






我们有一个ASCII码
0-31是控制字符,32到127是可打印字符,32位是打印字符『空格』可以方便地存储在7bits里。
因为字节(bytes)最多可以容纳8bits,所以很多人会想将128-255用于自己的目的。
0-127位是 ASCII码
IBM PC推出时,IBM使用了128-255位
称为 扩展ASCII码,但是这个标准各个国家并不完全认可。
各地按照将这128个数字用于自己的目的,当人们开始在美国以外的地方购买pc时,各种各样不同的OEM字符集就出现了,它们都使用这128个字符来实现各自的目的。例如在一些电脑上的字符130代码显示为 é, 但是在以色列的电脑显示为 ג .

但是,一个byte是一个字符,一个字符是8位的,只要你不把一个字符串从一台计算机移动到另一台计算机,或者说一种以上的语言,它总是可以工作的。当然,一旦互联网出现,将字符串从一台计算机移动到另一台计算机就变得非常普遍,整个混乱局面就会出现。
当大家使用多字节的时候,就会出现混乱了,幸运的是,Unicode被发明了。
Unicode创建了一个单一的字符集,包括地球上所有合理的书写系统。
我们假设一个字母映射到一些可以存储在磁盘或内存中的位
A -> 0100 0001
Unicode 一个字母映射到一个叫做codepoints。如何在内存或磁盘上表示codepoints ?
每个字母都被Unicode分配了一个魔法数字,它是这样写的 U+0639.
这个十六进制的魔法数字(0639)被称为codepoint,这个"U+" 是“Unicode”的意思。
我们来看一个字符串: Hello .
在unicode里,对应五个code points : U+0048 U+0065 U+006C U+006C U+006F .
如何将他们存储在电子设备中?
Unicode编码最早的想法是,让我们把这些数字分别存储在两个字节中。所以你好变成了
00 48 00 65 00 6C 00 6C 00 6F
或者
48 00 65 00 6C 00 6C 00 6F 00
早期的实现者希望能够以大端或小端模式存储他们的Unicode codepoints.
于是人们想出来一个奇特的惯例,在每一个unicode字符串前带上 " FE FF",这个被称作 “Unicode Byte Order Mark”.
如果您正在交换高字节和低字节,它看起来就像这样"FF FE"
读取您的字符串的人将知道他们必须交换其他字节.
并不是你所遇到的所有unicode字符串的开头都带有字节序。
UTF-8是另一个存储Unicode代码点字符串的系统
在UTF-8中,0-127中的每个codepoints都存储在一个字节中。只有codepoints128及以上使用2、3(最多6个字节)存储。
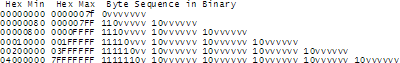
这有一个很好的作用,即英语文本在UTF-8中与在ASCII中看起来完全一样,所以美国人甚至没有注意到任何问题,只有世界上的其他国家才需要经历这些困难。
因此,“Hello” ( codepoints是 U+0048 U+0065 U+006C U+006C U+006F) 将会在ASCII 和 ANSI中相同存储。
如果你使用重读字母、希腊字母或克林贡字母,您必须使用几个字节来存储单个codepoints . 但美国人永远不会遇到。
Unicode 可以使用的编码方案有三种,分别是:
UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF 是 Unicode Transformation Format 的缩写,意思是“Unicode转换格式”,后面的数字表明至少使用多少个比特位(Bit)来存储字符。
-
UTF-8
UTF-8 的编码规则很简单:如果只有一个字节,那么最高的比特位为 0,这样可以兼容 ASCII;
如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1);
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)。
xxx 就用来存储 Unicode 中的字符编号。

对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储。
2) UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
3) UTF-16
UFT-16 比较奇葩,它使用 2 个或者 4 个字节来存储。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
宽字符和窄字符(多字节字符)
有的编码方式采用 1~n 个字节存储,是变长的,例如 UTF-8、GB2312、GBK 等;如果一个字符使用了这种编码方式,我们就将它称为多字节字符,或者窄字符。
有的编码方式是固定长度的,不管字符编号大小,始终采用 n 个字节存储,例如 UTF-32、UTF-16 等;如果一个字符使用了这种编码方式,我们就将它称为宽字符。
Unicode 字符集可以使用窄字符的方式存储,也可以使用宽字符的方式存储;GB2312、GBK、Shift-JIS 等国家编码一般都使用窄字符的方式存储;ASCII 只有一个字节,无所谓窄字符和宽字符。
传统的双字节存储方法称为UCS-2 或者 UTF-16 ,因为它占用两个bytes,也是16个bits。
如果您试图在编码中表示的Unicode编码点没有对应的值,你通常会得到一个小问号"? " 或者 “-> �”.
传统的编码方法有数百种,它们只能正确地存储一些codepoints,并将其他的codepoints转换成问号.
UTF7,8,16,32可以正确的存储任意的codepoints.
在不知道字符串使用什么编码的情况下使用字符串是没有意义的。没有纯文本这种东西。
如果你有一个字符串存储在内存中、文件里、邮件信息里, 你必须知道它的编码,否则你不能正确的解析并展示出来。
如果你不告诉我一个特定字符串的编码 使用的是 UTF-8 or ASCII or ISO 8859-1 (Latin 1) or Windows 1252, 您就无法正确地显示它,甚至无法计算它的结束位置。有超过100个编码,对codepoints在127以上的字符都无力为例。
那么,我们如何保存关于字符串使用什么编码的信息?有一些标准的方法可以做到这一点。
对于邮件信息,你应该在form header 中添加如下字符串:
Content-Type: text/plain; charset="UTF-8"
对于一个web网页,在meta标签中指明Content-Type编码
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
但是meta标签必须是部分的第一项内容,因为一旦web浏览器看到这个标记,它就会停止解析页面,并在使用指定的编码重新解释整个页面。
如果浏览器没有找到 Content-Type 怎么办呢?
浏览器会做一件很有趣的事情:它尝试根据不同字节出现在特定编码的文本中的频率进行猜测。
参考:
Unicode and Character Sets
文字是如何显示的
点阵字库
点阵字库是把每一个汉字都分成16×16或24×24个点,然后用每个点的虚实来表示汉字的轮廓,常用来作为显示字库使用,这类点阵字库汉字最大的缺点是不能放大,一旦放大后就会发现文字边缘的锯齿。
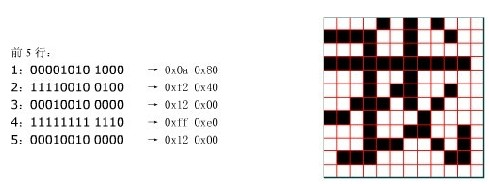
所有的汉字或者英文都是下面的原理,
由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)
生成的字库说明
一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2(GBK编码16进制,检测),所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
参考
参数化设计与字体战争
文字点阵的制作
Computers & Writing Systems
贝塞尔曲线介绍
OpenType字库文件
The TrueType Instruction Set















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









