









最近在写程序时候老出现中文乱码,查了下是编码标准没整对= w =、虽然很简单就解决了问题,但是对编码产生了兴趣,就翻了翻,咳咳发现还真不少,这里只介绍了知名度比较高的= = ,好无情= ^ =
先来张思维导图今天介绍的主要就是这些编码了
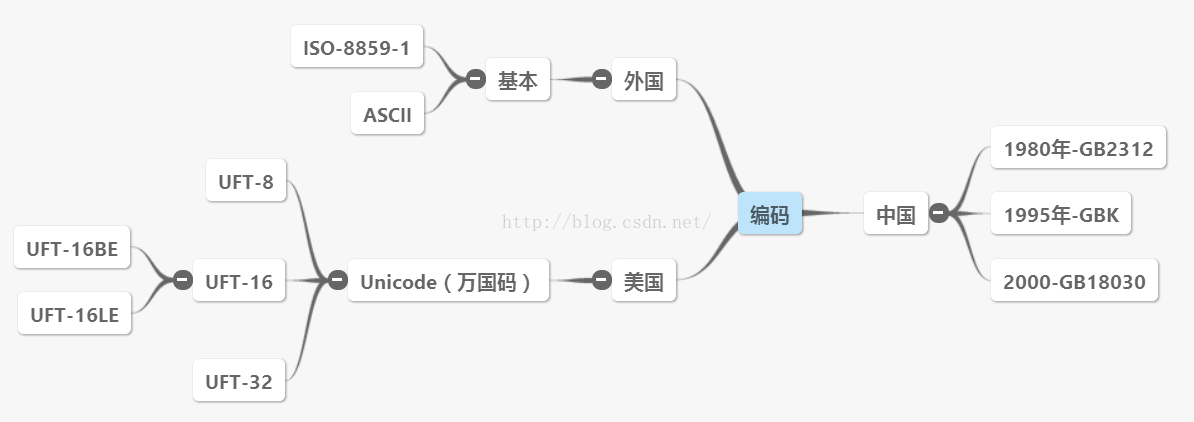
先说说中国的吧、中国的第一个编码是GB2312里面包含了汉字。。。对只有汉字,简单的说就是外国编码没有汉字或者搞得很不好用= =然后中国就出了个,不过只有繁体的.....然后很快1995年又出现了新生儿,GBK没错·,简体中文来了,简体中文来了!哇卡卡卡!不过这还不够,我们56个民族56朵花,怎么能少了少数民族。。。不!是其他民族的文字呢!所以伟大的GB18030就蹦出来了!出生于2000年3月17日,夜= =
自从计算机发展以来无人不知ASCII、又叫US-ASCII美国人发明的嘛= =加了个US来强调?!美国标注信息交换代码、几乎在所有类型计算机上都是标准的128字符集,后来经过扩展了128个字符集、扩展之后又叫IBM字符集= =
Unicode编码1994年公布= =、又称万国码,简单的说,他的使命就是表示各个国家的各种文字,每个文字都有唯一的表示码、简单地说就是解决了全国文字沟通问题= =
番外篇(有意思)
1,GB2312是很老的东西了,早就发现不够用了。
2,94年(还是之前)国家推出了建议性标准gb13000,这个标准其实就是utf-8标准(除了名字,完全一样),同时也建议微软公司采纳。--(据说是1993年,GB13000,应该是ISO10646)
3,微软借口说gb18000还不成熟,为了取得中国市场的垄断地位,自己搞了一套汉字标准,于是它就随着win95和office之类的流行起来了,国家看生米已经煮成了熟饭,只好把这套标准定为国标GBK标准。--(其实只是指导性标准,并非强制性,GB18030是强制性标准)
4,微软到了99年(前后吧),又说GBK已经落伍了,现在流行utf-8标准,准备全盘转换成utf-8,这些把有关部门惹怒了。NND,当年我们推utf-8你说不成熟,自己搞了一套,现在赚得盆满钵满了又自己说要推utf-8了,你丫微软分明就没把政府放在眼里。
5,于是政府怒了,强制推行gb18030标准(这个标准前面兼容GBK,其他码位兼容utf-8),算是过渡标准吧。要求微软强制执行,否则产品不得在大陆买。于是基本搞死了微软的WindowsMe,差点搞死了Office2000(据说发行前几个月,微软除了改字符编码就没干其他什么事情)--(确实,WinMe是我认为的最差的Windows版本,而office2k也是前不着村,后不着店,前后兼容性都差)
6,由于以上历史原因,现在就是GB2312,GBK,GB18030,UTF-8并存了。
7,如果不是万恶的微软,我们早就用上UTF-8了。
8,所以说微软和政府关系一直很僵,不是说着玩的,微软太目中无政府了。
9,以上是我从其他地方看来的,可能记得不是太真切了,说的不对请大家指正。
图= =

表格整理
| 编码标准 | 发明时间 | 发明国家 | 作用内容 | 简介 |
| ISO-8859-1 | 找不到 | ? | 各种外文 | 8位字符集,兼容 ASCII |
| GB2312 | 1980年发布
| 中国 | 繁体 | GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB 2312。 |
| GBK | 1995年12月15日发布 | 中国 | 繁体,简体 | GBK 向下与 GB 2312 编码兼容,向上支持 ISO 10646.1 国际标准,是前者向后者过渡过程中的一个承上启下的产物。 |
| GB18030 | 2000年 3月17日发布 | 中国 | 繁体,简体,中国各少数民族民族文字 | 我国自主研制的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准 |
| US-ASCII | 根据资料来看应该很早 | 美国标准信息交换代码 | 数字/英文 | 二进制/十六进制/用01表示数字和英文字母
(电脑)最基本的标准字符集,ASCII是“美国信息交换标准码”的英文缩写(American Standard Code for Information Interchange),ASCII字符集包含128个字符(7bits),它在几乎所有类型的计算机上都是标准的,每个ASCII字符使用一个字节表示,其取值范围在0至127之间,ASCII扩展字符集又称为IBM字符集,它在ASCII字符集的基础上,又定义了128个字符,取值范围在128至255之间,充分利用了一个字节所能表达的最大信息,Siebenbitcode |
| Unicode | 1990年开始研发,1994年正式公布 | ? | 能够使计算机实现跨语言、跨平台的文本转换及处理。 | 跨平台,每个国家的每种语言的每个文字都有编码,为解决编码统一、各个国家编码不相同,不兼容的问题 扩展自ASCII Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符,或者说有1114112个码位。码位就是可以分配给字符的数字。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。 在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“UCS Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。 例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是: char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8编码 char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16编码 char32_t data_utf32[]={0x00006C49,0x00005B57};//UTF-32编码 这里用char、char16_t、char32_t分别表示无符号8位整数,无符号16位整数和无符号32位整数。UTF-8、UTF-16、UTF-32分别以char、char16_t、char32_t作为编码单位。 |
| UFT-8 | 由Ken Thompson于1992年创建 | 美国计算机学者Ken Thompson | UTF-8编码可以通过屏蔽位和移位操作快速读写。 | 基于Unicode,外文名 8-bit Unicode Transformation Format Unicode转换格式
|
| UFT-16 |
| Unicode扩展 | 对每一个Unicode码位使用恰好16位元
| UTF-16是Unicode的其中一个使用方式。 UTF是 Unicode Translation Format,即把Unicode转做某种格式的意思。 即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。 (是高字节在前还是低字节在前)由流中的前两字节中字节顺序标记来确 |
| UFT-16BE |
| Unicode扩展 |
| 与UFT-16字节顺序不同 (最低地址存放高位字节,符合人们的阅读习惯)字节顺序 只有UTF-16,即只有使用Unicode编码存储或传递时,才涉及到高字节还是低字节序的问题,UTF-8一般是没有字节序的概念的,因为utf-8编码本身中就已含有了编解码转换方式了。 |
| UFT-16LE |
| Unicode扩展 |
| 与UFT-16字节顺序不同 (最高地址存放高位字节)字节顺序 |
| UFT-32 |
| Unicode扩展 | 对每一个Unicode码位使用恰好32位元 | UTF-32 (或 UCS-4)是一种将Unicode字符编码的协定,对每一个Unicode码位使用恰好32位元。其它的Unicode transformation formats则使用不定长度编码。因为UTF-32对每个字符都使用4字节,就空间而言,是非常没有效率的。特别地,非基本多文种平面的字符在大部分文件中通常很罕见,以致于它们通常被认为不存在占用空间大小的讨论,使得UTF-32通常会是其它编码的二到四倍。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。 |
呼呼累死宝宝了= =
————————————chenchen—————————————















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









