






linux用户使用资源限制
前言:linux是一个遵循POSIX的多用户、多任务、支持多线程和多CPU的操作系统。但凡是多用户的操作系统,对管理员来说就会有不小的麻烦。笔者举个工作中遇到的例子,多名同事在同一台共享开发的服务器(毕竟服务器相较于普通的计算机性能上要强很多)进行编译工作,但是有位同事在家目录中生成了一个量级很大的数据,而家目录并不是单独划分的磁盘空间,而是在根目录下划分的,直接导致系统盘满了,系统直接崩溃了。最后只能申请到公司机房连上显示器,键盘鼠标删除后,才恢复使用。再举个例子,为了赶开发进度,每天都要制作很多demo数据进行功能验证,结果大家经常互相抢占系统资源,谁也无法按时完成进度。
所以对用户进行必有的资源限制,往往更有利于用户的正常使用
1. 概述
Linux用户资源限制通常涉及以下几类:
- 进程数限制:限制用户可以启动的进程数量。
- 文件描述符数限制:限制用户可以打开的文件描述符的数量。
- CPU使用时间限制:限制用户的进程可以使用的CPU时间。
- 虚拟内存限制:限制用户进程可以使用的虚拟内存总量。
- 物理内存限制:限制用户进程可以使用的物理内存总量。
- 磁盘空间限制:限制用户可以使用的磁盘空间量。
- 文件权限限制:限制用户可以访问的目录。
按照资源级别限制又可分为:
- 系统级限制
- 内核级别限制
- 应用软件级别的限制
下面笔者将对普通用户jacky和nancy进行资源限制,用于示例展示
示例目的:对以往的权限及限制相关知识回顾整理,尽可能帮助我们在复杂及定制的管理场景提前做好准备
本次操作系统为Centos7
[root@node-252 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@node-252 ~]# useradd jacky
[root@node-252 ~]# passwd jacky
[root@node-252 ~]# useradd nancy
[root@node-252 ~]# passwd nancy
[root@node-252 ~]# mkdir /workspace/develop -p
这里我们创建了联合开发目录/workspace/develop
2. 特殊权限(SUID,SGID,SBIT)
这里的特殊权限指SUID,SGID,SBIT
SUID
我们知道使用SUID权限的前提是文件必须是二进制文件,所以我们拷贝了passwd来进行演示
[root@node-252 develop]# cp /usr/bin/passwd .
#切换用户
[jacky@node-252 develop]$ ./passwd
Changing password for user jacky.
Changing password for jacky.
(current) UNIX password:
New password:
Retype new password:
passwd: Authentication token manipulation error
#SUID
[root@node-252 develop]# chmod 4745 passwd
[root@node-252 develop]# ll
-rwsr--r-x 1 root root 27856 Jun 21 11:36 passwd
#切换用户
[jacky@node-252 develop]$ ./passwd
Changing password for user jacky.
Changing password for jacky.
(current) UNIX password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
当我们未对passwd赋予SUID的时候,jacky没有办法修改自己密码。当我们对passwd授予SUID后,jacky可以以passwd的属主(即root)权限执行修改密码。当我们的联合开发目录中有特殊二进制文件需要以属主的权限运行时,SUID是很有用的。
SGID
SGID使用在文件上,普通用户将获得属组的权限支持,这里不演示了
SGID使用在目录上,普通用户创建的文件的属组将是该目录属组的权限,当然普通用户需要有权限进入该目录创建文件
mkdir share
chmod 2775 share/
chmod o+w share/
total 28
-rwxr--r-x 1 root root 27856 Jun 21 11:36 passwd
drwxrwsrwx 2 root root 18 Jun 21 11:53 share
#切换到jacky
[jacky@node-252 share]$ touch file
[jacky@node-252 share]$ chmod o-r file
[jacky@node-252 share]$ ll
total 0
-rw-rw---- 1 jacky root 0 Jun 21 11:53 file
#切换到nancy
[nancy@node-252 develop]$ cd share/
[nancy@node-252 share]$ ll
total 0
-rw-rw---- 1 jacky root 0 Jun 21 11:53 file
[nancy@node-252 share]$ cat file
cat: file: Permission denied
#nancy加到dev组中
[root@node-252 develop]# usermod -g dev nancy
[root@node-252 develop]# id nancy
uid=1002(nancy) gid=1003(dev) groups=1003(dev)
#nancy注销后登陆
[nancy@node-252 share]$ ll
total 0
-rw-rw---- 1 jacky dev 0 Jun 21 12:01 file
[nancy@node-252 share]$ cat file
[nancy@node-252 share]$
jacky在共享目录中创建的开发文档,只有本组的人才能查看哦
SBIT
粘滞位,只对目录有效,当用户对目录有写入(至少wx)权限时,在其内创建的目录和文件,只有自己和root可以删除或修改哦
[root@node-252 develop]# mkdir test
[root@node-252 develop]# chmod 1743 test
[root@node-252 develop]# ll
total 28
-rwxr--r-x 1 root root 27856 Jun 21 11:36 passwd
drwxrwsrwx 2 root dev 18 Jun 21 13:23 share
drwxr---wt 2 root root 6 Jun 21 13:41 test
#切换jacky
[jacky@node-252 develop]$ cd test/
[jacky@node-252 test]$ ll
ls: cannot open directory .: Permission denied
[jacky@node-252 test]$ echo "123" > 123
#切换nancy
[nancy@node-252 test]$ ll
ls: cannot open directory .: Permission denied
[nancy@node-252 test]$ echo "456" >123
-bash: 123: Permission denied
#切换jacky
[jacky@node-252 test]$ echo "456" >123
[jacky@node-252 test]$ cat 123
456
3. 访问控制列表(ACL)
ACL 是 Access Control List 的缩写,主要的目的是在提供传统的 owner,group,others 的read,write,execute 权限之外的细部权限设定。ACL 可以针对单一使用者,单一文件或目录来进行r,w,x 的权限规范,对于需要特殊权限的使用状况非常有帮助。
主要的命令:
getfacl:获取aclsetfacl:设置acl
关于命令可以参考:https://blog.csdn.net/u010230019/article/details/132269498
我们开了一个新项目acldir,jacky是项目内人员,而nancy并不是。通过普通的权限设置,或者特殊权限很难区分对待这两位同事了。此时,我们可以通过setfacl区别对待。
[root@node-252 test]# mkdir acldir
[root@node-252 test]# chmod 744 acldir/
[root@node-252 test]# echo "acltest" > acldir/aclfile
[root@node-252 develop]# getfacl acldir/
# file: acldir/
# owner: root
# group: root
user::rwx
group::r--
other::r--
[root@node-252 develop]# getfacl acldir/aclfile
# file: acldir/aclfile
# owner: root
# group: root
user::rw-
group::r--
other::r--
[root@node-252 develop]# ll acldir/
total 4
-rw-r--r-- 1 root root 8 Jun 21 13:54 aclfile
目前看起来并没有什么不同
[jacky@node-252 develop]$ ll acldir/
ls: cannot access acldir/aclfile: Permission denied
total 0
-????????? ? ? ? ? ? aclfile
[jacky@node-252 develop]$ ll acldir/aclfile
ls: cannot access acldir/aclfile: Permission denied
[jacky@node-252 develop]$ cat acldir/aclfile
cat: acldir/aclfile: Permission denied
[nancy@node-252 develop]$ ll acldir/
ls: cannot access acldir/aclfile: Permission denied
total 0
-????????? ? ? ? ? ? aclfile
[nancy@node-252 develop]$ cat acldir/aclfile
cat: acldir/aclfile: Permission denied
接下来,我们对jacky单独设置权限
[root@node-252 develop]# setfacl -m u:jacky:rwx acldir/
[root@node-252 develop]# getfacl acldir/
# file: acldir/
# owner: root
# group: root
user::rwx
user:jacky:rwx
group::r--
mask::rwx
other::r--
#切换jacky
[jacky@node-252 develop]$ ll
total 28
drwxrwxr--+ 2 root root 21 Jun 21 13:54 acldir
-rwxr--r-x 1 root root 27856 Jun 21 11:36 passwd
drwxrwsrwx 2 root dev 18 Jun 21 13:23 share
drwxr---wt 2 root root 17 Jun 21 13:54 test
[jacky@node-252 develop]$ ll acldir/aclfile
-rw-r--r-- 1 root root 8 Jun 21 13:54 acldir/aclfile
[jacky@node-252 develop]$ cat acldir/aclfile
acltest
#切换
[nancy@node-252 develop]$ ll acldir/
ls: cannot access acldir/aclfile: Permission denied
total 0
-????????? ? ? ? ? ? aclfile
[nancy@node-252 develop]$ cat acldir/aclfile
cat: acldir/aclfile: Permission denied
setfacl也可以对组进行权限设定g:组名:权限,掩码设定m:权限,这里不进一步演示了
4. 磁盘空间限制(quota)
支持磁盘配额的文件系统
- XFS文件系统:XFS是一个高性能的日志文件系统,被广泛用于企业级存储解决方案。XFS文件系统原生支持磁盘配额,包括用户配额、组配额和目录级别的配额(Project Quota)。
- EXT4文件系统:EXT4是EXT3文件系统的后继者,并增加了许多新的特性和改进。虽然EXT4本身并不直接支持磁盘配额,但可以通过Linux内核的quota模块和额外的工具(如quota)来支持用户和组配额。
磁盘配额的类型(用户配额、组配额)
-
用户配额(User Quota):
用户配额是针对单个用户的磁盘空间使用限制。系统管理员可以为每个用户单独设置磁盘容量的软限制和硬限制,以及文件数量的软限制和硬限制。
当用户的磁盘使用量或文件数量超过软限制但未达到硬限制时,系统通常会发出警告(如记录日志或发送通知),但并不会阻止用户的进一步操作。然而,一旦用户的磁盘使用量或文件数量达到或超过硬限制,系统将禁止用户进行任何可能导致超出限制的操作。 -
组配额(Group Quota):
组配额是针对一组用户的磁盘空间使用限制。当用户数量较多时,单独为用户设置配额可能会变得繁琐。此时,可以将用户组织到用户组中,并为整个用户组设置配额限制。
组中的用户将共享该组的配额空间。这意味着,如果给某个用户组分配了200MB的磁盘空间,那么该组中的所有用户将共同使用这200MB的空间。一旦整个组的磁盘使用量达到或超过其配额限制,组中的任何用户都将无法进行任何可能导致超出限制的操作。
Linux磁盘配额的实现过程
-
配额类型和限制:
磁盘容量(块配额):限制用户或组可以使用的磁盘块(通常是512字节或4KB的块)的数量。
文件数量(inode配额):限制用户或组可以拥有的文件(包括目录)的数量。 -
设置配额:
系统管理员使用特定的命令(如xfs_quota、edquota等)为用户或组设置配额限制。这些命令允许管理员设置软限制(用户可以超过但会收到警告)和硬限制(用户不能超过,否则操作将失败)。 -
文件系统的支持:
并非所有Linux文件系统都支持配额。常见的支持配额的文件系统有XFS、ext4(需要额外的内核支持和工具)等。
当文件系统被挂载时,需要指定支持配额的选项(如usrquota、grpquota),以便系统能够跟踪用户和组的磁盘使用情况。 -
配额的检查:
当用户尝试写入文件或创建新文件时,系统会检查该用户的配额。
如果用户的磁盘使用量或文件数量超过了软限制但尚未达到硬限制,系统通常会记录警告信息(如写入日志)但不会阻止操作。
如果用户的磁盘使用量或文件数量超过了硬限制,系统将阻止进一步的写入操作,并可能向用户显示错误消息。 -
配额报告和监控:
系统管理员可以使用各种命令和工具来报告和监控用户和组的配额使用情况。这些工具允许管理员查看哪些用户或组接近或超过其配额限制,并采取适当的措施。 -
配额的灵活性:
配额设置可以在运行时更改,无需重新启动系统或卸载文件系统。
管理员可以为用户或组设置不同的配额限制,以满足不同的需求。
示例
下面我们在虚拟机新增一块磁盘,并设置为ext4文件系统。ext4只能对分区级别进行配额限制,目录不支持哦
fdisk /dev/sdb
mkfs.ext4 /dev/sdb1
mkdir /mnt/sdb
mount /dev/sdb1 /mnt/sdb/
vim /etc/fstab
reboot
开启硬盘配额选项
[root@node-252 ~]# tail -1 /etc/fstab
/dev/sdb1 /mnt/sdb ext4 defaults,usrquota,grpquota 0 0
[root@node-252 ~]# mount |grep /dev/sdb1
/dev/sdb1 on /mnt/sdb type ext4 (rw,relatime,quota,usrquota,grpquota,data=ordered)
使用quotacheck工具扫描文件系统并创建配额文件
[root@node-252 workspace]# quotacheck -cug /mnt/sdb
[root@node-252 tmp]# ll /mnt/sdb/
total 36
-rw------- 1 root root 6144 Jun 21 16:55 aquota.group
-rw------- 1 root root 6144 Jun 21 16:55 aquota.user
使用edquota设置用户和组的配额:
[root@node-252 sdb]# edquota -u jacky
Disk quotas for user jacky (uid 1001):
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 0 200M 300M 1 0 0
#生效后
Disk quotas for user jacky (uid 1001):
Filesystem blocks soft hard inodes soft hard
/dev/sdb1 307200 204800 307200 1 0 0
启用配额限制
[root@node-252 sdb]# quotaon -ugv /dev/sdb1
/dev/sdb1 [/mnt/sdb]: group quotas turned on
/dev/sdb1 [/mnt/sdb]: user quotas turned on
我们向/mnt/sdb分别拷贝不同大小的文件
#限额内文件
[jacky@node-252 sdb]$ dd if=/dev/zero of=/mnt/sdb/s25 count=25 bs=1024k
25+0 records in
25+0 records out
26214400 bytes (26 MB) copied, 0.0168181 s, 1.6 GB/s
#超出软限制的文件
[jacky@node-252 sdb]$ dd if=/dev/zero of=/mnt/sdb/s25 count=250 bs=1024k
sdb1: warning, user block quota exceeded.
250+0 records in
250+0 records out
262144000 bytes (262 MB) copied, 1.28626 s, 204 MB/s
#超出硬限制的文件
[jacky@node-252 sdb]$ dd if=/dev/zero of=/mnt/sdb/s25 count=350 bs=1024k
sdb1: warning, user block quota exceeded.
sdb1: write failed, user block limit reached.
dd: error writing ‘/mnt/sdb/s25’: Disk quota exceeded
301+0 records in
300+0 records out
314572800 bytes (315 MB) copied, 2.4966 s, 126 MB/s
[jacky@node-252 sdb]$ ll -h
total 301M
-rw------- 1 root root 7.0K Jun 21 16:55 aquota.group
-rw------- 1 root root 7.0K Jun 21 17:05 aquota.user
drwx----w- 2 root root 16K Jun 21 14:56 lost+found
-rw-r--r-- 1 jacky dev 300M Jun 21 17:24 s25
drwxr-xrwx 4 root root 4.0K Jun 21 15:06 workspace
[jacky@node-252 sdb]$ dd if=/dev/zero of=/mnt/sdb/s26 count=50 bs=1024k
dd: error writing ‘/mnt/sdb/s26’: Disk quota exceeded
1+0 records in
0+0 records out
0 bytes (0 B) copied, 0.00056518 s, 0.0 kB/s
用户可以进行低于硬限制高于软限制的文件拷贝,但是高于硬限制的拷贝只能拷贝最大限制的size,即总限额。当该用户限额用尽,则无法再进行拷贝了。
查询用户限额
[jacky@node-252 sdb]$ quota -uv jacky
Disk quotas for user jacky (uid 1001):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb1 307200* 204800 307200 6days 2 0 0
可以看到grace宽限期字段,当用户使用的空间超过soft,低于hard,quota会给予用户一个宽限时间用来处理超出限额的数据,如果过期未处理,quota会把超出的空间回收,保留软限制的限额。以本例说,就是超过宽限期后,quota会把用户的300M文件删到200M为止。
修改宽限期
[root@node-252 mnt]# edquota -t -f /dev/sdb1
Grace period before enforcing soft limits for users:
Time units may be: days, hours, minutes, or seconds
Filesystem Block grace period Inode grace period
/dev/sdb1 7days 7days
类似于对用户磁盘限额,还可以对组进行限额,命令包括
edquota -g jacky
以下是一些常用的quota命令:
| 命令 | 说明 |
|---|---|
| quota -u 用户名 | 显示指定用户的磁盘配额情况。 |
| quota -v 用户名 | 显示指定用户的详细磁盘配额情况。 |
| quota -s 用户名 | 显示指定用户的软磁盘配额限制。 |
| quota -g 组名 | 显示指定组的磁盘配额情况。 |
| repquota -a | 显示所有用户的磁盘配额总结。 |
| edquota -u 用户名 | 编辑指定用户的磁盘配额限制。 |
| quotaon -u 用户名 | 启用指定用户的磁盘配额限制。 |
| quotaoff -u 用户名 | 关闭指定用户的磁盘配额限制。 |
请注意,quota命令可能需要管理员权限才能运行。在编辑或设置用户配额时,确保配额设置合理,以免造成磁盘空间不足的问题。
ext4只能对分区级别进行配额限制,目录不支持哦。这个点相对xfs系统确实不足,如果是xfs可以参考下网络上的文章
5. 进程资源限制
5.1 ulimit
ulimit命令是Linux系统中用于控制shell程序的资源限制的命令。它可以用来设置和查看各种资源限制,包括最大文件大小、最大进程数、最大打开文件数等等。这些设置可以通过ulimit命令来修改,并且可以在启动脚本中设置默认值。命令行修改只能对当前shell生效,当重新打开shell,则不生效
ulimit [-HSTabcdefilmnpqrstuvx [limit]]
options are interpreted as follows:
-a All current limits are reported
-b The maximum socket buffer size
-c The maximum size of core files created
-d The maximum size of a process's data segment
-e The maximum scheduling priority ("nice")
-f The maximum size of files written by the shell and its children
-i The maximum number of pending signals
-l The maximum size that may be locked into memory
-m The maximum resident set size (many systems do not honor this limit)
-n The maximum number of open file descriptors (most systems do not allow this value to be set)
-p The pipe size in 512-byte blocks (this may not be set)
-q The maximum number of bytes in POSIX message queues
-r The maximum real-time scheduling priority
-s The maximum stack size
-t The maximum amount of cpu time in seconds
-u The maximum number of processes available to a single user
-v The maximum amount of virtual memory available to the shell and, on some systems, to its children
-x The maximum number of file locks
-T The maximum number of threads
ulimit命令的主要作用是提高系统的性能和稳定性。通过合理地设置资源限制,可以防止因过度使用系统资源而导致系统崩溃或性能下降。例如,通过设置最大文件大小的限制,可以避免同时打开过多的文件导致系统崩溃;通过设置最大虚拟内存的限制,可以避免进程占用过多的内存导致系统变慢。
ulimit的限制分为硬限制和软限制,硬限制使用-H参数,软限制使用-S参数。
- 软限制可以限制用户/组对资源的使用,硬限制的作用是控制软限制。硬限制设定后,设定软限制时只能是小于或等于硬限制。
- 超级用户和普通用户都可以扩大硬限制,但超级用户可以缩小硬限制,普通用户则不能缩小硬限制.
- 如果ulimit不限定使用-H或-S,此时它会同时把两类限制都改掉的.
[root@node-249 ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14989
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 14989
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@node-249 ~]# ulimit -a -H
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 14989
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 4096
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) unlimited
cpu time (seconds, -t) unlimited
max user processes (-u) 14989
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
ulimit -a命令用于显示当前系统的所有资源限制,包括最大文件大小、最大进程数、最大打开文件数等等。下面是各个参数的含义:
core file size (blocks, -c):核心文件的大小限制,即当程序崩溃时生成的核心转储文件的最大大小。
data seg size (kbytes, -d):数据段的大小限制,即每个进程可以使用的内存大小。
scheduling priority (-e):调度优先级,即进程在CPU时间片分配时的优先级。
file size (blocks, -f):文件的大小限制,即单个文件的最大大小。
pending signals (-i):挂起的信号数量,即当前等待处理的信号的数量。
max locked memory (kbytes, -l):最大锁定内存量,即一个进程最多可以占用的内存大小。
max memory size (kbytes, -m):最大内存大小,即系统允许一个进程使用的最大内存量。
open files (-n):打开的文件数限制,即一个进程最多可以同时打开多少个文件。
pipe size (512 bytes, -p):管道大小限制,即一个进程可以通过管道发送或接收的数据的最大大小。
POSIX message queues (bytes, -q):POSIX消息队列的大小限制,即一个进程可以拥有的最大消息队列的大小。
real-time priority (-r):实时优先级,即进程在紧急情况下可以获得CPU时间片的优先级。
stack size (kbytes, -s):栈大小限制,即一个进程可以使用的栈空间大小。
cpu time (seconds, -t):CPU时间限制,即一个进程最多可以使用CPU的时间长度。
max user processes (-u):最大用户进程数限制,即一个用户可以创建的最大进程数。
virtual memory (kbytes, -v):虚拟内存大小限制,即系统允许一个进程使用的虚拟内存总量。
file locks (-x):文件锁的数量限制,即一个进程最多可以拥有的文件锁的数量。
为了使ulimit参数永久生效,需要在配置文件/etc/security/limits.conf中设置ulimit值,采用以下形式
cat /etc/security/limits.conf
......
#<domain> <type> <item> <value>
#
#* soft core 0
#* hard rss 10000
#@student hard nproc 20
#@faculty soft nproc 20
#@faculty hard nproc 50
#ftp hard nproc 0
#@student - maxlogins 4
......
参数说明:
[domain]
an user name
a group name, with @group syntax
the wildcard *, for default entry
the wildcard %, can be also used with %group syntax, for maxlogin limit
[type]
#可以有两个类型
“soft” for enforcing the soft limits
“hard” for enforcing hard limits
[item]
core – limits the core file size (KB)
data – max data size (KB)
fsize – maximum filesize (KB)
memlock – max locked-in-memory address space (KB)
nofile – max number of open files
rss – max resident set size (KB)
stack – max stack size (KB)
cpu – max CPU time (MIN)
nproc – max number of processes
as – address space limit (KB)
maxlogins – max number of logins for this user
maxsyslogins – max number of logins on the system
priority – the priority to run user process with
locks – max number of file locks the user can hold
sigpending – max number of pending signals
msgqueue – max memory used by POSIX message queues (bytes)
nice – max nice priority allowed to raise to values: [-20, 19]
rtprio – max realtime priority
要使limits.conf的更改立即生效,通常需要重新登录或者重启系统,以确保所有进程都已根据新的限制重新配置。
示例:
- 限制进程产生的文件大小(fsize)
[root@node-249 ~]# ulimit -f 100
[root@node-249 ~]# dd if=/dev/zero of=./test/newfile count=10 bs=1024K
File size limit exceeded
命令行修改只能对当前shell生效,当重新打开shell,则不生效
[root@node-249 ~]# dd if=/dev/zero of=./test/newfile count=10 bs=1024K
10+0 records in
10+0 records out
10485760 bytes (10 MB) copied, 1.92841 s, 5.4 MB/s
永久生效
[root@node-254 /]# grep yurq /etc/security/limits.conf
yurq soft fsize 100
[yurq@node-254 ~]$ dd if=/dev/zero of=./test count=10 bs=1024k
File size limit exceeded
[yurq@node-254 ~]$ dd if=/dev/zero of=./test count=10 bs=1k
10+0 records in
10+0 records out
10240 bytes (10 kB) copied, 0.000271714 s, 37.7 MB/s
- 进程打开文件的限制(open files)
[yurq@node-254 ~]$ ulimit -n 3
[yurq@node-254 ~]$ cat /etc/passwd
-bash: start_pipeline: pgrp pipe: Too many open files
cat: error while loading shared libraries: libc.so.6: cannot open shared object file: Error 24
关闭shell后失效,永久生效
[root@node-254 /]# tail /etc/security/limits.conf
...
yurq soft fsize 100
yurq soft nofile 3
# End of file
[root@node-254 /]# su - yurq
su: cannot open session: System error
这种情况很糟糕,能打开的文件受限,甚至无法切换用户。一定要设置合理的最大文件描述符
- 限制可创建进程数量最大限制
[yurq@node-254 ~]$ ulimit -u 3
[yurq@node-254 ~]$ bash
-bash: fork: retry: No child processes
-bash: fork: retry: No child processes
常用的限制内容:
- 1、进程打开的文件数量限制(ulimit -n)
限制进程能够同时打开的文件数量。
示例:一个服务器程序需要同时处理多个客户端连接,每个连接都会占用一个文件描述符。如果文件描述符的数量限制过低,程序可能会因无法打开新连接而出现错误。
* soft nofile 1024
* hard nofile 4096
这个地方,笔者曾经在自己的虚拟机测试,把root的打开文件限制100,导致卡在登录界面,反复输入账号密码,还使用救援模式也没能解决,后来登录别的账号,拷贝文件的时候发现,无法拷贝,受限了,这才想起来当初自己干的好事
- 2、进程内存使用限制(ulimit -m)
限制进程在内存中使用的最大字节数。
示例:一个图像处理应用可能会加载大量的图像文件。如果内存使用限制过低,应用可能会因内存不足而崩溃。
* soft as 512000
* hard as 1024000
- 3、进程CPU时间限制(ulimit -t)
限制进程可以使用的CPU时间(以秒为单位)。
示例:一个计算密集型任务如果运行时间过长,可能会占用大量的CPU资源。通过设置CPU时间限制,可以防止这样的任务过度使用CPU
* soft cpu 300
* hard cpu 600
- 4、进程堆栈大小限制(ulimit -s)
限制进程堆栈的大小。
示例:递归深度较大的程序可能会耗尽堆栈空间,导致栈溢出错误。设置堆栈大小限制可以帮助防止这种情况。
* soft stack 8192
* hard stack 16384
- 5、进程可打开文件的最大大小限制(ulimit -f)
限制进程可以创建的最大文件大小(以块为单位)。
示例:日志记录程序可能会生成非常大的日志文件。通过设置文件大小限制,可以防止日志文件占用过多磁盘空间。
* soft fsize 1048576
* hard fsize 2097152
- 6、进程最大用户进程数限制(ulimit -u)
限制进程可以创建的最大用户进程数。
示例:一个恶意程序可能会创建大量子进程,消耗系统资源。通过设置用户进程数限制,可以防止这种情况。
* soft nproc 1024
* hard nproc 2048
- 7、进程最大线程数限制(ulimit -i)
限制进程可以创建的最大线程数。
示例:多线程应用程序可能会创建大量线程。通过设置线程数限制,可以防止线程过多导致的资源耗尽。
* soft maxlogins 10
* hard maxlogins 50
5.2 cgroup
参考 https://www.cnblogs.com/menkeyi/p/10941843.html
Linux 资源限制控制组(cgroups)是 Linux 内核的特性,它允许将任务进一步分割成更小的组,并对每个组应用资源限制(如 CPU 使用时间、内存使用量、磁盘 I/O 等)。
- CGroup 一般也被称为“cgroups”,是 control groups 的简称。
- CGroup 机制的功能就是对 linux 的一组进程进行包括 CPU、内存、磁盘 IO、网络等在内的资源使用进行限制、管理和隔离。
主要功能:
- 限制资源的使用,如划定内存等资源的使用上限,对文件系统的缓存进行限制等;
- 优先级控制,如让进程以低优先级被 CPU 调度等;
- 审计和统计,例如统计 CPU 使用的比例等;
- 挂起进程和恢复进程执行。
cgroups 子系统
CGroup 对进程组资源的限制是通过子系统来实现的,这样做的好处是可以便于新的功能的增加。目前已有的子系统有:
cpu 子系统:主要限制进程的 cpu 使用率。
cpuacct 子系统:可以统计 cgroups 中的进程的 cpu 使用报告。
cpuset 子系统:可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
memory 子系统:可以限制进程的 memory 使用量。
blkio 子系统:可以限制进程的块设备 io。
devices 子系统:可以控制进程能够访问某些设备。
net_cls 子系统:可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
net_prio 子系统:这个子系统用来设计网络流量的优先级
freezer 子系统:可以挂起或者恢复 cgroups 中的进程。
ns 子系统:可以使不同 cgroups 下面的进程使用不同的 namespace
hugetlb 子系统:这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
cgroups 层级结构(Hierarchy)
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。
cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。
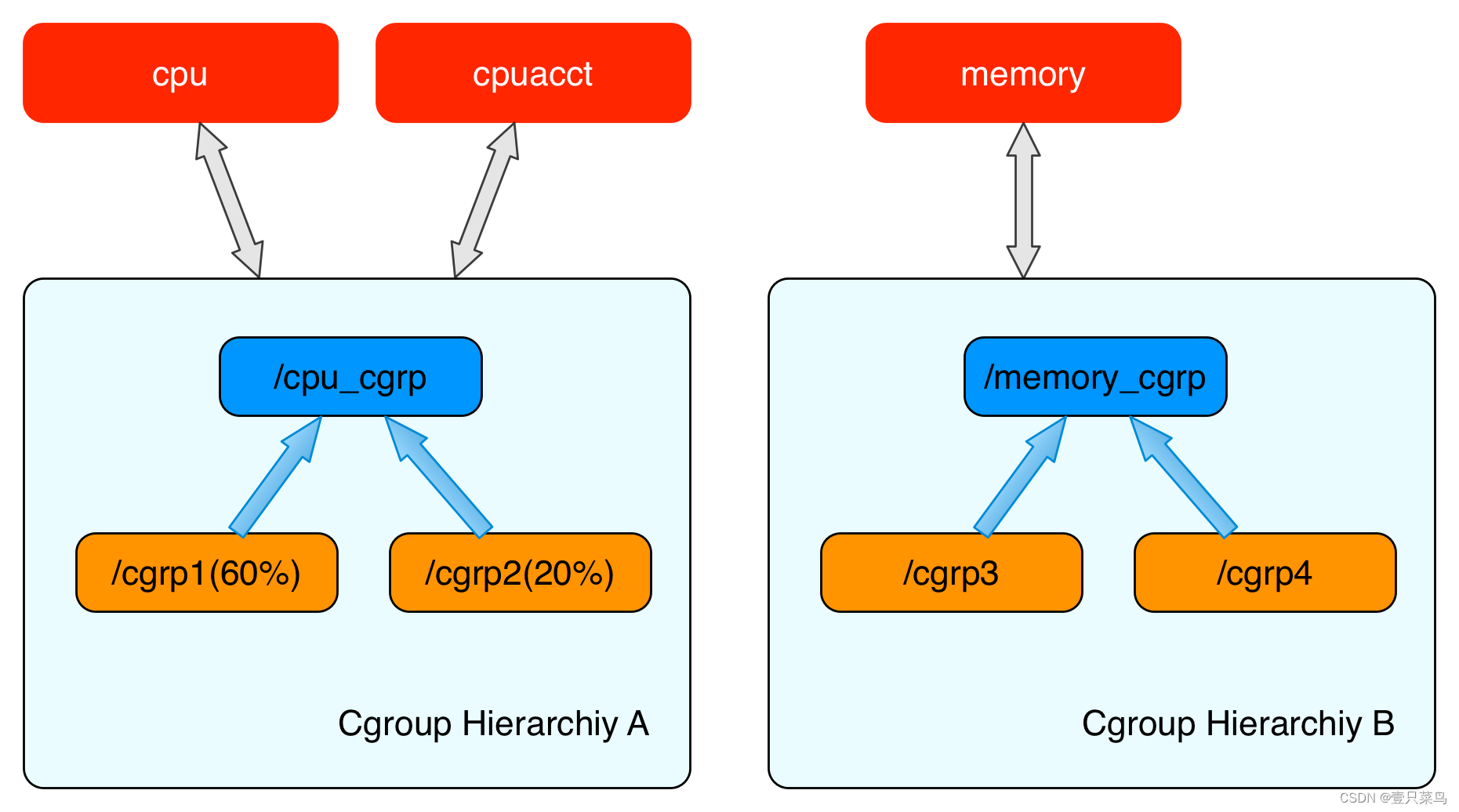
创建了 cgroups 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
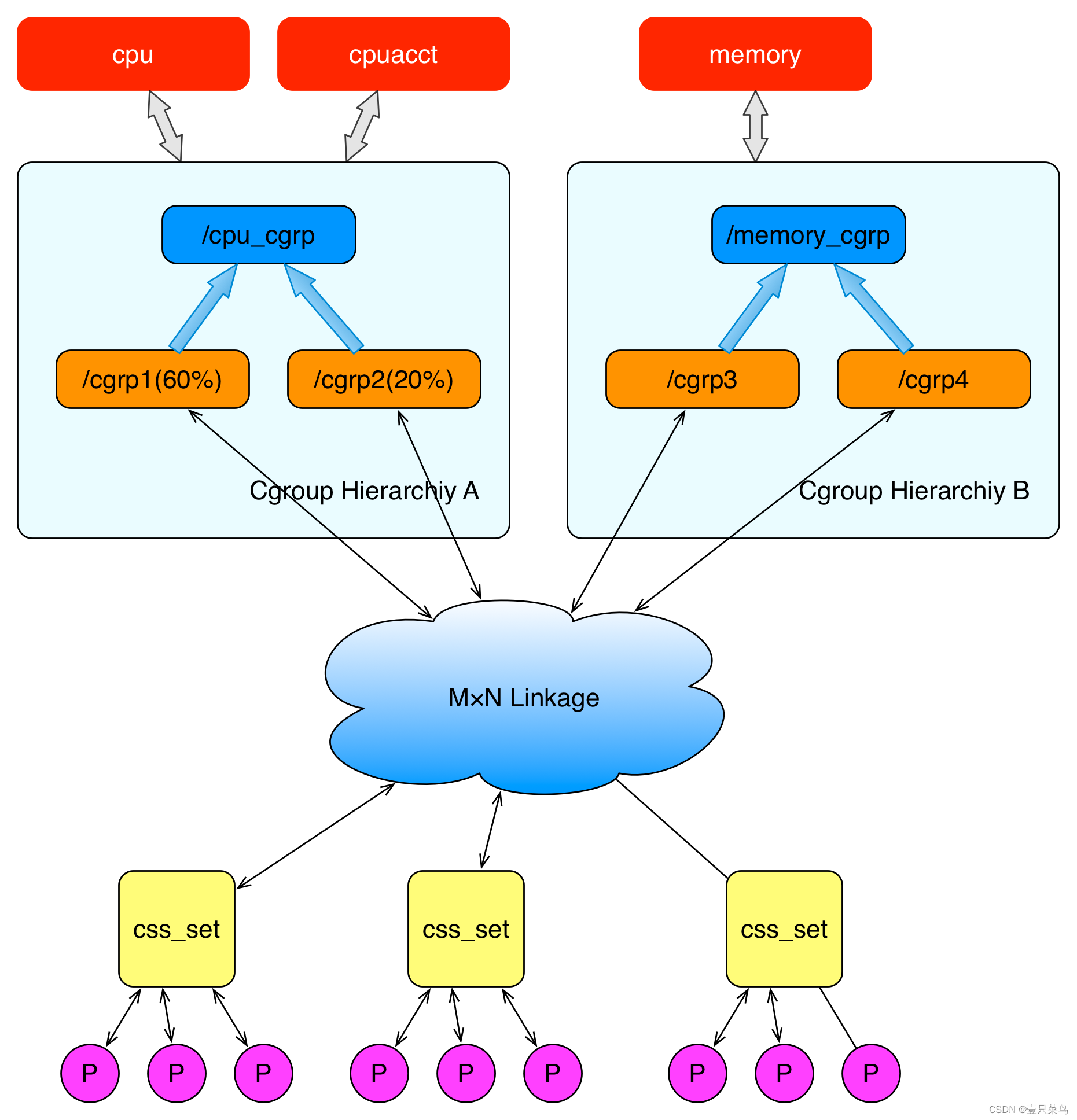
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
查看cgroup挂载点
[root@node-254 test_cpu_limit]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
示例
创建隔离组
[root@node-254 tmp]# cd /sys/fs/cgroup/cpu
[root@node-254 cpu]# mkdir test_cpu_limit
目录创建完成会自动生成以下文件
[root@node-254 cpu]# ll test_cpu_limit/
total 0
-rw-r--r-- 1 root root 0 Jun 25 16:28 cgroup.clone_children
--w--w--w- 1 root root 0 Jun 25 16:28 cgroup.event_control
-rw-r--r-- 1 root root 0 Jun 25 16:28 cgroup.procs
-r--r--r-- 1 root root 0 Jun 25 16:28 cpuacct.stat
-rw-r--r-- 1 root root 0 Jun 25 16:28 cpuacct.usage
-r--r--r-- 1 root root 0 Jun 25 16:28 cpuacct.usage_percpu
-rw-r--r-- 1 root root 0 Jun 25 16:28 cpu.cfs_period_us
-rw-r--r-- 1 root root 0 Jun 25 16:29 cpu.cfs_quota_us
-rw-r--r-- 1 root root 0 Jun 25 16:28 cpu.rt_period_us
-rw-r--r-- 1 root root 0 Jun 25 16:28 cpu.rt_runtime_us
-rw-r--r-- 1 root root 0 Jun 25 16:28 cpu.shares
-r--r--r-- 1 root root 0 Jun 25 16:28 cpu.stat
-rw-r--r-- 1 root root 0 Jun 25 16:28 notify_on_release
-rw-r--r-- 1 root root 0 Jun 25 16:28 tasks
cpu耗尽脚本
[yurq@node-254 ~]$ cat mem.py
#!/usr/bin/python
if __name__=='__main__':
i=1
while(i):
i+=1
运行脚本
top - 16:51:22 up 5:03, 4 users, load average: 0.16, 0.05, 0.06
Tasks: 133 total, 2 running, 131 sleeping, 0 stopped, 0 zombie
%Cpu(s): 25.0 us, 0.2 sy, 0.0 ni, 74.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2851488 total, 1545508 free, 345800 used, 960180 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2212708 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
126812 yurq 20 0 123460 4480 1960 R 100.0 0.2 0:10.12 python
1 root 20 0 51768 4016 2608 S 0.0 0.1 0:04.59 systemd
默认-1不限制,现在改成20000,可以理解使用率限制在20%
[root@k8s-master cpu]# echo 20000 > /sys/fs/cgroup/cpu/cpu_test/cpu.cfs_quota_us
找到进程号增加到cpu tasks里面,在看top cpu使用率很快就下来
[root@k8s-master ~]# echo 126812 >> /sys/fs/cgroup/cpu/cpu_test/tasks
top - 16:52:36 up 5:04, 4 users, load average: 0.68, 0.24, 0.12
Tasks: 133 total, 3 running, 130 sleeping, 0 stopped, 0 zombie
%Cpu(s): 5.0 us, 0.2 sy, 0.0 ni, 94.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2851488 total, 1545728 free, 345580 used, 960180 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 2212928 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
126812 yurq 20 0 123460 4480 1960 R 19.9 0.2 1:20.26 python
127320 root 20 0 113288 1592 1336 S 0.3 0.1 0:00.02 bash
持续更新~~~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









