







首先先上一段代码:
public class PropertiesTest {
public static void main(String[] args) {
System.out.println("file.encoding:"+System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding:"+System.getProperty("sun.jnu.encoding"));
// Properties pro = System.getProperties();
// Set<Entry<Object,Object>> entrySet = pro.entrySet();
// for(Entry<Object,Object> entry :entrySet){
// System.out.println(entry.getKey()+":"+entry.getValue());
// }
}
}那么java中的file.encoding属性和sun.jnu.encoding属性到底是什么?从哪里来?干什么用?网上查了查,其中大多语焉不详,不清不楚,于是决定自己动手,来一探究竟。
咱们首先来看这两个属性干什么用。毕竟先知道它们有什么用才有必要关心它们从哪里来。
来看看我在eclipse中运行上面代码的结果:
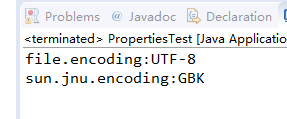
再来看一段代码:
import java.io.UnsupportedEncodingException;
public class PropertiesTest {
public static void main(String[] args) throws UnsupportedEncodingException {
System.out.println("file.encoding:" + System.getProperty("file.encoding"));
System.out.println("sun.jnu.encoding:" + System.getProperty("sun.jnu.encoding"));
encodingTest();
}
private static void encodingTest() throws UnsupportedEncodingException {
String s = "我们是中国人";
//如果使用不带参数的getBytes()肯定不会乱码的
byte[] bytes = s.getBytes("utf-8");
String s2 = new String(bytes);
System.out.println(s2);
}
}

运行结果如图:中文打印正常

修改getBytes()为getBytes("utf-8"),结果中文依然正常
再次修改为:getBytes("GBK"),结果中文显示乱码:

这样看来,似乎默认的编码就是UTF-8,为了进一步证明猜想,我们来跟踪一下源码:
public byte[] getBytes() {
return StringCoding.encode(value, 0, value.length);
}static byte[] encode(char[] ca, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name encode() variant which provides caching.
return encode(csn, ca, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
try {
return encode("ISO-8859-1", ca, off, len);
} catch (UnsupportedEncodingException x) {
// If this code is hit during VM initialization, MessageUtils is
// the only way we will be able to get any kind of error message.
MessageUtils.err("ISO-8859-1 charset not available: "
+ x.toString());
// If we can not find ISO-8859-1 (a required encoding) then things
// are seriously wrong with the installation.
System.exit(1);
return null;
}
}public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}知道了作用,并且作用不小,那我们来看看到底是什么决定了file.encoding属性。
(PS:通常情况下为了保证程序run everywhere并且保持运行结果一致,不建议在程序中使用默认编码,应该直接指定编码)。
网上很多人给出的答案是:main方法所在类文件的编码决定了file.encoding属性。
我们来验证一下:
选中Explorer区域的类文件或将光标置于类文件编辑页,alt+enter打开类文件的属性页,可以看到我的设置
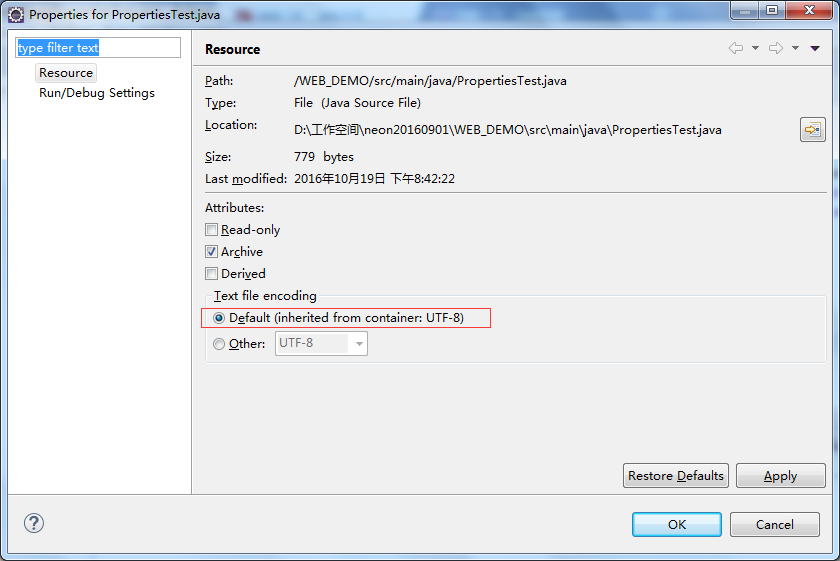
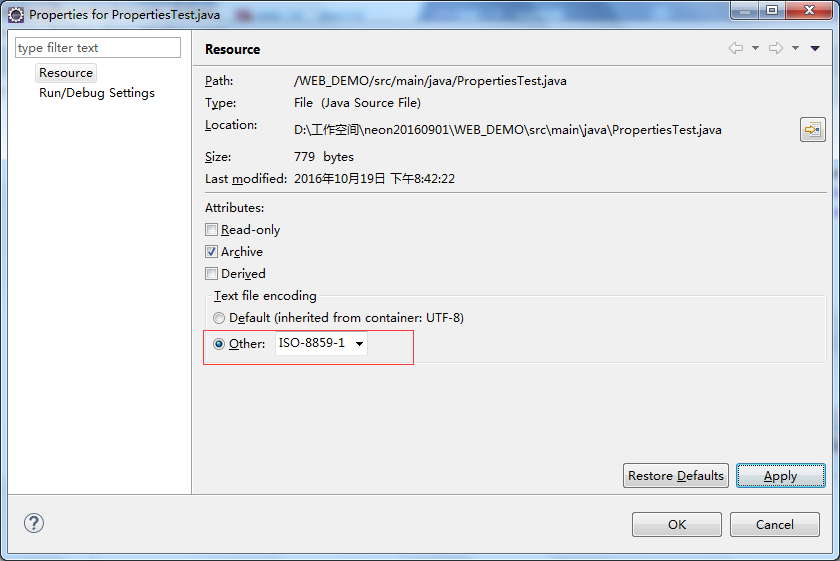
确实是utf-8,所以之前我的file.encoding属性就是utf-8了,现在修改该属性,
修改完成后,毫无疑问,中文都乱码了,运行程序,看看运行结果:
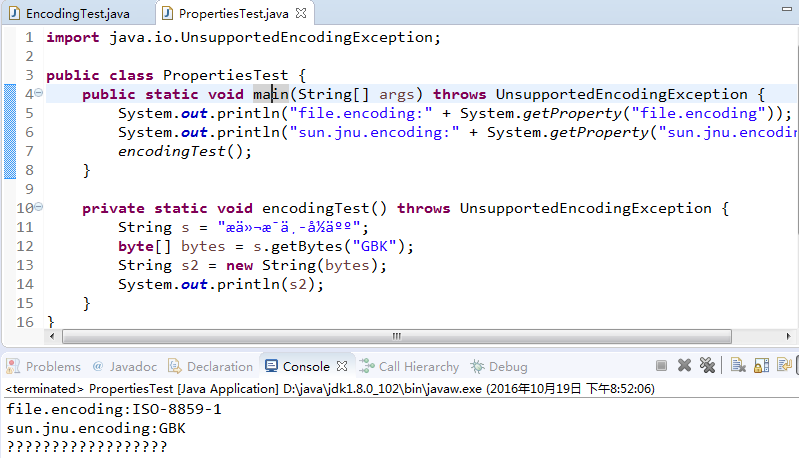
果然,file.encoding属性变成“ISO-8859-1”了。
再修改设置,改成US-ASCII,执行后果然file.encoding属性的值就变成了”US-ASCII“。
那么结论就是:file.encoding的属性值就是main方法所在类文件的编码。网友们果然机智。
但是,这样就可以下结论了吗?
我们现在是通过eclipse执行,就像隔靴搔痒,总感觉差点意思。要真正李菊福,还是要到控制台去。
将文件改回utf-8编码,消除文件中的中文乱码,getBytes和new String(bytes)依然使用不带编码的默认编码形式,接着我们直接在控制台编译并执行代码:

奇怪的现象出现了,和第一次在eclipse中执行的是一样的代码,但是运行结果居然变了,file.encoding的值变成了”GBK“,可是main方法所在类的编码明明是“UTF-8”。还有中文乱码了。这都是什么情况??
乱码一会儿再说,先看file.encoding的变化,file.encoding变成”GBK“了,而文件的编码是utf-8才对,这样看来,之前所谓的结论似乎并不靠谱。
我们继续尝试在运行时直接指定file.encoding的属性,加上运行时参数”-Dfile.encoding=utf-8“:

这次file.encoding的值变了,变成了utf-8,说明file.encoding确实可以被设置,我们在设置一个不存在编码名试试看:

好吧,这都行,并且乱码始终没有变化。到这里我们可以看出:file.encoding可以设置为任意值。并且这次乱码问题不是出在file.encoding属性上。
到这里,我们就可以猜测,在eclipse中,之所以file.encoding属性和main方法所在类的编码一致,是因为在启动java虚拟机时,eclipse自动将文件属性中的编码设置为运行时参数。
我们知道一个文件是以二进制形式存储在硬盘中的,我们先以utf-8编码存储了java文件,然后手动javac,因为我们并没有指定编码,这时系统是不知道用什么编码来解析文件的,所以只能采用系统默认编码(这个是windows系统的默认编码,和之前提到的JVM默认编码不是一回事),我们查看windows的默认编码:

这里936表示默认编码为GBK。
那么显然问题就出在这里,文件以utf-8编码保存,如果以GBk解析,不乱码才怪呢。于是增加编译参数”-encoding utf-8“,重新编译运行:

可以看到,运行时file.encoding值依然为GBK,但是不乱码了,说明乱码确实是编译过程中引入的,运行过程没有问题。
我们可以通过以下方式再次验证,回到eclipse,我们试着修改一下代码,并重新运行:
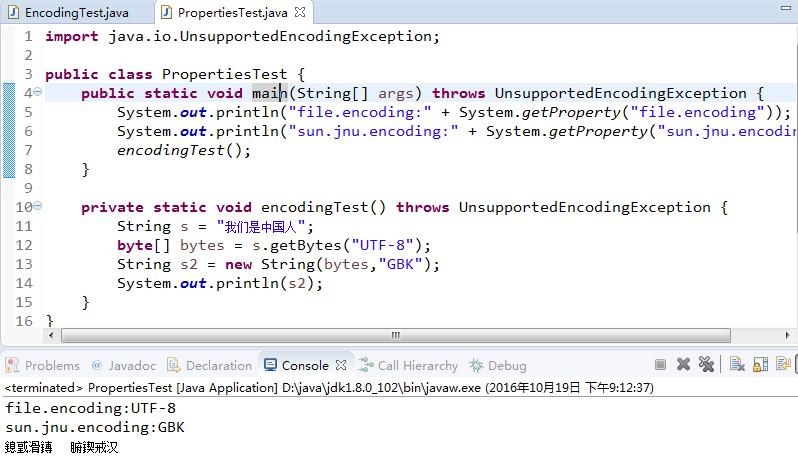
可以看到此时的乱码和上面的一样。证明”鎴戜滑鏄腑鍥戒汉“确实是由于”我们是中国人“以utf-8格式保存,以GBK读取所致。
只不过在之前这个错误发生在编译过程中,编译完成后字符串就已经变成”鎴戜滑鏄腑鍥戒汉“。运行过程中没有问题。
而这一次,eclipse的编译没问题。不过在程序中将”我们是中国人“先以utf-8转成字节,再以GBk转换成字符串,同样产生了乱码。
由此,我们可以猜测,eclipse在编译和运行的过程中都会默认地帮我们添加上相应的编码参数,这个参数和main方法所在类的编码一致。

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









