







Hadoop-MapReduce的第一性原理
一句话理解: 在hdfs的基础上,可以把超过PB级别的日志文件(一般为文本文件),以Map的方式逐行处理形成 Map<A,1>
Map<A,2> Map<B,1> 经过非常的牛B的Shuffer算法按key形成集合,
再将集合进行Reduce运算的东东.
MapReduce经典原理图(WordCount).单词计算
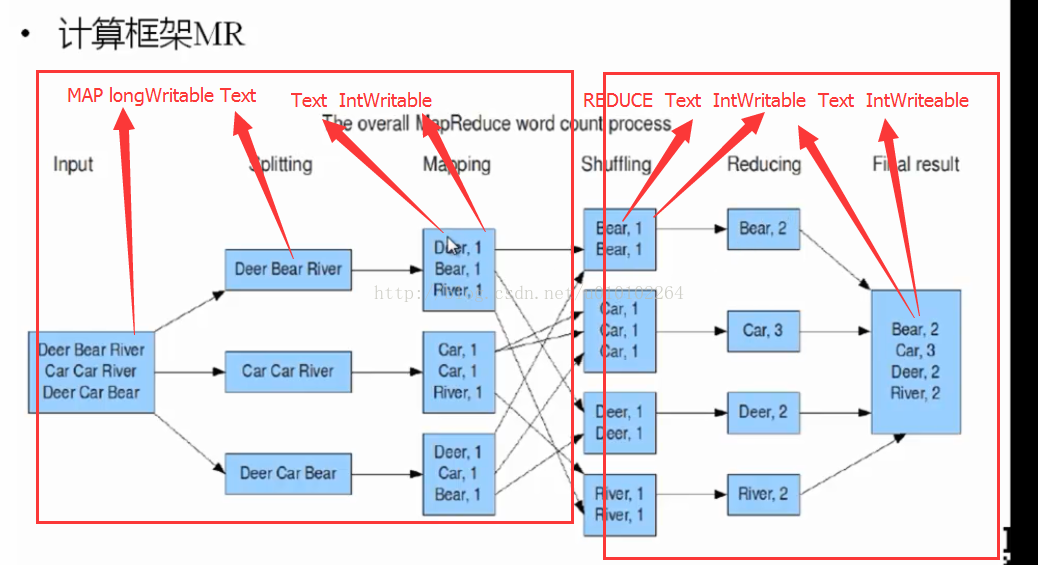
如图所示,
1.出现文本 input
2.逐行分解
3.Mapper运算为 <key,value>
4.牛B的shuffer把这些Map按key排序成了 一堆相同Key的集合.
5.对这些集合进行Reduce计算
转载请注明出处,谢谢!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









