Python 2.7
IDE Pycharm 5.0.3
Firefox 47.0.1
如有兴趣可以从如下几个开始看起,其中有我遇到的很多问题:
基础抓取(限于“豆瓣高分”选项电影及评论)请看Python自定义豆瓣电影种类,排行,点评的爬取与存储(基础)
初级抓取(限于“豆瓣电影”的各种选项,包括“热门”,“豆瓣高分”等十几个类别及评论,并打包exe)请看Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级)
进阶抓取(在初级抓取基础上,套上GUI框架,图像显示更加人性化,并打包成exe)请看 Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上)
我发现了,我不是在写代码,我是在写BUG。。。
起因
不满足于豆瓣电影的各种抓取,而把魔爪伸向了豆瓣电视剧,所以整合起来了整个豆瓣影视的抓取,所以以后要不要再抓豆瓣读书啊。。。
目的
完成对豆瓣影视,包括豆瓣电影,豆瓣电视剧,豆瓣一周排行榜的自定义抓取及GUI界面设计及打包exe
方案
使用Tkinter+PhantomJS+Selenium+Firefox实现
实现过程
1.get到首页后,根据选择,点击种类,然后根据输入需求,进行排序 –这里的输入时listbox中值的点击键入
2.抓取每个电影及超链接,进入超链接后,抓取当前电影的热评及长评
3.当用户所要求TOP数目大于第一页的20个时候,点击加载更多,再出现20个电影,重复2操作。
4.将输出写入输出框架中,写入txt中等操作
实现效果
上图吧,这里第一项的影视选择键都可以实现相关操作,
这里说明一下,第一项,影视选择,第二项,类别选择(电视剧看后面项),第三项,排序方式,第四项,是否加载评论,第五项TOP多少,第六项,保存名称(需要格式为xx.txt)
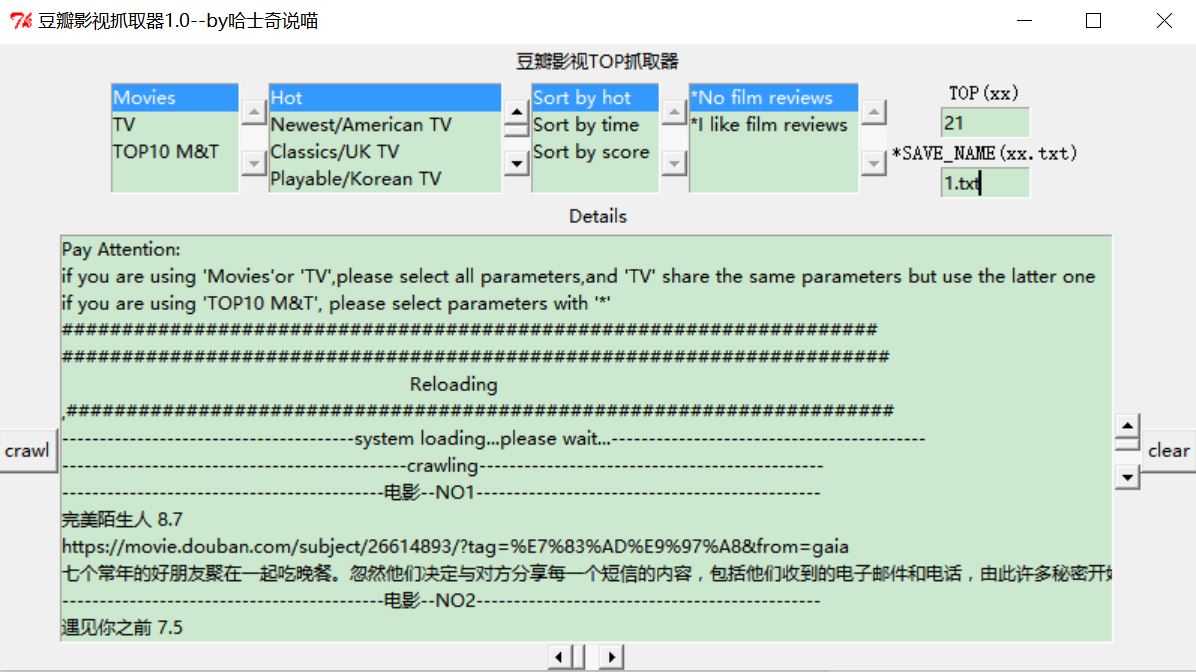
下面是exe的版本
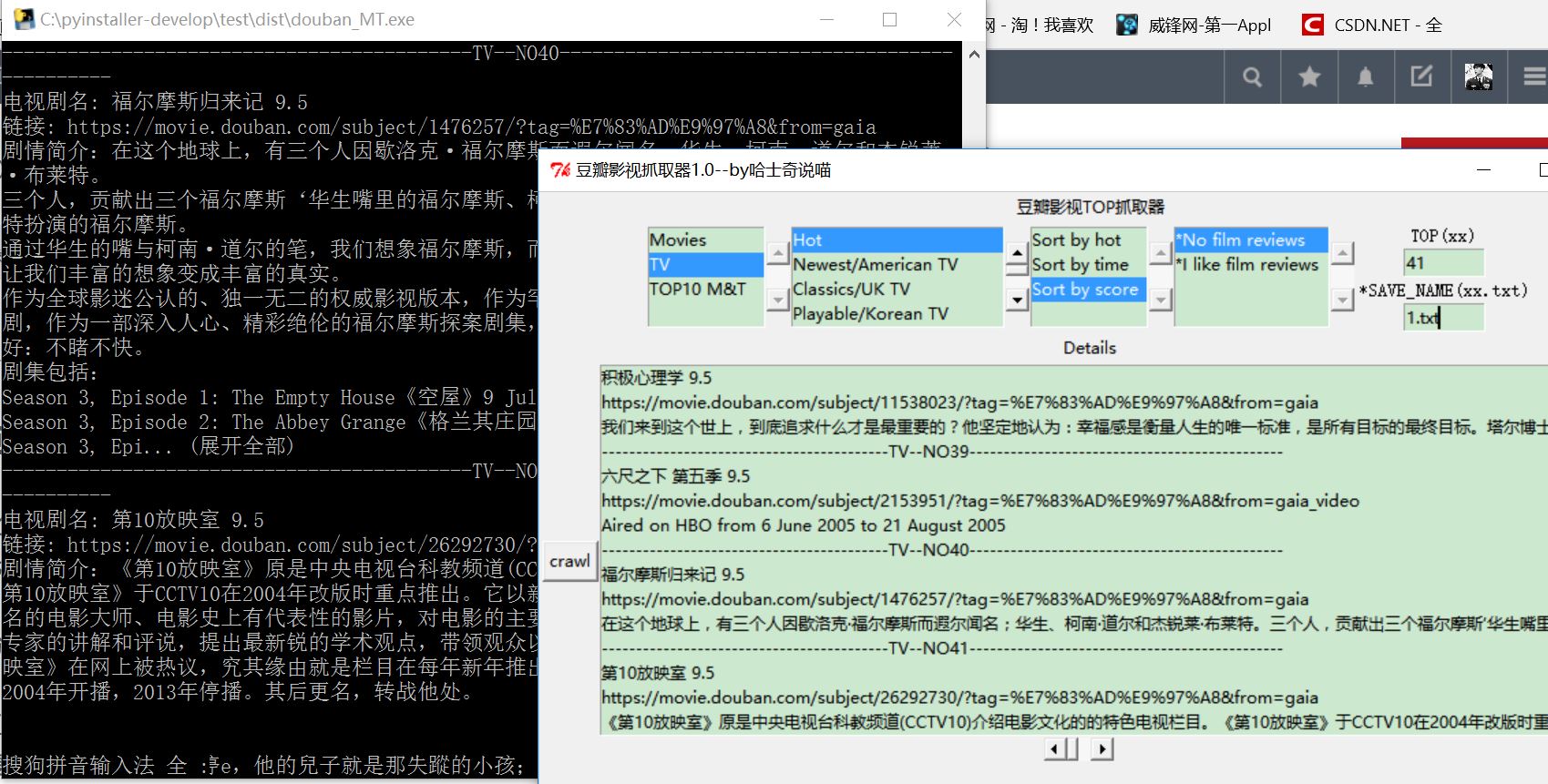
已上传资源,如有需要请点击这里进行下载
代码
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from Tkinter import *
print "---------------system loading...please wait...---------------"
def getURL_Title():
global save_name
SUMRESOURCES=0
url="https://movie.douban.com/"
driver_item=webdriver.Firefox()
wait = ui.WebDriverWait(driver_item,15)
Class_Dict={'Movies':1,'TV':2,'TOP10 M&T':3}
Kind_Dict={'Hot':1,'Newest/American TV':2,'Classics/UK TV':3,'Playable/Korean TV':4,'High Scores/Japanese TV':5,
'Wonderful but not popular/Chinese TV':6,'Chinese film/TVB':7,'Hollywood/Cartoon':8,
'Korea':9,'Japan':10,'Action movies':11,'Comedy':12,'Love story':13,
'Science fiction':14,'Thriller':15,'Horror film':16,'Whatever':17}
Sort_Dict={'Sort by hot':1,'Sort by time':2,'Sort by score':3}
Ask_Dict={'*No film reviews':0,'*I like film reviews':1}
try:
kind=Kind_Dict[Kind_Select.get(Kind_Select.curselection()).encode('utf-8')]
sort = Sort_Dict[Sort_Select.get(Sort_Select.curselection()).encode('utf-8')]
number = int(input_Top.get())
except:
print 'if you are using TOP10 M&T ,it\'s all right\n if not,please choice kind/sort/number '
class_MT = Class_Dict[MT_Select.get(MT_Select.curselection()).encode('utf=8')]
ask_comments = Ask_Dict[Comment_Select.get(Comment_Select.curselection()).encode('utf-8')]
save_name=input_SN.get()
Ans.insert(END,"#####################################################################")
Ans.insert(END," Reloading ")
Ans.insert(END,",#####################################################################")
Ans.insert(END,"---------------------------------------system loading...please wait...------------------------------------------")
Ans.insert(END,"----------------------------------------------crawling----------------------------------------------")
Write_txt('\n##########################################################################################','\n##########################################################################################',save_name)
print "---------------------crawling...---------------------"
if class_MT==1:
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'电影名: ' + list_title.text
print u'链接: ' + list_title.get_attribute('href')
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'遇到页面加载重复项bug,开始重新加载...'
driver_item.quit()
getURL_Title()
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n-------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
if class_MT == 2:
driver_item.get(url)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']//a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
for i in range(1,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '-------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'电视剧名: ' + list_title.text
print u'链接: ' + list_title.get_attribute('href')
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'遇到页面加载重复项bug,开始重新加载...'
driver_item.quit()
getURL_Title()
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n----------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
if class_MT==3:
driver_item.get(url)
for i in range(1,11):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr"))
list_title=driver_item.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr[%d]/td[2]/a"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
print u'影视名: ' + list_title.text
print u'链接: ' + list_title.get_attribute('href')
list_title_wr=list_title.text.encode('utf-8')
list_title_url_wr=list_title.get_attribute('href')
Ans.insert(END,'\n-------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------',list_title_wr,list_title_url_wr)
Write_txt('\n------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(list_title_wr,list_title_url_wr,save_name)
SUMRESOURCES = SUMRESOURCES +1
try:
getDetails(str(list_title.get_attribute('href')),ask_comments)
except:
print 'can not get the details!'
driver_item.quit()
def getDetails(url,comments):
driver_detail = webdriver.PhantomJS(executable_path="phantomjs.exe")
wait1 = ui.WebDriverWait(driver_detail,15)
driver_detail.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))
drama = driver_detail.find_element_by_xpath("//div[@id='link-report']/span")
print u"剧情简介:"+drama.text
drama_wr=drama.text.encode('utf-8')
Ans.insert(END,drama_wr)
Write_txt(drama_wr,'',save_name)
if comments == 1:
print "--------------------------------------------Hot comments TOP----------------------------------------------"
for i in range(1,5):
try:
comments_hot = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments_hot.text
comments_hot_wr=comments_hot.text.encode('utf-8')
Ans.insert(END,"--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,comments_hot_wr)
Write_txt("--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,'',save_name)
Write_txt(comments_hot_wr,'',save_name)
except:
print 'can not caught the comments!'
try:
driver_detail.find_element_by_xpath("//img[@class='bn-arrow']").click()
time.sleep(1)
comments_get = driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div")
if comments_get.text.encode('utf-8')=='提示: 这篇影评可能有剧透':
comments_deep=driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div[2]")
else:
comments_deep = comments_get
print "--------------------------------------------long-comments---------------------------------------------"
print u"深度长评:"+comments_deep.text
comments_deep_wr=comments_deep.text.encode('utf-8')
Ans.insert(END,"--------------------------------------------long-comments---------------------------------------------\n",comments_deep_wr)
Write_txt("--------------------------------------------long-comments---------------------------------------------\n",'',save_name)
Write_txt(comments_deep_wr,'',save_name)
except:
print 'can not caught the deep_comments!'
def Write_txt(text1='',text2='',title='douban.txt'):
with open(title,"a") as f:
for i in text1:
f.write(i)
f.write("\n")
for j in text2:
f.write(j)
f.write("\n")
def Clea():
input_Top.delete(0,END)
input_SN.delete(0,END)
Ans.delete(0,END)
Ans.insert(END,"Pay Attention: ","if you are using 'Movies'or 'TV',please select all parameters,and 'TV' share the same parameters but use the latter one","if you are using 'TOP10 M&T', please select parameters with '*'",'####################################################################')
root=Tk()
root.title('豆瓣影视抓取器1.0--by哈士奇说喵')
frame_select=Frame(root)
title_label=Label(root,text='豆瓣影视TOP抓取器')
title_label.pack()
MT_Select=Listbox(frame_select,exportselection=False,width=12,height=4)
list_item1 = ['Movies','TV','TOP10 M&T']
for i in list_item1:
MT_Select.insert(END,i)
scr_MT = Scrollbar(frame_select)
MT_Select.configure(yscrollcommand = scr_MT.set)
scr_MT['command']=MT_Select.yview
Kind_Select=Listbox(frame_select,exportselection=False,width=22,height=4)
list_item2 = ['Hot','Newest/American TV','Classics/UK TV','Playable/Korean TV','High Scores/Japanese TV',
'Wonderful but not popular/Chinese TV','Chinese film/TVB','Hollywood/Cartoon',
'Korea','Japan','Action movies','Comedy','Love story',
'Science fiction','Thriller','Horror film','Whatever']
for i in list_item2:
Kind_Select.insert(END,i)
scr_Kind = Scrollbar(frame_select)
Kind_Select.configure(yscrollcommand = scr_Kind.set)
scr_Kind['command']=Kind_Select.yview
Sort_Select=Listbox(frame_select,exportselection=False,width=12,height=4)
list_item3 = ['Sort by hot','Sort by time','Sort by score']
for i in list_item3:
Sort_Select.insert(END,i)
scr_Sort = Scrollbar(frame_select)
Sort_Select.configure(yscrollcommand = scr_Sort.set)
scr_Sort['command']=Sort_Select.yview
Comment_Select=Listbox(frame_select,exportselection=False,width=16,height=4)
list_item4 = ['*No film reviews','*I like film reviews']
for i in list_item4:
Comment_Select.insert(END,i)
scr_Com = Scrollbar(frame_select)
Comment_Select.configure(yscrollcommand = scr_Com.set)
scr_Com['command']=Comment_Select.yview
Label_TOP=Label(frame_select, text='TOP(xx)', font=('',10))
var_Top = StringVar()
input_Top = Entry(frame_select, textvariable=var_Top,width=8)
Label_SN=Label(frame_select, text='*SAVE_NAME(xx.txt)', font=('',10))
var_SN = StringVar()
input_SN = Entry(frame_select, textvariable=var_SN,width=8)
frame_output=Frame(root)
out_label=Label(frame_output,text='Details')
Ans = Listbox(frame_output,selectmode=MULTIPLE, height=15,width=100)
Ans.insert(END,"Pay Attention: ","if you are using 'Movies'or 'TV',please select all parameters,and 'TV' share the same parameters but use the latter one","if you are using 'TOP10 M&T', please select parameters with '*'",'####################################################################')
crawl_button = Button(frame_output,text='crawl', command=getURL_Title)
clear_button = Button(frame_output,text='clear', command=Clea)
scr_Out_y = Scrollbar(frame_output)
Ans.configure(yscrollcommand = scr_Out_y.set)
scr_Out_y['command']=Ans.yview
scr_Out_x = Scrollbar(frame_output,orient='horizontal')
Ans.configure(xscrollcommand = scr_Out_x.set)
scr_Out_x['command']=Ans.xview
frame_select.pack()
MT_Select.pack(side=LEFT)
scr_MT.pack(side=LEFT)
Kind_Select.pack(side=LEFT)
scr_Kind.pack(side=LEFT)
Sort_Select.pack(side=LEFT)
scr_Sort.pack(side=LEFT)
Comment_Select.pack(side=LEFT)
scr_Com.pack(side=LEFT)
Label_TOP.pack()
input_Top.pack()
Label_SN.pack()
input_SN.pack()
frame_output.pack()
out_label.pack()
crawl_button.pack(side=LEFT)
clear_button.pack(side=RIGHT)
scr_Out_y.pack(side=RIGHT)
Ans.pack()
scr_Out_x.pack()
root.mainloop()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
修复问题
相比较比上几次版本,改进了
1.删除无关的显性等待时间,直接全部靠wait.until来实现元素加载完成标识。
比如修改部分核心代码改变为如下:
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
2.针对豆瓣页面可能存在”加载更多”之后重复页面现象,增加了自动刷新修复页面(其实就是采用迭代,自己重新加载),所以可能会遇到这种情况(详见伪解决Selenium中调用PhantomJS无法模拟点击(click)操作 )
遇到页面加载重复项bug,开始重新加载...
---------------------crawling...---------------------
不用担心,这是自动在进行重加载和修复。
核心代码是
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'遇到页面加载重复项bug,开始重新加载...'
driver_item.quit()
getURL_Title()
3.对新增TV选项,做了一些调整,代码太长,就不放上来了,可以从源码看,主要还是增加判断选项,然后和Movies照样画葫芦
4.对新增TOP10 M&T,根据其网页特性,进行点击和抓取操作,代码见源码
5.对输入的问题,因为新增的TOP10 M&T,不需要TOP多少及其他kind及sort等选项,所以增加try/except选项,可以选择输入和不输入,当然,电影和电视时候还是要输入的,不然参数都没有就跑不了了,这里会在GUI上打印出操作须知
#键入的值对应,这几个键不是必须的,比如说选择TOP10 M&T时候
try:
kind=Kind_Dict[Kind_Select.get(Kind_Select.curselection()).encode('utf-8')]
sort = Sort_Dict[Sort_Select.get(Sort_Select.curselection()).encode('utf-8')]
number = int(input_Top.get())
except:
print 'if you are using TOP10 M&T ,it\'s all right\n if not,please choice kind/sort/number '
class_MT = Class_Dict[MT_Select.get(MT_Select.curselection()).encode('utf=8')]
ask_comments = Ask_Dict[Comment_Select.get(Comment_Select.curselection()).encode('utf-8')]
save_name=input_SN.get()
还有一个问题
我能实时在cmd窗口看到抓到的数据,但是在gui的输出窗口却看不到,只能等到cmd全部跑完才可以,我也不知道问题出在哪里,可能和线程有关?我下次尝试分一个单独线程给gui跑输入,看看是不是这个问题,我想我的语句应该没有什么问题,如果有人看出问题所在了,请留言告知,谢过
致歉
对以前的版本,有很多错误,影响大家进行测试,我深表抱歉,对未充分进行测试,这锅我背,所以我花了好多时间看电影,啊,不,花了好多时间测试,大概每个都进行了TOP40+的测试,应该没有太大问题的,有时候电脑GUI会显示未响应,请不要担心,这个正常现象。
最后
我应该多读点别人的程序,闭门造车和自己研究是两回事,取长补短再深入研究才是正道。
致谢
Python自定义豆瓣电影种类,排行,点评的爬取与存储(基础)
Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级)
Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上)
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









