







Elasticsearch实战- Match及MatchPhrase搜索重积分优化Rescore
文章目录
1.Match与MathcPhrase对比
match与match_phrase对比
- match效率高,match_phrase效率低,因为match市全文检索匹配,但是match_phrase是搜索匹配所有单词后,要进行位置position连续计算,根据你的连续值来判断是否满足需求,另外还有一个前缀匹配 proximity search更加复杂,不仅要搜索所有单词,还要计算移动单词的位置来实现近似匹配,效率更低
- match效率 比match_phrase效率高 10倍左右, 比 proximity 效率高20倍左右
- 开发时如果需要 promixmity 近似搜索,一定要注意效率,尽量减proximity搜索的doc数量,
- 减少 proximity搜索数量 策略一般就是先 match搜出来需要的数据然后使用 proximity来搜索 关键字距离接近的 doc,然后计算相关度分数,影响结果排序,就是 rescore
- rescore重积分尽量使用分页,每次支队分片shared返回结果的前N行来及进行处理rescore,因为用户搜索也只看前几页,对所有doc进行rescore重积分是没有意义的
1.1准备数据
准备数据
POST /testcross/_bulk
{"index":{"_id": 1}}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3}}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4}}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5}}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6}}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}
2.match_phrase 短语搜索精确匹配原理
2.1 match phrase 短语匹配 搜索条件不分词原理分析
如果 你想搜 like elasticsearch 这个短语 存在 content内容中,你应该这么写
#把 like elasticsearch 当作整个短语来搜索 ,没有做任何切割,比如单个单词 like 是搜不出来的
get /testcopy/_search
{
"query":{
"match_phrase": {
"content": {
"query": "like elasticsearch"
}
}
}
}
match_phrase 是如何实现 分词了,但是把整个 关键字 当作一个整体 去查询的 ?
我们看下这个句子的分词 i like elasticsearch developer
get /testcross/_search
{
"query":{
"multi_match": {
"query": "湖北省 武汉市 江汉区",
"fields": ["provice","city","area"],
"type": "most_fields",
"operator": "and" // 或者用 or 都是不行的
}
}
}
查询 结果
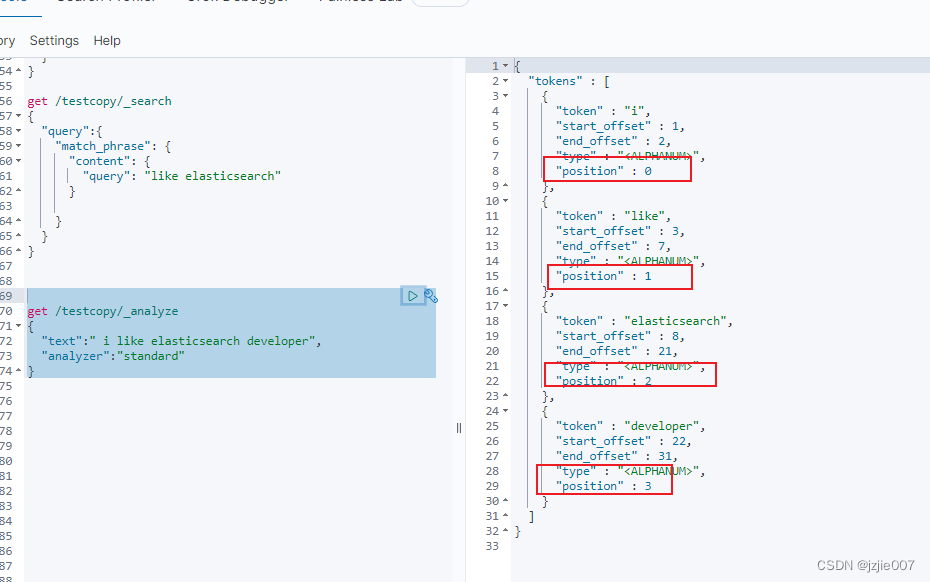
分析下结果:
- i 这个单词 是第一个 , position : 0
- like 单词 第二个, position : 1
- elasticsearch 单词 第三个, position : 2
- developer 单词 第四个, position : 3
ES先对 文本分词, 然后记录 每个单词的 position, 这个时候 用 match_phrase 搜索的时候 搜索 like elasticsearch 这个短语, 先查 like 位置 1 , 然后查 elasticsearch 2 , 这两个位置是连续的, 就认为这个单词 不可分割匹配到了 要查的结果
这个就是 match_phrase的短语搜索匹配原理
2.2 match_phrase slop参数控制单词下标移动步长
Slop 什么意思 ? 比如句子
- i like elasticsearch developer 单词分词后下标 i->0 like->1 elasticsearch->2 develope ->3
这个句子 like 需要移动 0次 就找到了紧邻的 elasticsearch ,所以 他们之间的 slop就是 0 - i like to write best elasticsearch article 单词分词后下标 i->1 like->2 to->3 write->4 best->5 elasticsearch->6 article->7
这个句子 like 需要移动 1次 到 to, 2次到 write, 3次到best, 然后就找到了紧邻的 elasticsearch ,所以 他们之间的 slop就是 3
场景
- 如果我想搜索 like elasticsearch 这两个单词 如果不是紧挨的也要搜出来 这种 如何实现 ?
- 如果说 我想控制 比如 like 和 elasticsearch之间 如果有超过 3个单词 就认为不匹配, 比如 like a b c elasticsearch 但是 如果两个单词之间 小于 3个单词 就认为匹配,这种如何实现
有人说 简单,搜索 like elasticsearch 这两个单词 如果不是紧挨的也要搜出来 这种 如何实现 这就是 must语法
get /testcopy/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"content": "like"
}
},
{
"match": {
"content": "elasticsearch"
}
}
]
}
}
}
must语法查看结果, 结果正确, 既包含 like 又包含 elasticsearch的 doc被搜出来
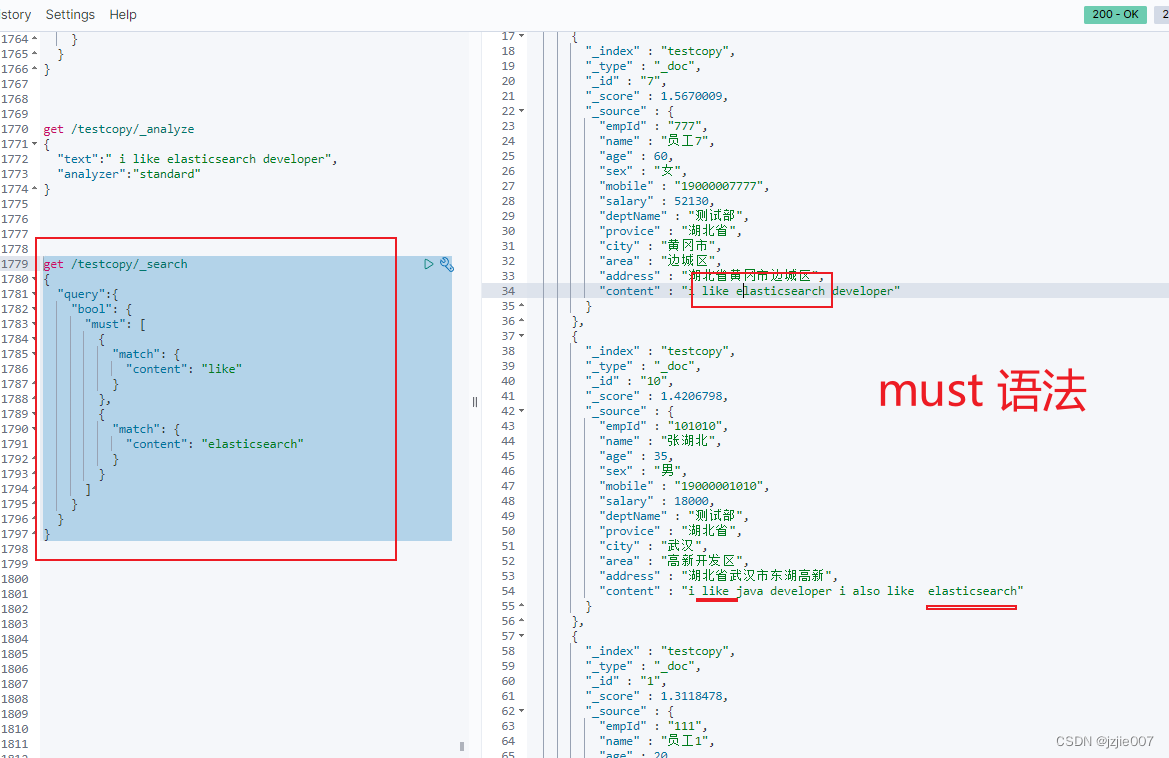
** 但是 如果 我想搜 like 和 elasticsearch 之间 超过 5个单词就 不匹配 不返回 结果 这种情况 如何实现**
解决方案:
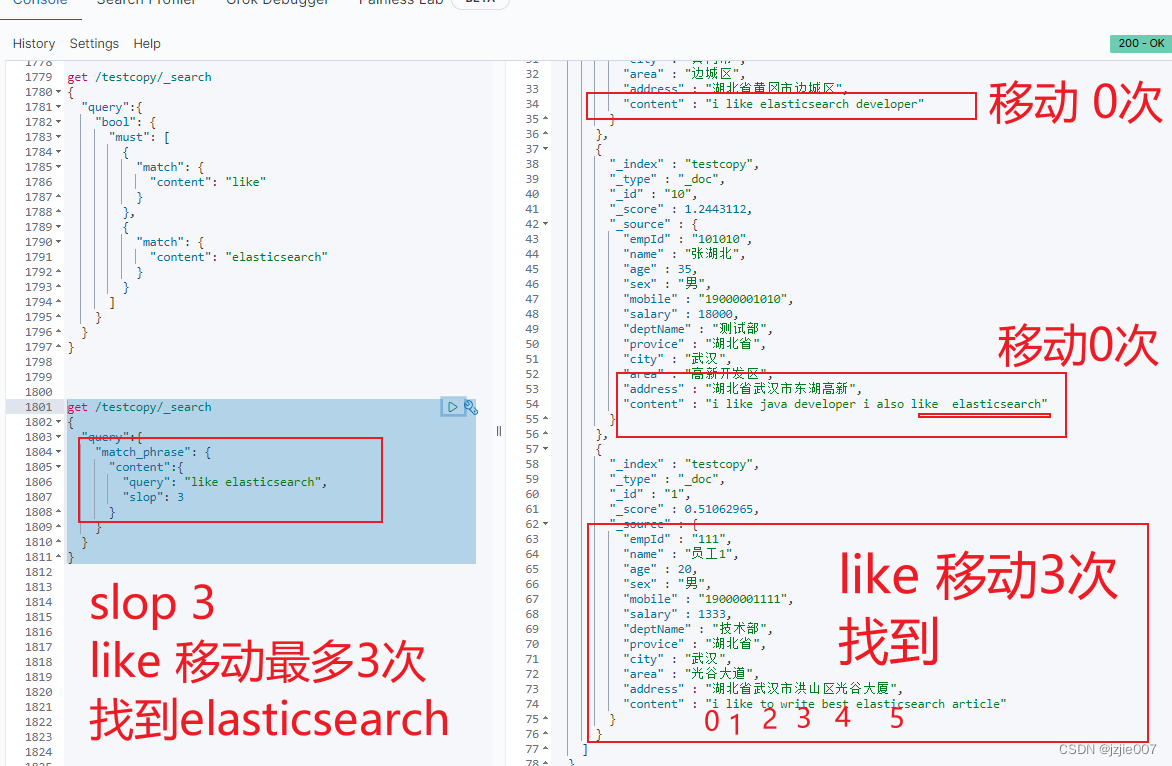
这种 情况就要 用 match_phrase 加上参数 slop 来控制实现了
#这种就是 查 like elasticsearch 之间最多移动 3次 匹配的结果
get /testcopy/_search
{
"query":{
"match_phrase": {
"content":{
"query": "like elasticsearch",
"slop": 3
}
}
}
}
查询结果 如下:移动 0次及移动 3次内的全都返回结果
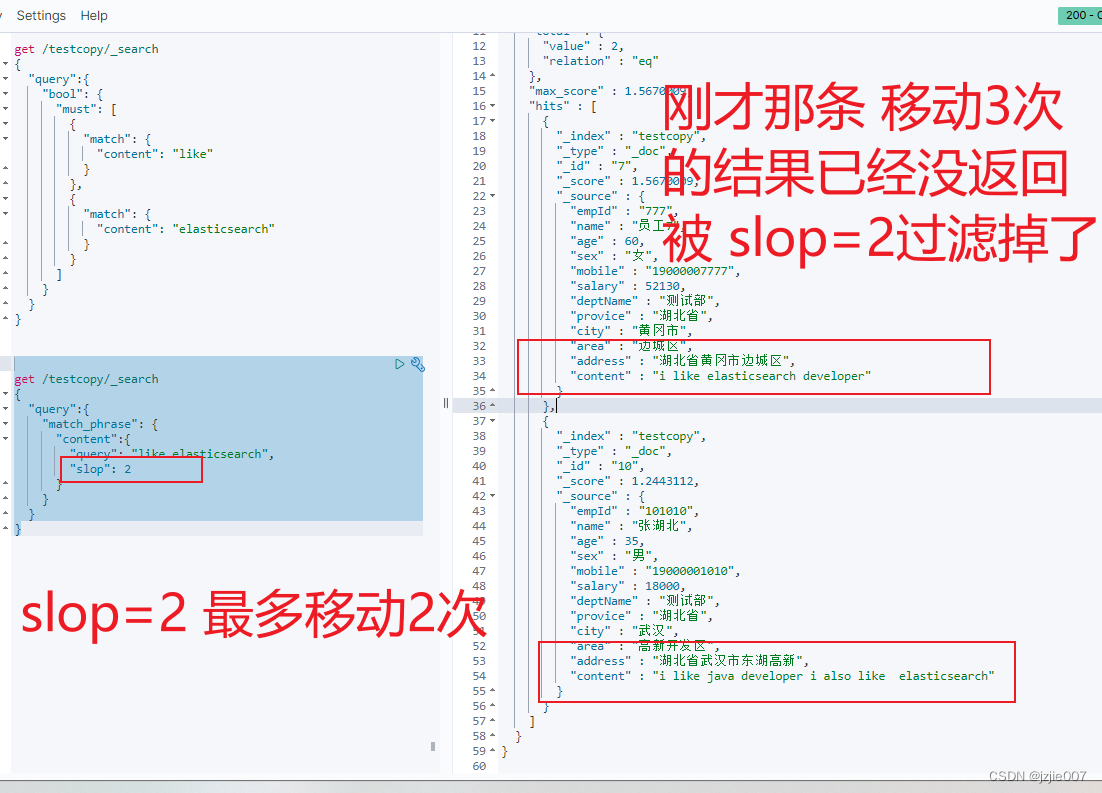
如果缩小 slop=2 试一下查询结果, 上面那条 员工1 slop为3的 记录没有匹配, 已经被过滤掉了
3.Match及Match_phrase召回率与精准度优化
- 召回率 : 就是搜索关键字 like elasticsearch, 有多少个doc作为返回结果/ 全部文档数 就是多少召回率
- 精准度 : 就是搜索关键字 like elasticsearch,能不能尽可能让包含 like elasticsearch,或者是like和 elasticsearch离的很近的doc,排在前面,就是精准度
分析:
- match 精确匹配,召回率低,精准度高
- match_phrase 近似搜索 召回率高了,精准度低
如何兼容二者?
3.1 match 精确度优先匹配
单一使用 match 匹配
get /testcopy/_search
{
"query":{
"match": {
"content": "like elasticsearch"
}
}
}
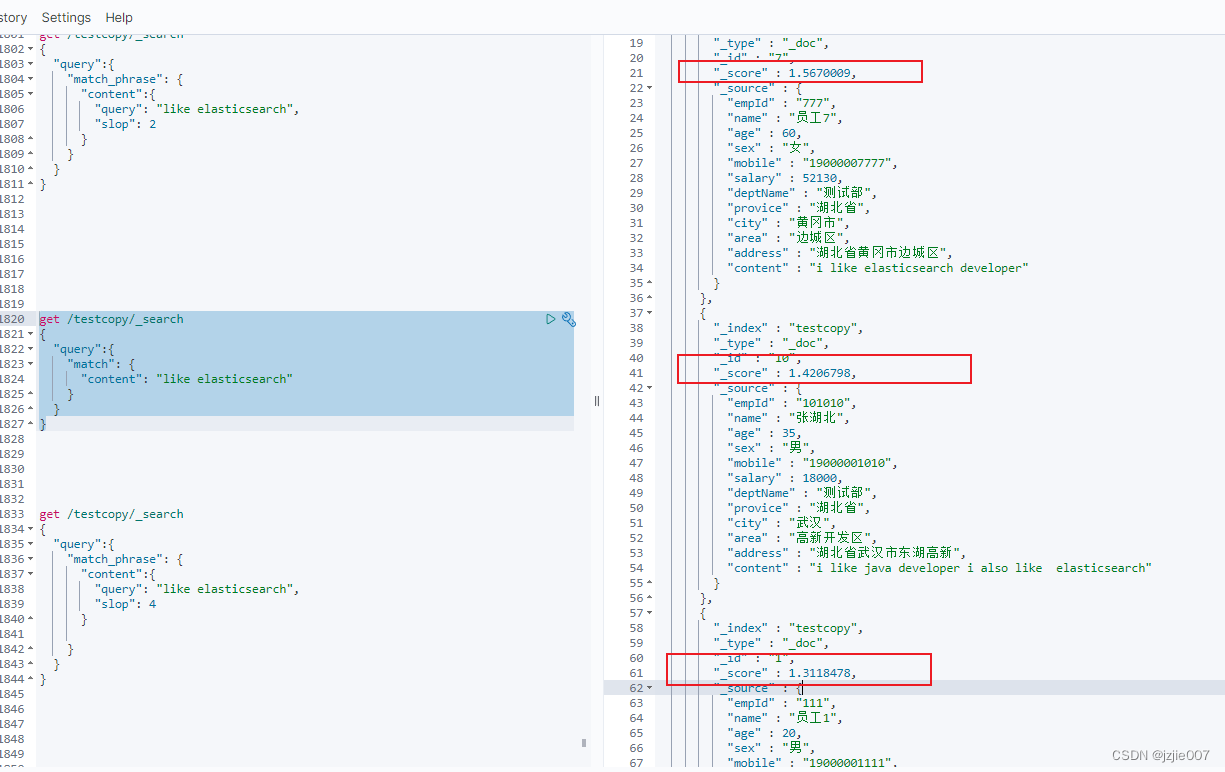
可以看到查询结果, 分数顺序分别是 员工7, 张湖北, 员工1
| 员工 | content | score |
|---|---|---|
| 员工7 | i like elasticsearch developer | 1.5670009 |
| 张湖北 | i like java developer i also like elasticsearch | 1.4206798 |
| 员工1 | "i like to write best elasticsearch article | 1.3118478 |
3.2 match_phrase 召回率优先匹配
单一使用 match_phrase 匹配
get /testcopy/_search
{
"query":{
"match_phrase": {
"content":{
"query": "like elasticsearch",
"slop": 4
}
}
}
}
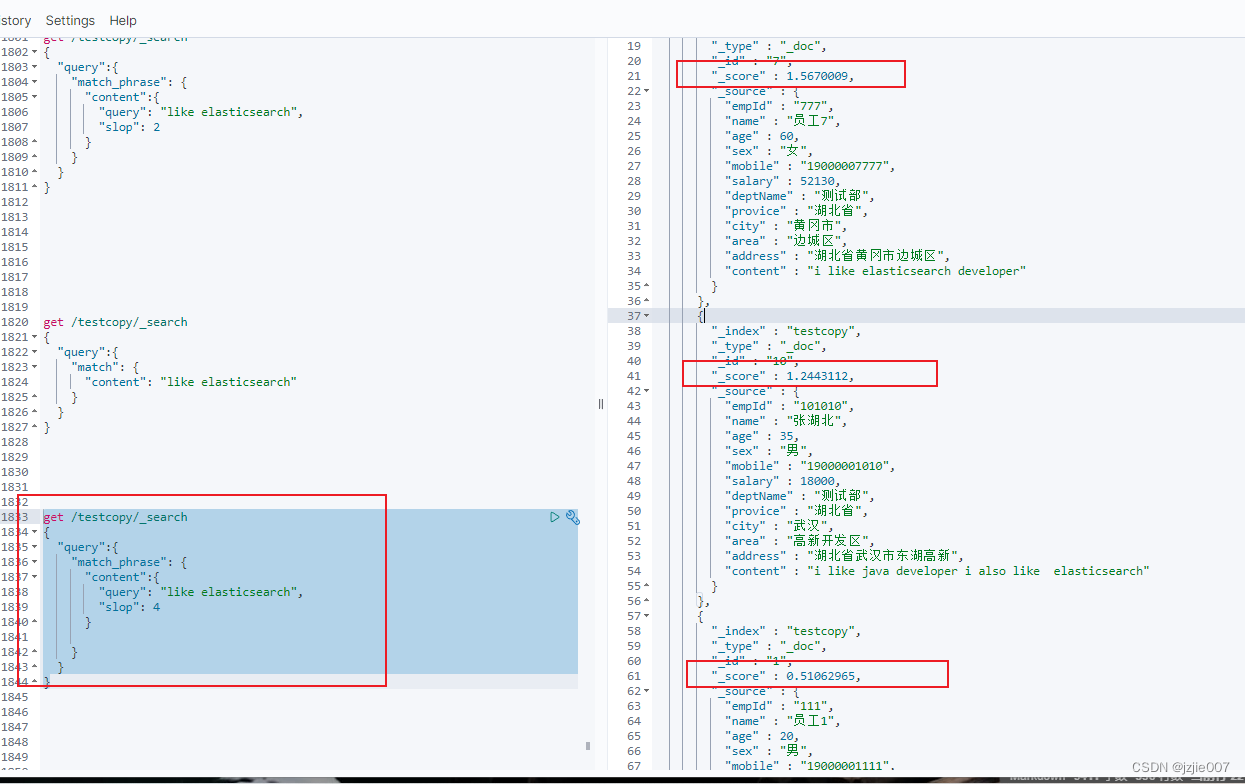
可以看到查询结果, 分数顺序分别是 员工7, 张湖北, 员工1 ,但是分数 明显变了, 张湖北分数降低一些, 员工1的 分数 降低了很多 从 1.3直接变为 0.5 ,就是 不太匹配的 分数明显降低
| 员工 | content | score |
|---|---|---|
| 员工7 | i like elasticsearch developer | 1.5670009 |
| 张湖北 | i like java developer i also like elasticsearch | 1.2443112 |
| 员工1 | "i like to write best elasticsearch article | 0.51062965 |
3.3 match与match_phrase混合使用
混合使用 match及match_phrase 来提高精准度与召回率
get /testcopy/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"content": "like elasticsearch"
}
}
],
"should": [
{
"match_phrase": {
"content":{
"query": "like elasticsearch",
"slop": 4
}
}
}
]
}
}
}
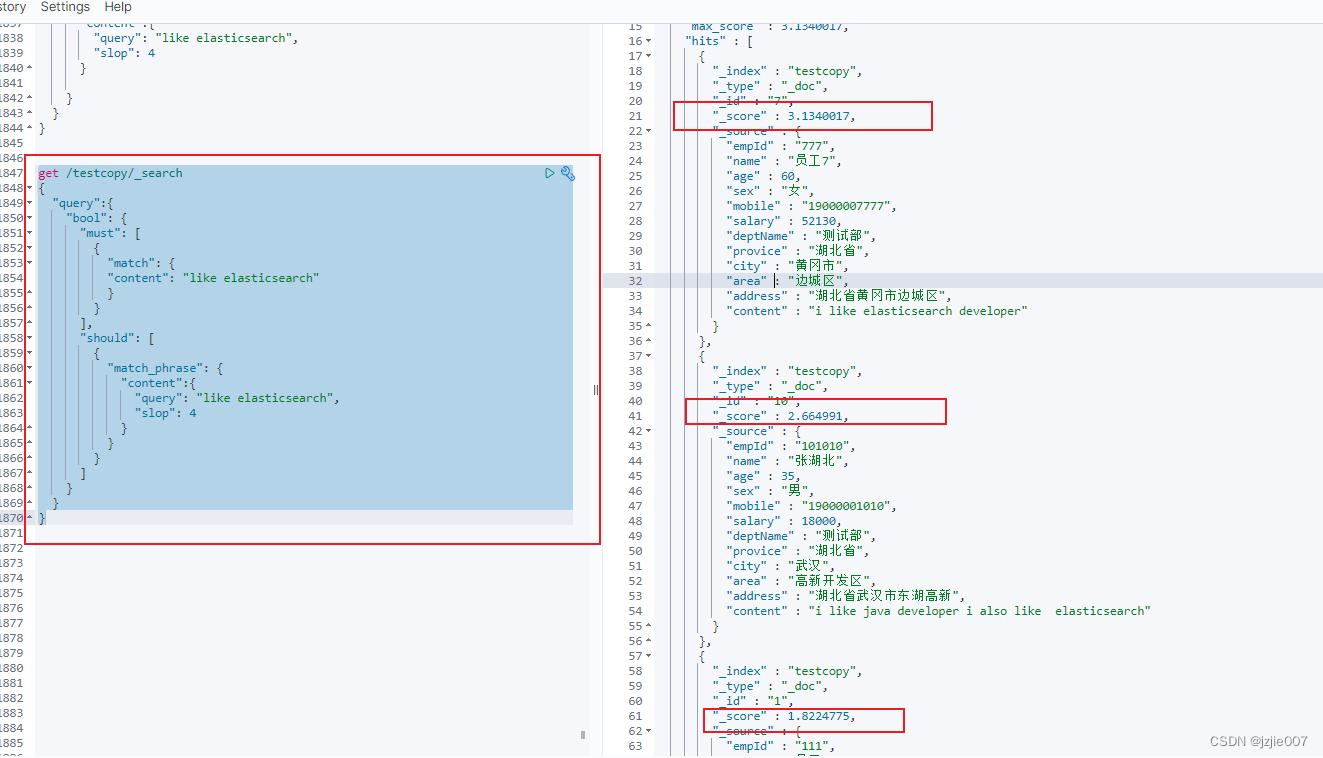
查询 结果 员工7最优先,分数直接飙升 3.13, 其次时 张湖北 分数 2.6, 最后是 员工1 分数 1.8, 分数 明显拉开了文档之间的 差异
文章足够多的情况下, 就能后兼容 召回率与精确度
| 员工 | content | score |
|---|---|---|
| 员工7 | i like elasticsearch developer | 3.1340017 |
| 张湖北 | i like java developer i also like elasticsearch | 2.664991 |
| 员工1 | "i like to write best elasticsearch article | 1.8224775 |
4.Rescore重积分
优化 近似搜索的查询性能,一般就是减少要进行proximity(近似) match搜索的document数量。
- 用match query先过滤出需要的数据
- 然后再用proximity match来根据term距离提高doc的分数
- 同时proximity match只针对每个shard的分数排名前n个doc起作用,来重新调整它们的分数,这个过程称之为rescorte,重计分,因为一般用户会分页查询,只会看到前几页的数据,所以不需要对所有结果进行proximity match操作
- 重积分参数 window_size 默认值是from和size参数值之和,它指定了每个分片上参与二次评分的文档个数, 表示从shared分片数据中取每个分片的多少条数据, 假如window_size=20,你现在有3个shared分片,那么结果就是有20*3=60条数据
- 重积分参数 query_weight 查询权重,默认值是1,原始查询得分与二次评分的得分相加之前 ,乘 该值 提高原始查询得分
- 重积分参数 rescore_query_weight 二次评分查询的权重值,默认值是1,二次评分查询得分在与原始查询得分相加之前 , 乘该值 提高二次评分查询得分
- rescore_mode 二次评分模式,默认为total,可用的选项有total、max、min、avg和mutiply。
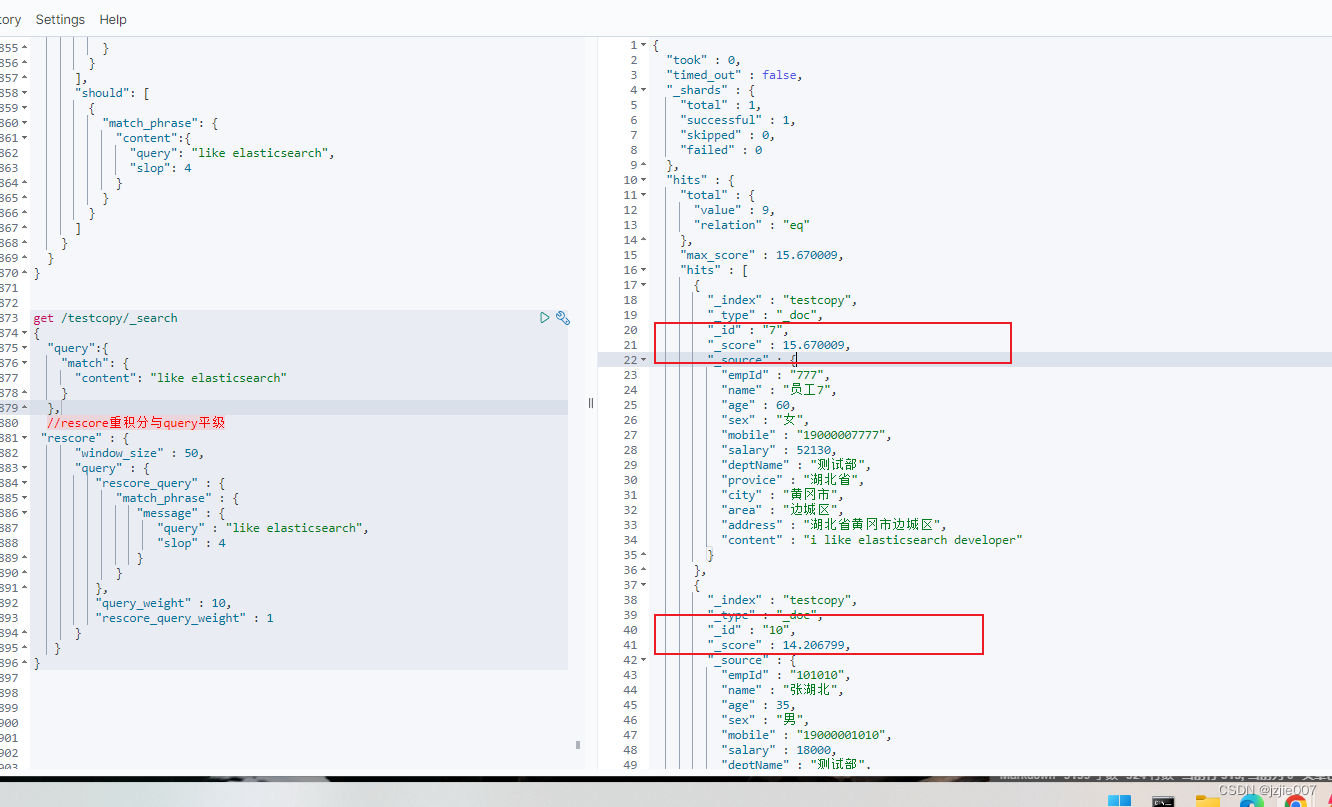
查询 like elasticsearch 重新计算分数, query_weight =10 ,表示 原分数 * 10 + 积分后的分数
get /testcopy/_search
{
"query":{
"match": {
"content": "like elasticsearch"
}
},
//rescore重积分与query平级
"rescore" : {
"window_size" : 50,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "like elasticsearch",
"slop" : 4
}
}
},
"query_weight" : 10,
"rescore_query_weight" : 1
}
}
}
查询 结果 员工7最优先,分数原来是 1.5670009,现在变成了 15.670009, 分数 *10
至此 我们已经已经讲了 match_phrase 使用及原理, 以及 match和match_phrase来提升精确度及召回率,后面实现了重积分来提升结果排序效果
















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









