







 本文通过对某招聘网站的大数据职位信息进行Hadoop平台上的数据分析,揭示了当前大数据行业的薪资水平、地域分布、公司福利及技能需求等关键信息。
本文通过对某招聘网站的大数据职位信息进行Hadoop平台上的数据分析,揭示了当前大数据行业的薪资水平、地域分布、公司福利及技能需求等关键信息。
Hadoop大数据招聘网数据分析综合案例
- Hadoop大数据综合案例1-Hadoop2.7.3伪分布式环境搭建
- Hadoop大数据综合案例2-HttpClient与Python招聘网数据采集
- Hadoop大数据综合案例3-MapReduce数据预处理
- Hadoop大数据综合案例4-Hive数据分析
- Hadoop大数据综合案例5-SSM可视化基础搭建
- Hadoop大数据综合案例6–数据可视化(SpringBoot+ECharts)
大数据价值链中最重要的一个环节就是数据分析,其目标是提取数据中隐藏的数据,提供有意义的建议以辅助制定正确的决策。通过数据分析,人们可以从杂乱无章的数据中萃取和提炼有价值的信息,进而找出研究对象的内在规律。
数据分析是指用适当的统计分析方法对收集来的大量数据进行分析,从行业角度看,数据分析是基于某种行业目的,有目的的进行收集、整理、加工和分析数据的过程,通过提取有用信息,从而形成相关结论,这一过程也是质量管理体系的支持过程。数据分析的作用包含推测或解释数据并确定如何使用数据、检查数据是否合法、为决策提供参考建议、诊断或推断错误原因以及预测未来等作用。
数据分析的方法主要分为单纯的数据加工方法、基于数理统计的数据分析、基于数据挖掘的数据分析以及基于大数据的数据分析。其中,单纯的数据加工方法包含描述性统计分析和相关分析;基于数理统计的数据分析包含方差、因子以及回归分析等;基于数据挖掘的数据分析包含聚类、分类和关联规则分析等;基于大数据的数据分析包含使用Hadoop、Spark和Hive等进行数据分析。
数据分析思路
我们通过使用基于分布式文件系统的Hive对某招聘网站的数据进行分析。
Hive是建立在Hadoop分布式文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。Hive可以将HQL语句转为MapReduce程序进行处理。
针对招聘网站的职位数据分析项目,我们将Hive数据仓库设计为星状模型,星状模型是由一张事实表和多张维度表组成。
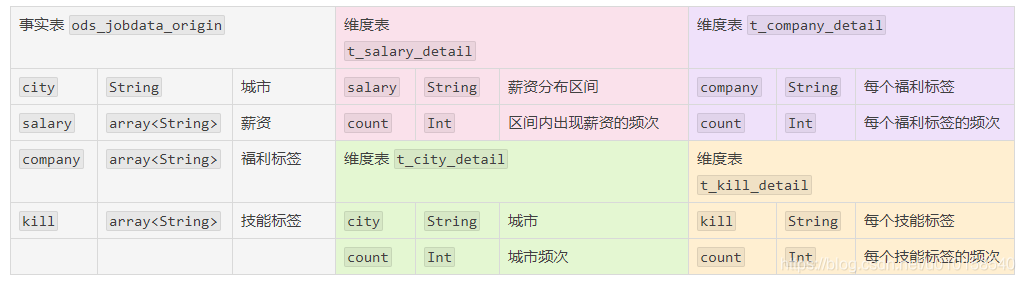
事实表 ods_jobdata_origin 主要用于存储 MapReduce 计算框架清洗后的数据,其表结构如下。
维度表 t_salary_detail 主要用于存储薪资分布分析的数据,其表结构如下。
维度表 t_company_detail 主要用于存储福利标签分析的数据,其表结构如下。
维度表 t_city_detail 的表结构主要用于存储城市分布分析的数据,其表结构如下。
维度表 t_kill_detail 的表结构主要用于存储技能标签分析的数据,其表结构如下。
建表数据处理
创建名为“jobdata”的数据仓库,并通过use指令切换到创建的数据库,命令如下。
hive (default)> create database jobdata;
hive (default)> use jobdata;
创建存储原始职位数据的事实表 ods_jobdata_origin,命令如下。
create table ods_jobdata_origin(
city string comment '城市',
salary array<string> comment '薪资',
company array<string> comment '福利',
kill array<string> comment '技能'
)comment '原始数据表'
row format delimited
fields terminated by ','
collection items terminated by '-';
将 HDFS 上的预处理数据导入到事实表 ods_jobdata_origin 中,命令如下:
hive (jobdata)> load data inpath '/lagou/output/part-r-00000' overwrite into table ods_jobdata_origin;
通过 select 语句查看表数据内容,验证数据是否导入成功,命令如下:
hive (jobdata)> select * from ods_jobdata_origin;
OK
ods_jobdata_origin.city ods_jobdata_origin.salary ods_jobdata_origin.company ods_jobdata_origin.kill
上海 ["10","13"] [] ["Oracle","SQL","hive","Cognos"]
上海 ["10","15"] ["带薪年假","岗位晋升","领导好","五险一金"] ["数据仓库","Hadoop","Spark","Hive"]
上海 ["10","18"] [] ["Spark"]
上海 ["10","18"] ["绩效奖金","五险一金","带薪年假","年度旅游"] ["Hadoop","Spark"]
上海 ["10","20"] ["通讯津贴","交通补助","双休","弹性工作"] ["自动化测试","系统软件测试","CDP"]
上海 ["12","18"] ["股票期权","绩效奖金","专项奖金","年底双薪"] ["数据仓库","Hadoop","MySQL"]
上海 ["12","20"] ["节日礼物","年底双薪","专项奖金","带薪年假"] ["DBA","数据仓库","MySQL","SQLServer"]
上海 ["12","20"] ["节日礼物","年底双薪","专项奖金","带薪年假"] ["数据仓库","DBA"]
招聘数据维度分析
职位薪资分析
根据最低薪资进行分区分组统计,并保存到
t_salary_detail表中。
create table t_salary_detail(
salary string comment '薪资分布区间',
count int comment '区间内出现薪资的频次'
)comment '薪资分布详情表'
row format delimited fields terminated by ',';
insert overwrite table t_salary_detail
select sal,count(1) from
(select
case
when salary[0] >=0 and salary[0]<=5 then '0-5'
when salary[0] >=6 and salary[0]<=10 then '6-10'
when salary[0] >=11 and salary[0]<=15 then '11-15'
when salary[0] >=16 and salary[0]<=20 then '16-20'
when salary[0] >=21 and salary[0]<=25 then '20-25'
when salary[0] >=26 and salary[0]<=30 then '26-30'
when salary[0] >=31 and salary[0]<=35 then '31-35'
when salary[0] >=36 and salary[0]<=40 then '36-40'
when salary[0] >=41 then '41+'
end as sal
from ods_jobdata_origin ) as t_sal
group by sal;
hive (jobdata)> select * from t_salary_detail;
OK
t_salary_detail.salary t_salary_detail.count
0-5 4
11-15 178
16-20 104
20-25 51
26-30 36
31-35 8
36-40 3
6-10 66
Time taken: 9.577 seconds, Fetched: 8 row(s)
通过观察分析结果,可以了解到全国大数据相关职位的月薪资分布主要集中在11k-20k之间,其中出现频次最高的月薪资区间在11k-15k。
职位区域分析
create table t_city_detail(
city string comment '城市',
count int comment '城市频次'
)comment '城市岗位统计详情表'
row format delimited fields terminated by ',';
hive (jobdata)> insert overwrite table t_city_detail select city,count(1) from ods_jobdata_origin group by city;
hive (jobdata)> select * from t_city_detail;
OK
t_city_detail.city t_city_detail.count
上海 91
佛山 4
北京 145
南京 2
南昌 1
合肥 3
天津 1
宁波 1
广州 50
成都 19
无锡 1
杭州 33
柳州 1
武汉 14
江门 1
济南 1
深圳 68
福州 1
苏州 2
西安 3
郑州 2
长沙 5
青岛 1
Time taken: 8.349 seconds, Fetched: 23 row(s)
大数据职位的需求主要集中在大城市,其中最多的是北京,其次分别是上海和深圳,一线城市(北上广深)占据前几名的位置,然而杭州这座城市对大数据职位的需求也很高,超越广州,次于深圳,阿里巴巴这个互联网巨头应该起到不小的带领作用。
公司福利分析
create table t_company_detail(
company string comment '福利标签',
count int comment '福利标签频次'
)comment '福利标签统计详情表'
row format delimited fields terminated by ',';
insert overwrite table t_company_detail
select company,count(1) from
(select explode(company) as company from ods_jobdata_origin) as t_company
group by company;
hive (jobdata)> select * from t_company_detail where count>2;
OK
t_company_detail.company t_company_detail.count
SaaS 4
专项奖金 36
两房一厅公寓 3
五险一金 85
交通补助 26
免费两餐 6
免费班车 25
六险一金 44
加班费 3
午餐补助 26
博士后工作站 3
双休 7
外企氛围 3
大牛云集 3
安居计划 4
完成E轮融资 3
定期体检 78
就近租房补贴 33
岗位晋升 50
带薪年假 158
年底双薪 68
年度旅游 31
年终分红 17
年终奖金 3
弹性工作 68
成长空间 3
扁平化管理 6
扁平管理 67
技能培训 62
极客氛围 3
福利产假 4
管理规范 12
绩效奖金 128
美女多 11
股票期权 59
节日礼物 63
通讯津贴 23
领导好 27
餐补 4
Time taken: 10.092 seconds, Fetched: 39 row(s)
通过观察福利标签的分析数据,可以看到公司对员工的福利政策都有哪些,出现频次较多的福利标签可以视为大多数公司对员工的标准,在选择入职公司时可作为一个参考。
职位技能要求分析
create table t_kill_detail(
city string comment '技能标签',
count int comment '技能标签频次'
)comment '技能标签统计详情表'
row format delimited fields terminated by ',';
insert overwrite table t_kill_detail
select kill,count(1) from
(select explode(kill) as kill from ods_jobdata_origin) as t_kill
group by kill;
hive (jobdata)> select * from t_kill_detail where count>2;
OK
t_kill_detail.company t_kill_detail.count
DBA 3
ETL 67
Flink 56
Hadoop 179
Hive 68
Java 55
Linux 4
MongoDB 10
MySQL 30
Oracle 7
Python 22
SQL 5
SQLServer 3
Scala 27
Spark 132
Storm 13
hbase 7
hive 4
java 4
python 4
sql 3
大数据 6
大数据开发 3
数仓工程师 17
数仓建模 42
数仓架构 32
数据仓库 106
数据分析 9
数据处理 3
数据库 4
数据库开发 19
数据挖掘 25
数据架构 13
架构师 4
测试 4
系统架构 3
Time taken: 8.469 seconds, Fetched: 36 row(s)
通过观察技能标签的分析数据,看到要从事大数据相关工作需要掌握哪些技能,这些需要掌握的技能前三名的占比达38%(前三名技能出现频次的总和/所有技能出现频次的总和),也就是说超过1/3的公司会要求大数据工作者需要掌握Hadoop、Spark和数据仓库这三项技能,对于想要从事这方面工作的读者,可以作为学习的参考与准备。
下一章 使用SSM进行数据操作,转换为Web数据方便ECharts数据呈现


















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











