







本文来自于网易云课堂
进行误差分析
如果你希望让学习算法能够达到人类的地步,但是还没有达到,那么人工检查一下你的算法犯的错误,会让你了解接下来该做什么。这个过程称为误差分析。

对于一个猫狗分类的任务,你最终实现了90%的精度,这远远没有达到你的目标。然后你对出错的分类图片进行分析,发现他们看起来是有点像猫。或许你的队友给你提一些建议,增加一些针对狗的图片优化算法,让你对狗的分类更加合理。那么,问题来了,是不是应该开始去做一个项目专门处理狗呢?这个过程可能会花费你几个月的时间,这样做是不是值得?可能最后一点用都没有。
这里有个误差分析流程,可以让你很快知道这个方向是否值得努力。
误差分析:
- 获取大约100个作用错误分类的dev set 样本
- 统一有多少是狗。
假如说在错误标记的开发集例子中有5%是狗,这意味着在100个例子中就算你全部修复了你也只能修正这100个错误中的5个。或者换句话说你在狗的分类上花费了大量时间最终只是让你的误差从10%下降到9.5%。这里有个性能上限(ceiling)的概念,它可以帮你确定算法性能呢的上限,比如说完全解决狗的问题可以对你有多少帮助。但是,如果说你发现错误分类的例子中有50%是狗,那么花时间去解决狗的问题可能效果就更好。这个时候你如果真正的去解决狗的问题,那么你的误差可能就从10%下降到5%了。然后你觉得可以向误差减半的方向尝试,可以集中精力减少错误标记的狗图的问题。在机器学习中,有时很鄙视手工操作,但如果要搭建应用系统,那这个简单的人工统计步骤-误差分析,可以节省大量时间。对于错误分类,你可以化5-10分钟统计下有没有占比5%或者50%的东西,然后这个会给你确定一个方向,帮你节省几个月的时间,然后你就可以投入到解决错误标记的狗图中。
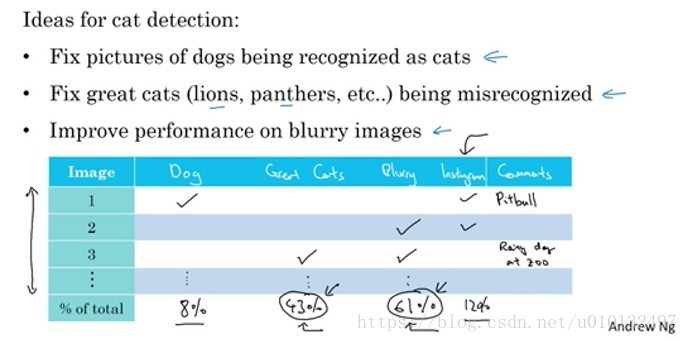
有时做误差分析时也可以同时并行评估几个想法。比如你有几个改善猫检测器的想法,比如狗误识别为猫,或者大型猫科动物如狮子,豹,猎豹等被误识别,或者是想提高模糊图像的表现。Andrew Ng一般会列一张表格来统计其中的百分比,有时候还会加一些备注,来判断是否这个方向值得你去努力。假如说模糊图片占比很大,分析的结果不是说你一定要处理模糊图片,这个分析没有一个严格的数学公式告诉你应该做什么,但它能让你对应该选择哪些手段有个概念。这个很大程度上取决于你有多少改善模型的想法。
清楚标注错误的数据
在监督学习中,你的数据有X和Y组成,对于有些输出Y,你可能会错误的标记,就是说你的原始数据有了错误的标签Y,那么是否值得花时间去修正这些标签呢?注意这里是原始数据的误标记的例子而不是算法训练出来的分类错误的例子。
首先,对于训练集。事实证明,深度学习算法对于训练集中的随机误差是相当鲁棒的。只要你的标记出错的例子,比如可能是输入错误,距离随机误差很近,也就是说只要误差足够随机,那么放着这些误差不管可能也没问题。警告:深度学习算法对随机误差很鲁棒,但是对系统性的错误就没那么鲁棒了。比如说如果做标记的人一直把白色的狗标记为猫,那就成问题了。因为你的分类器学习之后会把所有白色的狗都分类为猫。
对于开发集或测试集错误分类的例子呢。那么在误差分析中,你可以单独开辟一列来统计错误标注的数量。
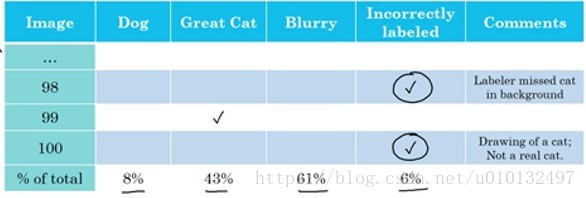
那么是否值得修复这6%的样本呢?Andrew Ng建议如果这些标记错误严重影响了你在开发集上评估算法的能力,那么就应该花时间修正错误的标签。反之没必要花宝贵的时间去处理。
这里有一些指导原则来纠正误标注的例子。
1.不管用什么手段都要同时作用在开发集和测试集上。
2. 强烈建议你要考虑同时检验算法判断正确和判断错误的例子。
第二点不容易做,也经常不做。因为找错误的好处理,因为可能只有2%,但找98%的很难。尽管如此,但也是要考虑到的。

最后几个建议:
首先,深度学习研究人员有时会喜欢这样说,“我只是把数据提供给算法,我训练过了,效果拔群”,这话说出了很多深度学习错误的真相。更多时候,我们把数据喂给算法,然后训练它,并减少人工干预,减少使用人类的见解。但Andrew Ng认为在构造实际系统时,通常需要更多的人工误差分析,更多的人类见解来架构这些系统,尽管深度学习的研究人员不愿意承认这点。
第二点,不知道为什么,我-指Andrew Ng 看一些工程师和研究人员不愿意亲自去看这些例子,可能是因为这些例子很无聊。但是,花几分钟或者几个小时是很值得的。
快速搭建你的第一个系统并进行迭代
如果你正在开发全新的机器学习应用,Andrew Ng给出这样的建议:
你应该尽快建立你的第一个系统原型,然后快速迭代。对于一个机器学习应用,一般会有很多个方向,并且每个方向都是相对合理的,可以改善你的系统,但挑战在于你如何选择一个方向集中精力处理。建议是,如果你想搭建全新的机器学习程序,就是快速搭好你的第一个系统然后开始迭代。具体就是设置开发集和验证集还有指标,这样就决定了你的目标所在。然后马上搭好一个机器学习系统原型,然后找到训练集,训练一下看看效果,开始理解你的算法表现如何。接着,建立好一个系统以后,你就可以使用偏差方差分析以及误差分析来确定下一步优先做什么。
如果你将将其学习算法应用到新的应用程序里,你的主要目标是弄出能用的系统,而不是发明全新的机器学习算法,这是完全不同的目标。所以鼓励搭建快速而粗糙的实现然后慢慢改进。














 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









