







最近忙着找工作,又要搞毕业论文,都没时间记录了,就写一下。
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction
做了个小Demo
NVIDIA的一篇论文,采用流行的非自回归学习网络,以及将网络结构进行调整,主要采用深度可分离卷积。PS. NVIDIA用深度可分离的残差卷积结构,把语音领域的任务都走了一遍。
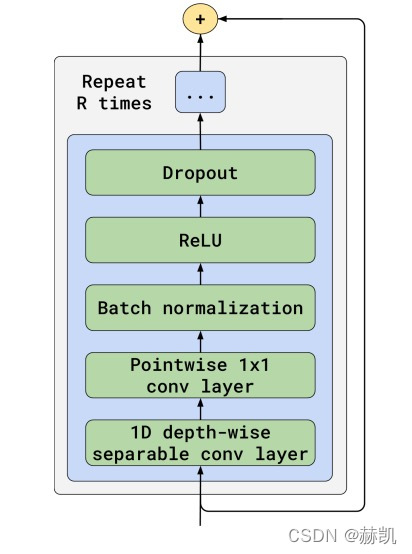
就是上面这个基本网络
这篇论文,借鉴了Fastspeech,我觉得整体网络结构明了简单,也方便复现,记录一下,整体结构图:

只看绿色部分就好,分三个部分:持续时间预测模块、音高预测模块和梅尔频谱图预测模块。比较新奇的是这三个模块是分开训练的,并且训练的时间很短。虽然训练比较方便,但是前期工作需要将文本和音频作MFA(montreal forced aligner)对齐操作。PS.有着一定声学的理论支持,做网络也比较省事儿,就知道音高是一个比较关键的特征,合成mel图,有持续时间和音高就够了。优势主要模型小训练快,但训练出的音质的话,还算行吧,比不上自回归,不过也够听了。
现在语音合成的质量已经够了,就是往小型化转,或者去弄多情感多人的,还有蛮大进步空间,再要不就是克隆别人的声音了。


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











