







Trie中文名又叫做字典树,前缀树等,因为其结构独有的特点,经常被用来统计,排序,和保存大量的字符串,经常见于搜索提示,输入法文字关联等,当输入一个值,可以自动搜索出可能的选择。当没有完全匹配的结果时,可以返回前缀最为相似的可能。
其实腾讯的面试题有一个:如何匹配出拼写单词的正确拼写。其实用匹配树非常合适。
基本性质:
1.根节点不含有字符,其余各节点有且只有一个字符。
2.根节点到某一节点中经过的节点存储的值连接起来就是对应的字符串。
3.每一个节点所有的子节点的值都不应该相同。
借用一下维基百科上的一张图片:
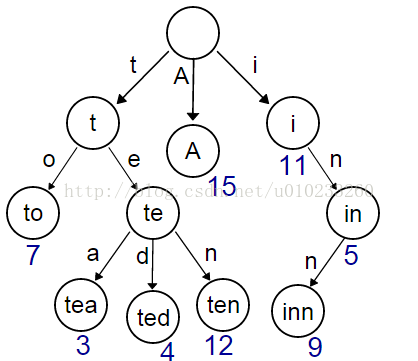
看图还是蛮好理解的。但是我们应该怎么操作呢。
应为英文有26个字母,所以每个单词的每个位置都可能有26种取法,因此,我们可以为每个节点去26个子节点:
public class TrieNode {
public static final int NUM_OF_LETTER = 26;
private TrieNode[] childNodes = new TrieNode[NUM_OF_LETTER];
private int freg;
private boolean isEnd;
private char varChar;
/**
* @param words
* @return 不可用返回true 否则为可用
*/
private static boolean checkWordsLenght(char[] words) {
return (words.length == 0) || (words == null);
}
public static void addNode(TrieNode root, char[] words) {
if (checkWordsLenght(words)) {
return;
}
int index = words[0] - 'a';
if (root.childNodes[index] == null) {
root.childNodes[index] = new TrieNode();
root.childNodes[index].varChar = words[0];
}
root.childNodes[index].freg++;
words = Arrays.copyOfRange(words, 1, words.length);
if (checkWordsLenght(words)) {
root.isEnd = true;
return;
}
addNode(root.childNodes[index], words);
}
public static void deleteNode(TrieNode root, char[] words) {
if (checkWordsLenght(words) || (root == null)) {
return;
}
int index = words[0] - 'a';
if (root.childNodes[index] == null) {
return;
}
root.childNodes[index].freg--;
if (root.childNodes[index].freg == 0) {
root.childNodes[index] = null;
}
words = Arrays.copyOfRange(words, 1, words.length);
if (checkWordsLenght(words)) {
root.childNodes[index] = null;
}
deleteNode(root.childNodes[index], words);
}
public static int getCountOfWords(TrieNode root, char[] words) {
if (checkWordsLenght(words) || (root == null)) {
return 0;
}
int index = words[0] - 'a';
if (root.childNodes[index] == null) {
return 0;
}
words = Arrays.copyOfRange(words, 1, words.length);
if (checkWordsLenght(words)) {
return root.freg;
}
return getCountOfWords(root.childNodes[index], words);
}
}















 8711
8711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









