







推荐系统种矩阵分解有着不错的效果,其中SVD(Singular Value Decomposition)奇异值矩阵分解也是常用的一种方法,通过对原始矩阵进行SVD分解后,可以将原始高纬数据映射到低维空间,在降维过程中,其关注的是如何去除噪声和保留更多有效信息。
其优点:简化数据,去除噪声,提高算法结果
缺点:分解过程和实际业务执行过程匹配不上
适用数据类型:数值型
SVD的原理文章有很多,这里主要谈加入时间因素的矩阵如何做分解。以我正在研究的云平台下虚拟机性能预测为背景,利用TSVD(time)预测除下一时刻虚拟机性能的实用情况。这里性能是指:CPU、内存、I/O负载和带宽。
步骤如下:
● 建立负载信息矩阵S
考虑四种资源数据:CPU、内存、I/O负载和带宽,保存过去一段时间T的四种资源数据,建立负载信息矩阵S,其中行表示每个时刻(或每个小周期)四种资源的监测量,列表示四种资源在时间T内的使用情况。
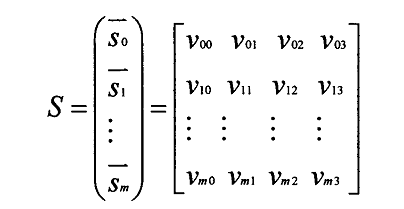
● SVD分解
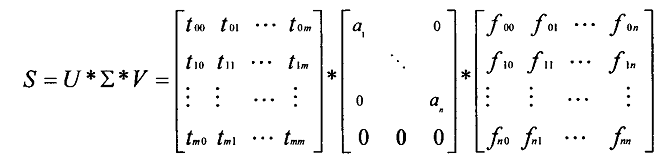
然后,根据SVD分解原理,将负载信息矩阵S分解为U、E、V。其中U为时间信息矩阵,E为奇异值对角矩阵(矩阵S和其转置乘积的特征值的平方根),V为资源信息矩阵。(U和V都是正交矩阵,E的对角元素从大到小排列)
● 时间向量相似性计算
假设当前时刻为t0,要预测下一时刻tf的负载。方法是在U中,找t0之前的所有时刻中找和t0最相似的时间向量(行向量)tc,通过点积运算(由于)找最相似,由于U是正交阵,故t0和tc的模为1,故只需找夹角即可,越小,相似度越高。
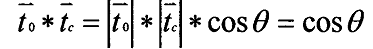
● 将来时刻tf的负载预测
tc找到后,tc的下一刻tc-1和当前时刻ti是影响tf时刻的关键向量。取两者线性组合。(本质就是认为将来时刻的负载和当前和历史最相似向量两者有关。)
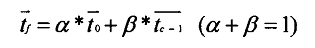
● 奇异值对角矩阵E重要特征选取
并不是所有的奇异值都可以表示数据的重要特征,对于排名靠后的奇异值要剔除(干扰因子),本文只删除了最后一个。其实,常用方法是选取矩阵E中总能量的90%的信息。
总能量:所有奇异值平方和
90%信息:从大往后依次取奇异值平方相加,直到第一次大于90%为止。则取前几个奇异值。
● 下一时刻预测出的负载使用量为:
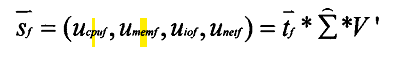
注意:V’是根据E’的变化而变化的,最终目的是保证矩阵大小和原始一样。
SVD也是通过将|S-Sf|作为目标函数,通过SGD等方法求得U(tf)、E、V。
这篇论文作为一种性能预测的思路,其实挺简单的,而且实现起来也很容易。但是它也只是在单个虚拟机上进行预测,没有考虑分布式的需求。















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









