用的方法,既匹配了可变参数方法,有匹配了固定参数方法,固定参数方法将被调用;**/
public static void varargs3Test(){
varargs3(11, 22); //varargs30
}
public static void varargs3(int i, int j ){
System. out.println("varargs30" );
}
public static void varargs3(int i , int... arr){
System. out.println("varargs31" );
}
/**可变参数类型与前一个参数的类型一样时,与只有可变参数类型方法重载冲突,会导致调用不明确;**/
public static void varargs4Test(){
varargs4("abc" , "def" , "ijk" ); //编译出错
}
public static void varargs4(String...strs){
}
public static void varargs4(String str, String... strs){
}
/**可变参数类型不同,但可变参数为空时,可以省略,或者设置成null,都会导致被调用方法不明确;**/
public static void varargs5Test(){
varargs5(); //编译出错
varargs5("abc" , null); //编译出错
}
public static void varargs5(String str, String... strs){
}
public static void varargs5(String str, Integer... datas){
}
/**可变参数类型是基本类型或包装类型,重载会因为自动装箱/拆箱导致调用不明确**/
public static void varargs6Test(){
varargs6("abc" , 1, 2, 3); //编译出错
}
public static void varargs6(String str, int... datas){
}
public static void varargs6(String str, Integer... datas){
}
/**override的方法参数类型和形式必须一致,不能将可变参数改成数组,虽然背后实现是一样的**/
public static void varargs7Test(){
Sub sub = new Sub();
Base base = sub;
base.varargs7( "abc", "def" );
base.varargs7();
sub.varargs7(); //编译错误
sub.varargs7("abc" , "def" ); //编译错误
}
public static interface Base {
public void varargs7(String...strs );
}
public static class Sub implements Base{
@Override
public void varargs7(String[] strs) {
System. out.println("varargs7" );
}
}
四、StringBuilder和字符串+(非1.5特性,顺便提一下而已)
JDK 5.0中增加了StringBuilder, 基本上和StringBuffer一样,但去掉了所有synchronized同步关键字。
性能上StringBuilder优于StringBuffer, 所以非并发情况下使用StringBuilder没商量。
Java中对象没有参与运算符运算的可能,也没有提供像C++那样重载运算符语法支持,不要被String的+操作欺骗了。
Java1.4中,字符串的+操作在编译器生成的字节码可以看到使用的是StringBuffer进行append,
Java5.0中,+操作改成StringBuilder的append:
public static void sbTest(String s1, String s2){
String str = s1 +s2 ;
}


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











