






算得上是打发发送到发发水电费第三方
asdasdasdasdas
sadsad
asdasdsadasdas
asdasdasad啊
xczc
xzcxzc
czxcxzc
zxczxc
zxczxc
czx
zczxc
zczx
cxcxz
zcxczxc
z
zxczxc
czxczx
zxczx
zcxzczxc
zxczxczxczx
zczxcxczcxzcxzcxzczxczxc
作者:码云 Gitee
链接:https://www.zhihu.com/question/50212423/answer/250263597
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
谢邀,码云 Gitee (最新独立域名)是由开源中国出品,旨在树立国内代码托管和协作开发的行业标杆,灵活便捷地支撑个人、团队、企业的开发需求的产品。本文将从“码云的由来”、“码云与 GitHub 的区别”、“码云的愿景”等多方面来的剖析,来让大家更全面的了解和评价码云。
1. 码云 Gitee 的由来
在题主对问题的描述中,将码云看作为中文版的 GitHub ,其实两者是有区别的。美国有Facebook 和 Twitter,我们也有新浪微博,并成功打造的新的媒体生态,上到国家管理下到个人表达都因为微博产生了深远影响。新事物的出现总是因为新需求的产生,本土开发者们对于开源软件的需求逐年递增,大家需要更方便的展示、交流和协作,这也是码云能走向市场并扎根立足的根本原因。
上线四年,得到两百多万用户的认可,年均增长率 149%,近三百万开源项目,年均增长率 171%,这一事实也许比前面的话更有说服力。
关于“码云”产品名称,指代的是“代码”和“云平台/云服务”,和我们的核心功能非常贴合,只可惜和大佬有些撞衫…不过名字只是代号,真正的价值、美感往往需要实际的接触和了解——就像人与人的关系。
2. 本土开发者需求的特殊性
开源无国界,行业的进步依靠着每一位开发者的贡献。中国的政治、经济、文化在近二十年来得到了飞速发展,IT 行业更是如此,立足于本土国情的开发者们,在开源软件上的需求有没有自身的特殊性呢?答案是肯定的。
- 首先,在语言的使用上,当然中文交流更畅快、更有效率;
- 其次,国内 IT 行业有自己的特点,天然决定了对开源软件的需求也有自己的特点,比如小程序这个东西,只有国内有,做个开源的小程序托管在码云比 GitHub 明显更有优势,因为关注着都是国内的开发者;又或者说做个用平板练毛笔字的开源项目,当然也是更多的适合本土环境。
- 然后,开源不仅仅是大项目,像 OpenStack、Tensorflow 这样的大厂大作,确实有 GitHub 就够了,但是这样的大型项目毕竟不是普遍情况。现在编程越来越普及,每个人都可以参与和贡献开源项目,去做一些有意思的东西分享出来,那么从受众、交流便利度、访问速度等方面,码云都有优势,并且也在不断地优化用户体验。
3.码云与 GitHub 的区别在哪里?
码云和 GitHub 社区版之间的区别,如果简单粗暴的回答,那就是码云的私有库也是完全免费的。
这当然不是个轻松的决定,市场上其他产品,都把私有库作为收费服务提供,码云则通过提供企业版这条产品线,作为增值服务——这似乎也是水到渠成的决定:
- 一来已在代码托管服务方面积累多年,大大小小的问题都经历过,耐造、稳定;
- 二来我们的 geek 团队对协作开发也积累了很多经验和思考,“工欲善其事必先利其器”。
没有足够好的团队协作开发工具,那就做一个。项目管理、代码管理、文档协作一站解决,最重要的是,一切都围绕代码而存在,产品规划好、任务分解好,开发接了任务码好代码,直接通过 Pull Request (PR)通知测试和审查人员,直接对比代码版本变化、充分讨论,PR 通过后任务直接关闭……是的,前所未有的流畅。
企业版方面,码云和 GitHub 的区别,首先是定位,然后定位的差异会具化在功能侧重和提供方式上:
- GitHub for business 仍然是立足于代码托管功能,上下游的功能主要通过集成其他服务提供商而实现(当然,这也是生态使然);
- 码云 企业版 则针对国内中小型开发团队敏捷开发实践需要,除了代码托管功能之外,重点强化了与代码联系最密切的项目/任务管理和文档功能(技术文档协作、知识沉淀),以及持续集成(内测阶段)。以原生的方式提供功能,尽管研发投入大,但能够带来更整体、更流畅的使用体验,值得。
4.码云的愿景
我们希望能够为国内开源生态的建立和发展贡献一些力量,这是愿景、是初心,带着显著的开源中国的基因。我们更清楚地知道,只有不断地通过打磨产品、优化服务,才可以让用户认同、让市场认同,才可以真正守住初心、实现愿景。
经过四年多的发展,码云也逐渐探索出了自己的社区版 + 企业版的道路:
提供更好的代码托管平台,让更多的国内开发者参与开源,更方便地展示、交流和提升;
为开发团队打造更专业的云端协作开发平台,让协作开发更流畅和高效。
5.码云和 GitHub 并不是一种非此即彼的选择
立足国内,融入国际是每一位开发者应该有的格局,在 GitHub 上有全球各地的优秀人才,可以学习最新的知识,了解最前沿的技术;在码云上有百万级优秀的本土开发者,他们的开源项目不仅解决了行业问题,也给自己职业生涯增光添彩,更帮助了许多国内正在接触开源技术的新人们。
并且,码云一直致力于扶植有价值的开源项目的成长,例如现在GVP计划,众多优秀的本土开源项目都托管在码云,zheng、JFinal、Nuts、t-io 、tiny、贝密游戏、iBase4J 等。
同时也让他们分享自己的经验和意见,例如进击的程序员系列;
更积极的展现国内丰富多样的开发者风采,例如封面人物系列;
另付 码云和开源中国的区别详细说明,不得不看噢;
这些都代表着码云为本土开发者服务的诚心,如果你对码云有任何意见建议,欢迎吐槽留言:)
赞同 11675 条评论
分享
收藏喜欢收起
chengxuyuan
44 人赞同了该回答
私有免费。。感恩
赞同 445 条评论
分享
收藏喜欢
stylelint核心开发人员
35 人赞同了该回答
我来说说为啥不用码云吧。
缺乏生态,比如找不到针对码云的CI服务代码覆盖率服务,如我喜欢用的:
- codecov
- coveralls
- travis-ci
- appveyor
- circleci
上面这些服务在GitHub上使用非常之方便,可针对PR配置为构建失败/掉覆盖率不允许合并。
Sonar服务呢,又不适合前端技术栈,这倒不是码云的问题,是Sonar这种一个文件对应一种语法,且不能自定义规则的设定,不被前端社区接受。总之呢,我的感受是,找不到杀手级的,码云独有的功能。
最根本的问题是,GitHub的大神数量碾轧码云,国际化的场所,意味着更多的优秀开发者汇聚于此,这里更方便跟前辈学习。
赞同 3518 条评论
分享
收藏喜欢
广告
不感兴趣知乎广告介绍
一直使用个人域名邮箱是一种什么体验?
腾讯云域名专场特惠,注册.com仅23元/年,注册.cn仅16元/年。腾讯云新老用户都可购买,每个用户限购5个,点击查看更多后缀查看详情
知乎用户
14 人赞同了该回答
Gitee和Github的免费版的比较:
Gitee: 私有仓库容量500M, 所有仓库总容量5G; 公有仓库容量1G, 所有仓库总容量5G.
Github: 私有仓库无限容量...... 公有仓库无限容量......
赞同 148 条评论
分享
收藏喜欢
一名coder
4 人赞同了该回答
访问速度挺快的,但是开源的项目量有一些少,不过只要做的好的话,慢慢的用的人多起来,项目量自然也能多起来
赞同 41 条评论
分享
收藏喜欢收起
知乎用户
6 人赞同了该回答
能托管私人代码,非常不错,感恩!
赞同 6添加评论
分享
收藏喜欢收起
知乎用户
2 人赞同了该回答
挺好用,用了好几年了。
希望pull request的code diff能像gitlab一样牛逼。 现在gitee的code diff简直不能看。
赞同 2添加评论
分享
收藏喜欢收起
IT
3 人赞同了该回答
老舒服了!再也不用自己架svn了 感觉整个人都萌萌哒!
不过从svn转git的版本控制还是需要成本的,毕竟两种不同的策略
赞同 3添加评论
分享
收藏喜欢收起
运维,linux,开发。
1 人赞同了该回答
界面很友好,比github顺眼一点,但是jekyll的自动部署貌似不太好用。
赞同 11 条评论
分享
收藏喜欢收起
分享你刚编的故事
19 人赞同了该回答
不支持码云,要是人人都用码云。国家就敢名正言顺的墙了GitHub
赞同 1916 条评论
分享
收藏喜欢收起
广告
不感兴趣知乎广告介绍
深圳定制全屋家具要花多少钱?输入面积,10秒获取报价!
结算价格和报价相差大,感觉被坑?用心挑选的家具,最后却风格杂乱?只注重颜值,忽视了收纳空间?尚品宅配全屋家具定制,透明报价+风格设计+专业扩容,输入面积就能拿报价,来试试查看详情
相关问题
git是什么?github又是什么?他们都有什么用啊? 9 个回答不会git就学不会github吗? 16 个回答我们可以使用 Git 以及 GitHub 做哪些事情? 22 个回答如何快速入门git和github? 15 个回答Git 跟 GitHub 是什么关系? 41 个回答
相关推荐
刘看山知乎指南知乎协议知乎隐私保护指引
应用工作申请开通知乎机构号
侵权举报网上有害信息举报专区
京 ICP 证 110745 号
京 ICP 备 13052560 号 - 1
京公网安备 11010802010035 号
互联网药品信息服务资格证书
(京)- 非经营性 - 2017 - 0067违法和不良信息举报:010-82716601
儿童色情信息举报专区
证照中心
联系我们 © 2020 知乎
想来知乎工作?请发送邮件到 jobs@zhihu.com
一个synchronized跟面试官扯了半个小时
拍拍贷风控技术专家
关注 Wx 公众号【安琪拉的博客】 —揭秘 Java 后端技术,还原技术背后的本质 \ 《安琪拉与面试官二三事》系列文章 持续更新中 一个 HashMap 能跟面试官扯上半个小时 一个 synchronized 跟面试官扯了半个小时 \ 《安琪拉教鲁班学算法》系列文章
前言
话说上回 HashMap 跟面试官扯了半个小时之后,二面迎来了没有削弱前的钟馗,法师的钩子让安琪拉有点绝望。钟馗穿着有些微微泛黄的格子道袍,站在安琪拉对面,开始发难,其中让安琪拉印象非常深刻的是法师的 synchronized 钩子。
开场
面试官: 你先自我介绍一下吧!
安琪拉: 我是安琪拉,草丛三婊之一,最强中单(钟馗冷哼)!哦,不对,串场了,我是**,目前在--公司做--系统开发。
面试官: 刚才听一面的同事说你们上次聊到了 synchronized,你借口说要回去补篮,现在能跟我讲讲了吧?
安琪拉: 【上来就丢钩子,都不寒暄几句,问我吃没吃】嗯嗯,是有聊到 synchronized。
面试官: 那你跟我说说为什么会需要 synchronized?什么场景下使用 synchronized?
安琪拉: 这个就要说到多线程访问共享资源了,当一个资源有可能被多个线程同时访问并修改的话,需要用到锁,还是画个图给您看一下,请看👇图:
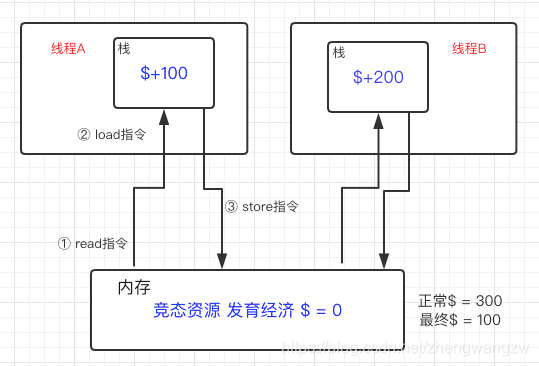
安琪拉: 如上图所示,比如在王者荣耀程序中,我们队有二个线程分别统计后裔和安琪拉的经济,A 线程从内存中 read 当前队伍总经济加载到线程的本地栈,进行 +100 操作之后,这时候 B 线程也从内存中取出经济值 + 200,将 200 写回内存,B 线程刚执行完,后脚 A 线程将 100 写回到内存中,就出问题了,我们队的经济应该是 300, 但是内存中存的却是 100,你说糟不糟心。
面试官: 那你跟我讲讲用 synchronized 怎么解决这个问题的?
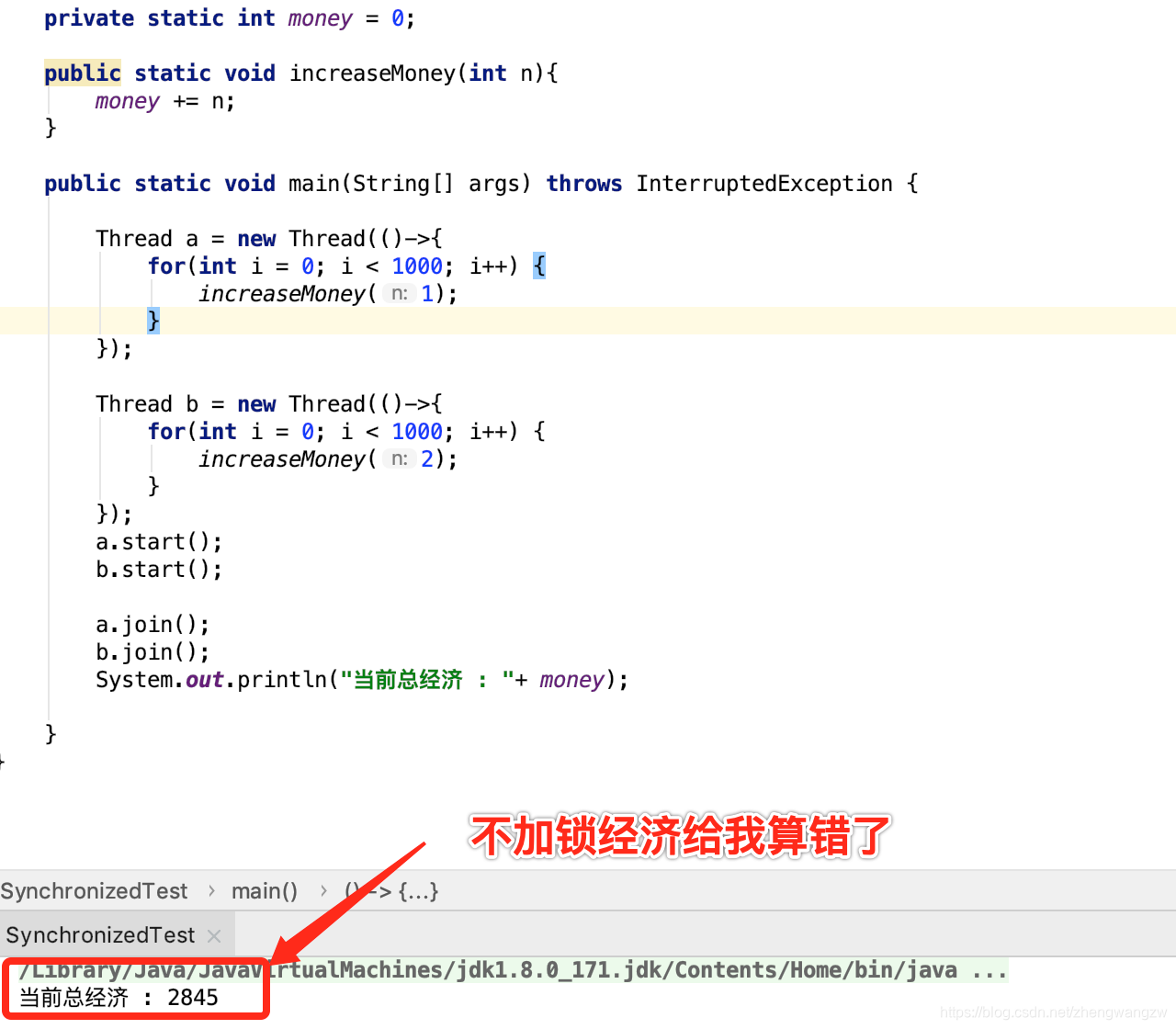
安琪拉: 在访问竞态资源时加锁,因为多个线程会修改经济值,因此经济值就是竞态资源,给您 show 一下吧?下图是不加锁的代码以及控制台的输出,请您过目:
二个线程,A 线程让队伍经济 +1 ,B 线程让经济 + 2,分别执行一千次,正确的结果应该是 3000,结果得到的却是 2845。
安琪拉: 👇这个就是加锁之后的代码和控制台的输出。
![(img-6NwdhDEz-1585279691724)(/Users/zw/Library/Application Support/typora-user-images/image-20200321210555529.png)]](https://img-blog.csdnimg.cn/20200327113120878.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3poZW5nd2FuZ3p3,size_16,color_FFFFFF,t_70)
面试官: 我看你👆用 synchronized 锁住的是代码块,synchronized 还有别的作用范围吗?
安琪拉: 嗯嗯,synchronized 有以下三种作用范围:
-
在静态方法上加锁;
-
在非静态方法上加锁;
-
在代码块上加锁;
示例代码如下
public class SynchronizedSample {
private final Object lock = new Object();
private static int money = 0;
//非静态方法
public synchronized void noStaticMethod(){
money++;
}
//静态方法
public static synchronized void staticMethod(){
money++;
}
public void codeBlock(){
//代码块
synchronized (lock){
money++;
}
}
}
面试官: 那你了解 synchronized 这三种作用范围的加锁方式的区别吗?
安琪拉: 了解。首先要明确一点:锁是加在对象上面的,我们是在对象上加锁。
重要事情说三遍:在对象上加锁 ✖️ 3 (这也是为什么 wait / notify 需要在锁定对象后执行,只有先拿到锁才能释放锁)
这三种作用范围的区别实际是被加锁的对象的区别,请看下表:
| 作用范围 | 锁对象 |
|---|---|
| 非静态方法 | 当前对象 => this |
| 静态方法 | 类对象 => SynchronizedSample.class (一切皆对象,这个是类对象) |
| 代码块 | 指定对象 => lock (以上面的代码为例) |
面试官: 那你清楚 JVM 是怎么通过 synchronized 在对象上实现加锁,保证多线程访问竞态资源安全的吗?
安琪拉: 【天啦撸, 该来的还是要来】(⊙o⊙)…额,这个说起来有点复杂,我怕时间不够,要不下次再约?
面试官: 别下次了,今天我有的是时间,你慢慢讲,我慢慢👂你说。
安琪拉: 那要跟您好好说道了。分二个时间段来跟您讨论,先说到盘古开天辟地,女娲造石补天,咳咳,不好意思扯远了。。。。。。
- 先说在 JDK6 以前,synchronized 那时还属于重量级锁,相当于关二爷手中的青龙偃月刀,每次加锁都依赖操作系统 Mutex Lock 实现,涉及到操作系统让线程从用户态切换到内核态,切换成本很高;
- 到了 JDK6,研究人员引入了偏向锁和轻量级锁,因为 Sun 程序员发现大部分程序大多数时间都不会发生多个线程同时访问竞态资源的情况,每次线程都加锁解锁,每次这么搞都要操作系统在用户态和内核态之间来回切,太耗性能了。
面试官: 那你分别跟我讲讲 JDK 6 以前 synchronized 为什么这么重? JDK6 之后的偏向锁和轻量级锁是怎么回事?
安琪拉: 好的。首先要了解 synchronized 的实现原理,需要理解二个预备知识:
-
第一个预备知识:需要知道 Java 对象头,锁的类型和状态和对象头的 Mark Word 息息相关;
synchronized 锁 和 对象头息息相关。我们来看下对象的结构:
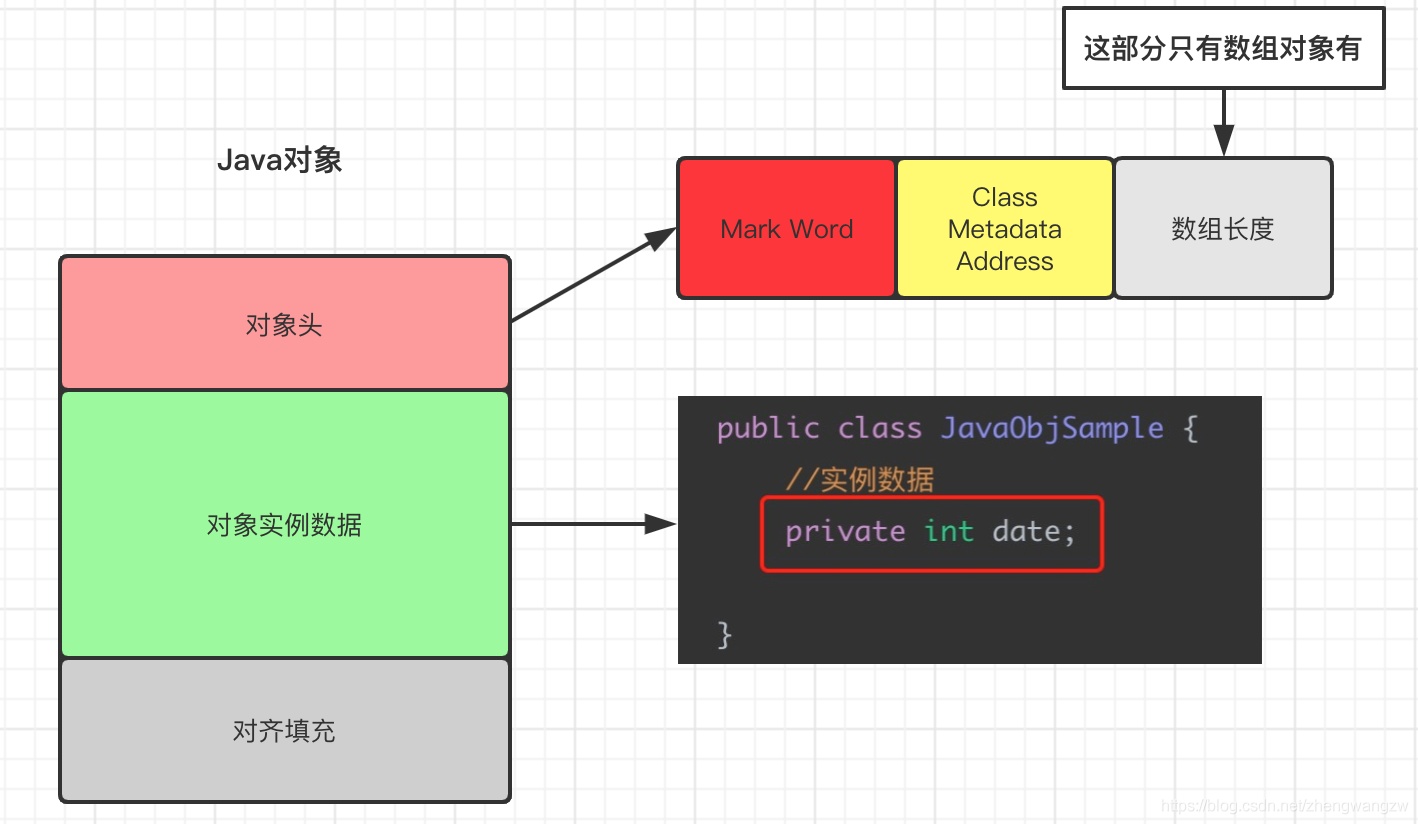 对象存储在堆中,主要分为三部分内容,对象头、对象实例数据和对齐填充(数组对象多一个区域:记录数组长度),下面简单说一下三部分内容,虽然 synchronized 只与对象头中的 Mard Word 相关。
对象存储在堆中,主要分为三部分内容,对象头、对象实例数据和对齐填充(数组对象多一个区域:记录数组长度),下面简单说一下三部分内容,虽然 synchronized 只与对象头中的 Mard Word 相关。 -
对象头:
对象头分为二个部分,Mard Word 和 Klass Word,👇列出了详细说明:
对象头结构 存储信息-说明 Mard Word 存储对象的 hashCode、锁信息或分代年龄或 GC 标志等信息 Klass Word 存储指向对象所属类(元数据)的指针,JVM 通过这个确定这个对象属于哪个类 -
对象实例数据:
如上图所示,类中的 成员变量 data 就属于对象实例数据;
-
对齐填充:
JVM 要求对象占用的空间必须是 8 的倍数,方便内存分配(以字节为最小单位分配),因此这部分就是用于填满不够的空间凑数用的。
-
第二个预备知识:需要了解 Monitor ,每个对象都有一个与之关联的 Monitor 对象;Monitor 对象属性如下所示( Hospot 1.7 代码) 。
//👇图详细介绍重要变量的作用
ObjectMonitor() {
_header = NULL;
_count = 0; // 重入次数
_waiters = 0, // 等待线程数
_recursions = 0;
_object = NULL;
_owner = NULL; // 当前持有锁的线程
_WaitSet = NULL; // 调用了 wait 方法的线程被阻塞 放置在这里
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 等待锁 处于 block 的线程 有资格成为候选资源的线程
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
对象关联的 ObjectMonitor 对象有一个线程内部竞争锁的机制,如下图所示: 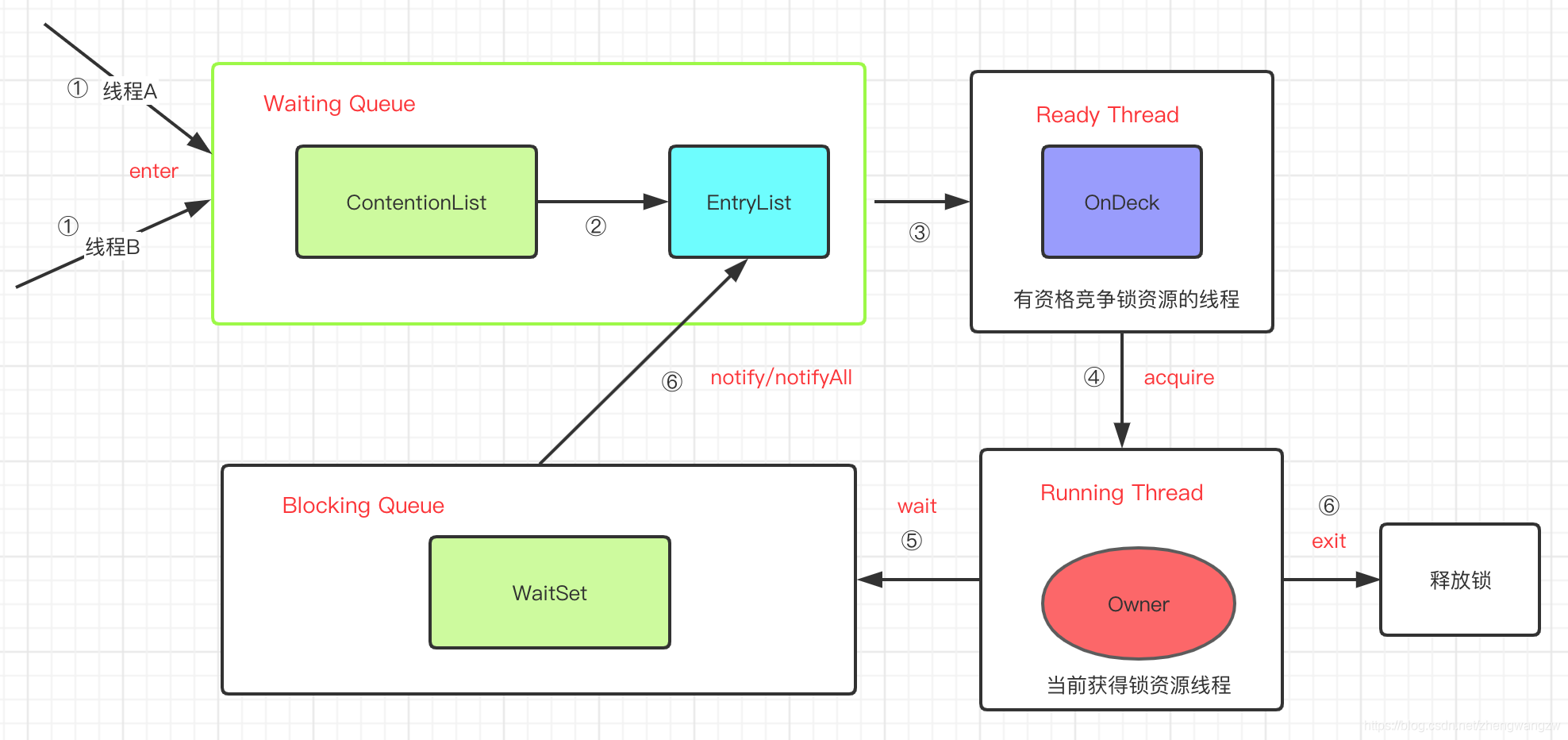
面试官: 预备的二个知识我大体看了,后面给我讲讲 JDK 6 以前 synchronized 具体实现逻辑吧。
安琪拉: 好的。【开始我的表演】
-
当有二个线程 A、线程 B 都要开始给我们队的经济 money 变量 + 钱,要进行操作的时候 ,发现方法上加了 synchronized 锁,这时线程调度到 A 线程执行,A 线程就抢先拿到了锁。拿到锁的步骤为: - 1.1 将
MonitorObject中的 _owner 设置成 A 线程; - 1.2 将 mark word 设置为 Monitor 对象地址,锁标志位改为 10; - 1.3 将 B 线程阻塞放到 ContentionList 队列; -
JVM 每次从 Waiting Queue 的尾部取出一个线程放到 OnDeck 作为候选者,但是如果并发比较高,Waiting Queue 会被大量线程执行 CAS 操作,为了降低对尾部元素的竞争,将 Waiting Queue 拆分成 ContentionList 和 EntryList 二个队列, JVM 将一部分线程移到 EntryList 作为准备进 OnDeck 的预备线程。另外说明几点:
-
所有请求锁的线程首先被放在 ContentionList 这个竞争队列中;
-
Contention List 中那些有资格成为候选资源的线程被移动到 Entry List 中;
-
任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为 OnDeck;
-
当前已经获取到所资源的线程被称为 Owner;
-
处于 ContentionList、EntryList、WaitSet 中的线程都处于阻塞状态,该阻塞是由操作系统来完成的(Linux 内核下采用
pthread_mutex_lock内核函数实现的);
- 作为 Owner 的 A 线程执行过程中,可能调用 wait 释放锁,这个时候 A 线程进入 Wait Set , 等待被唤醒。
以上就是我想说的 synchronized 在 JDK 6 之前的实现原理。
面试官: 那你知道 synchronized 是公平锁还是非公平锁吗?
安琪拉: 非公平的。主要有以下二点原因:
- Synchronized 在线程竞争锁时,首先做的不是直接进 ContentionList 队列排队,而是尝试自旋获取锁(可能 ContentionList 有别的线程在等锁),如果获取不到才进入 ContentionList,这明显对于已经进入队列的线程是不公平的;
- 另一个不公平的是自旋获取锁的线程还可能直接抢占 OnDeck 线程的锁资源。
面试官: 你前面说到 JDK 6 之后 synchronized 做了优化,跟我讲讲?
安琪拉: 不要着急! 容我点个治疗,再跟你掰扯掰扯。前面说了锁跟对象头的 Mark Word 密切相关,我们把目光放到对象头的 Mark Word 上, Mark Word 存储结构如下图和源代码注释(以 32 位 JVM 为例,后面的讨论都基于 32 位 JVM 的背景,64 位会特殊说明)。 Mard Word会在不同的锁状态下,32 位指定区域都有不同的含义,这个是为了节省存储空间,用 4 字节就表达了完整的状态信息,当然,对象某一时刻只会是下面 5 种状态种的某一种。
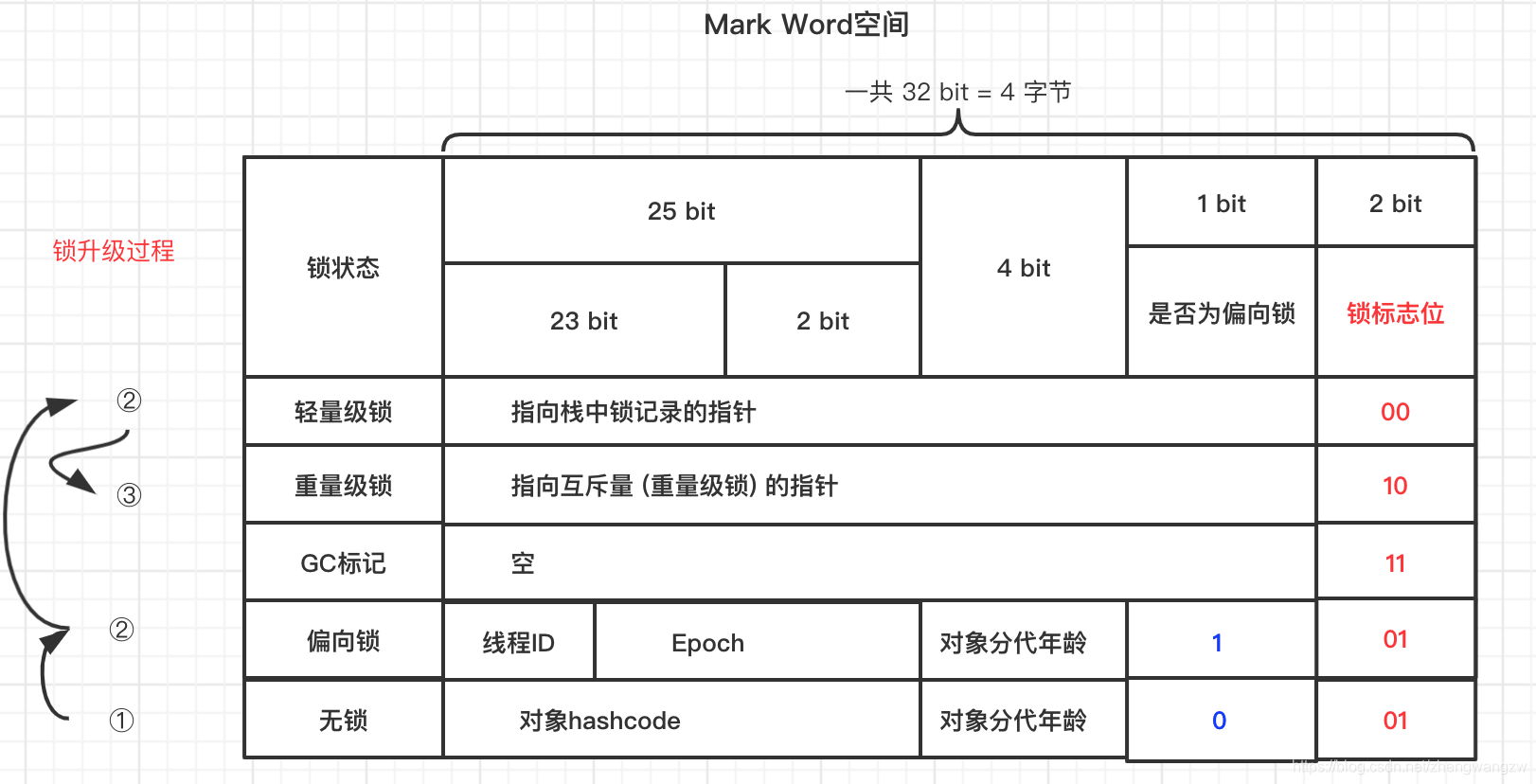 下面是简化后的 Mark Word
下面是简化后的 Mark Word 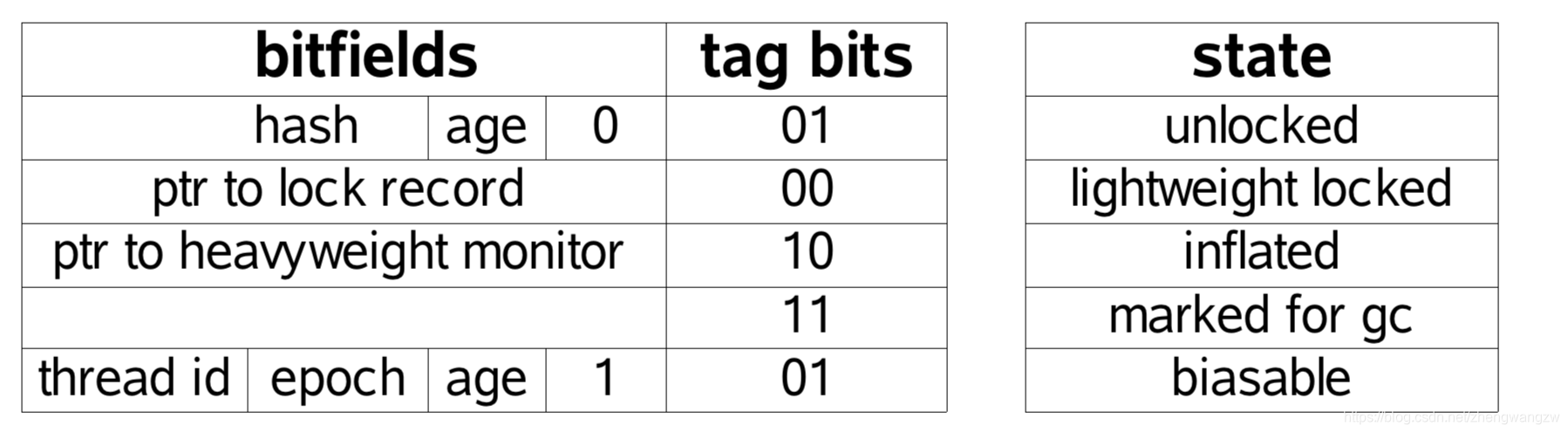
hash: 保存对象的哈希码
age: 保存对象的分代年龄
biased_lock: 偏向锁标识位
lock: 锁状态标识位
JavaThread*: 保存持有偏向锁的线程 ID
epoch: 保存偏向时间戳
安琪拉: 由于 synchronized 重量级锁有以下二个问题, 因此 JDK 6 之后做了改进,引入了偏向锁和轻量级锁:
-
依赖底层操作系统的
mutex相关指令实现,加锁解锁需要在用户态和内核态之间切换,性能损耗非常明显。 -
研究人员发现,大多数对象的加锁和解锁都是在特定的线程中完成。也就是出现线程竞争锁的情况概率比较低。他们做了一个实验,找了一些典型的软件,测试同一个线程加锁解锁的重复率,如下图所示,可以看到重复加锁比例非常高。早期 JVM 有 19% 的执行时间浪费在锁上。
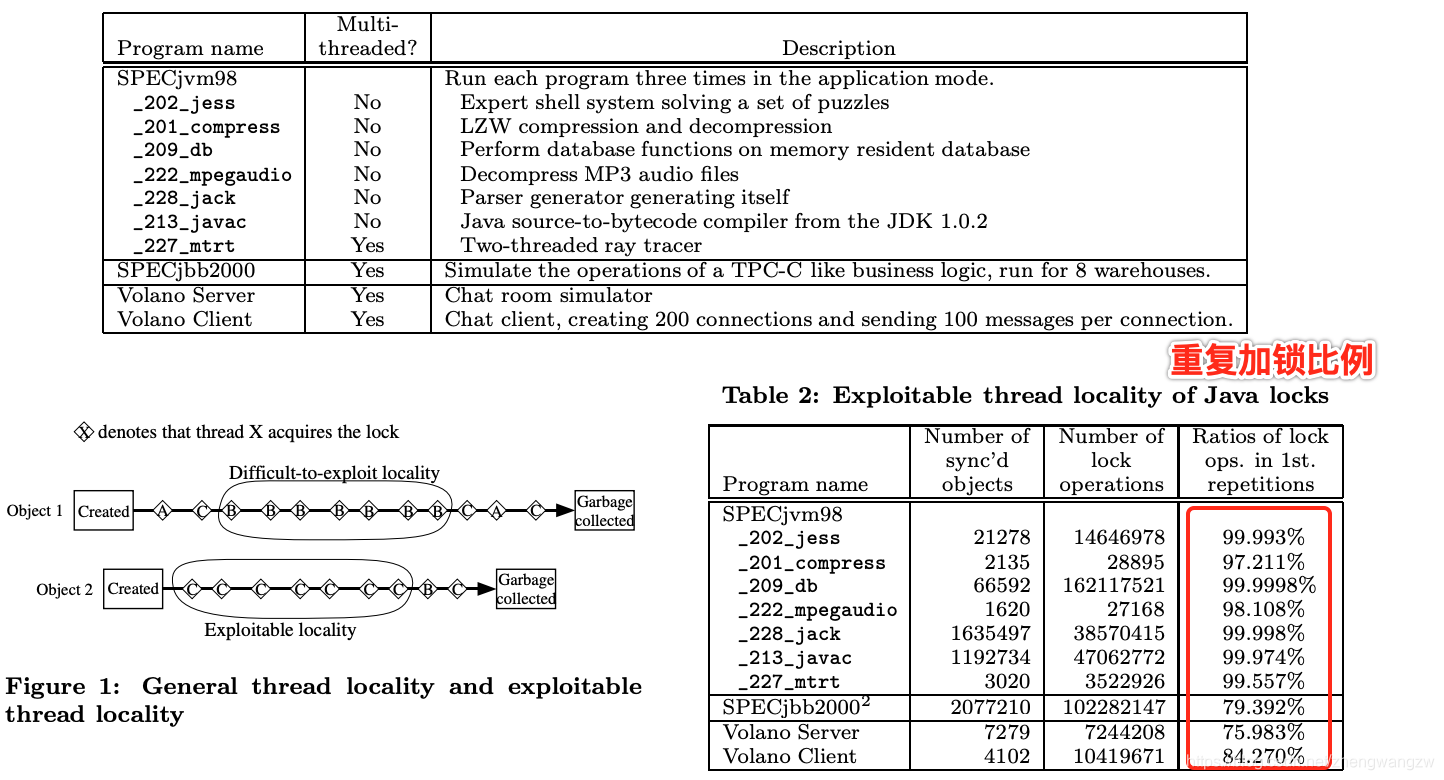
Thin locks are a lot cheaper than inflated locks, but their performance suffers from the fact that every compare-and-swap operation must be executed atomically on multi-processor machines, although most objects are locked and unlocked only by one particular thread.
It was reported that 19% of the total execution time was wasted by thread synchronization in an early version of Java virtual machine。
面试官: 你跟我讲讲 JDK 6 以来 synchronized 锁状态怎么从无锁状态到偏向锁的吗?
安琪拉: OK 的啦!,我们来看下图对象从无锁到偏向锁转化的过程(JVM -XX:+UseBiasedLocking 开启偏向锁):
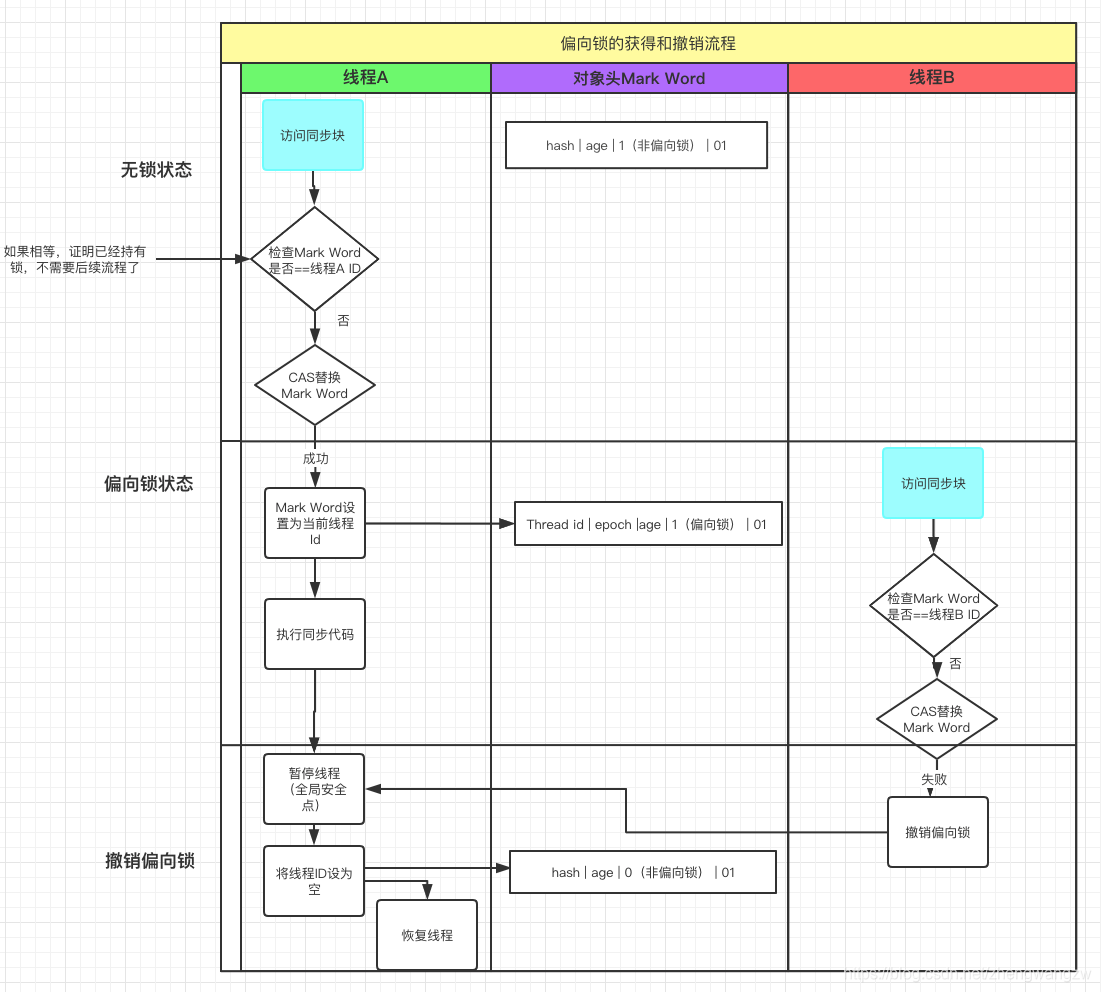
- 首先 A 线程访问同步代码块,使用 CAS 操作将 Thread ID 放到
Mark Word当中; - 如果 CAS 成功,此时线程 A 就获取了锁
- 如果线程 CAS 失败,证明有别的线程持有锁,例如上图的线程 B 来 CAS 就失败的,这个时候启动偏向锁撤销 (revoke bias);
- 锁撤销流程:
- 让 A 线程在全局安全点阻塞(类似于 GC 前线程在安全点阻塞)
- 遍历线程栈,查看是否有被锁对象的锁记录( Lock Record),如果有 Lock Record,需要修复锁记录和 Markword,使其变成无锁状态。
- 恢复 A 线程
- 将是否为偏向锁状态置为 0 ,开始进行轻量级加锁流程 (后面讲述) 下图说明了
Mark Word在这个过程中的转化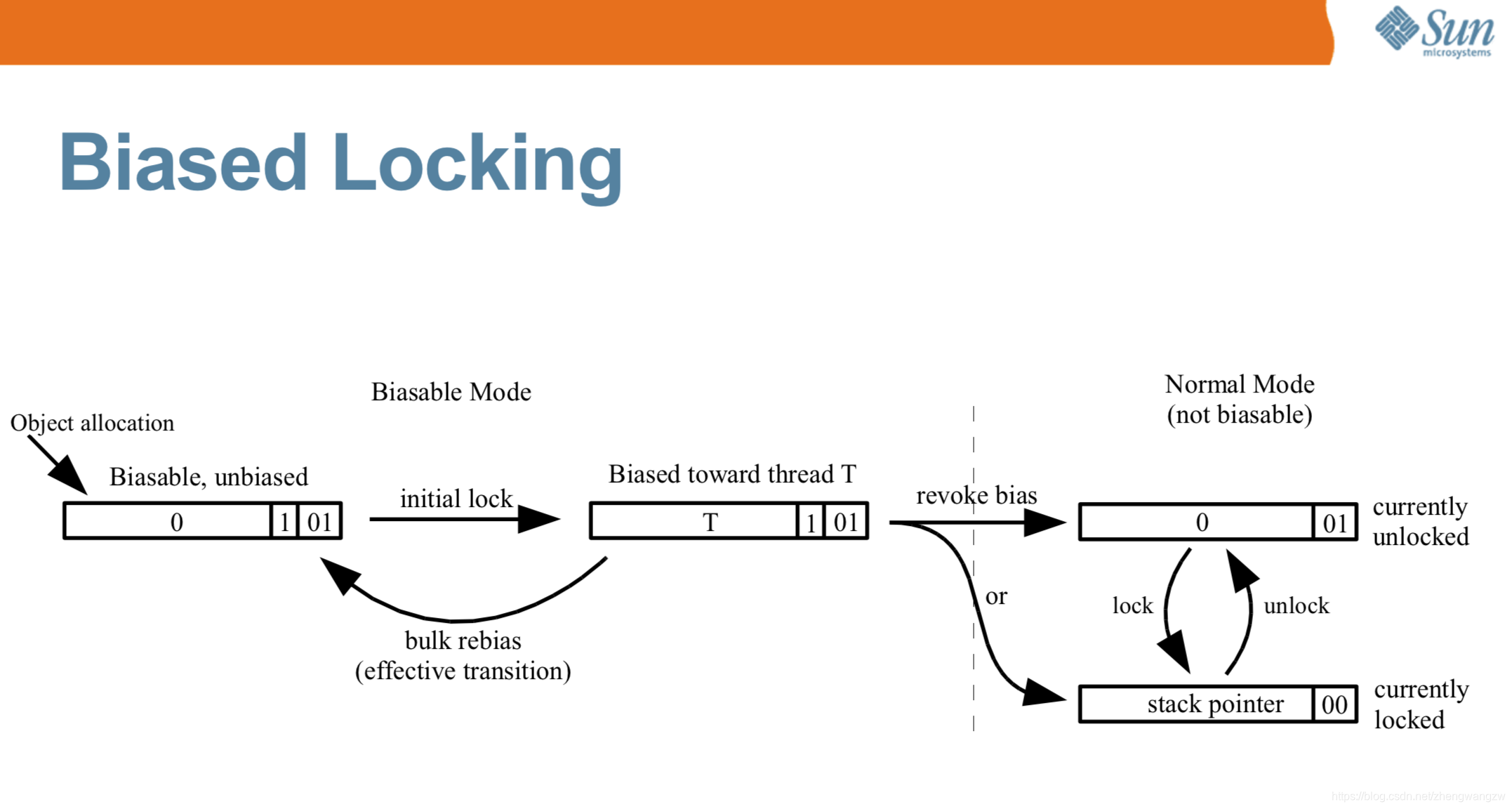 面试官: 不错,那你跟我讲讲偏向锁撤销怎么到轻量级锁的? 还有轻量级锁什么时候会变成重量级锁? 安琪拉: 继续上面的流程,锁撤销之后(偏向锁状态为 0),现在无论是 A 线程还是 B 线程执行到同步代码块进行加锁,流程如下:
面试官: 不错,那你跟我讲讲偏向锁撤销怎么到轻量级锁的? 还有轻量级锁什么时候会变成重量级锁? 安琪拉: 继续上面的流程,锁撤销之后(偏向锁状态为 0),现在无论是 A 线程还是 B 线程执行到同步代码块进行加锁,流程如下: - 线程在自己的栈桢中创建锁记录 LockRecord。
- 线程 A 将
Mark Word拷贝到线程栈的 Lock Record 中,这个位置叫 displayced hdr,如下图所示: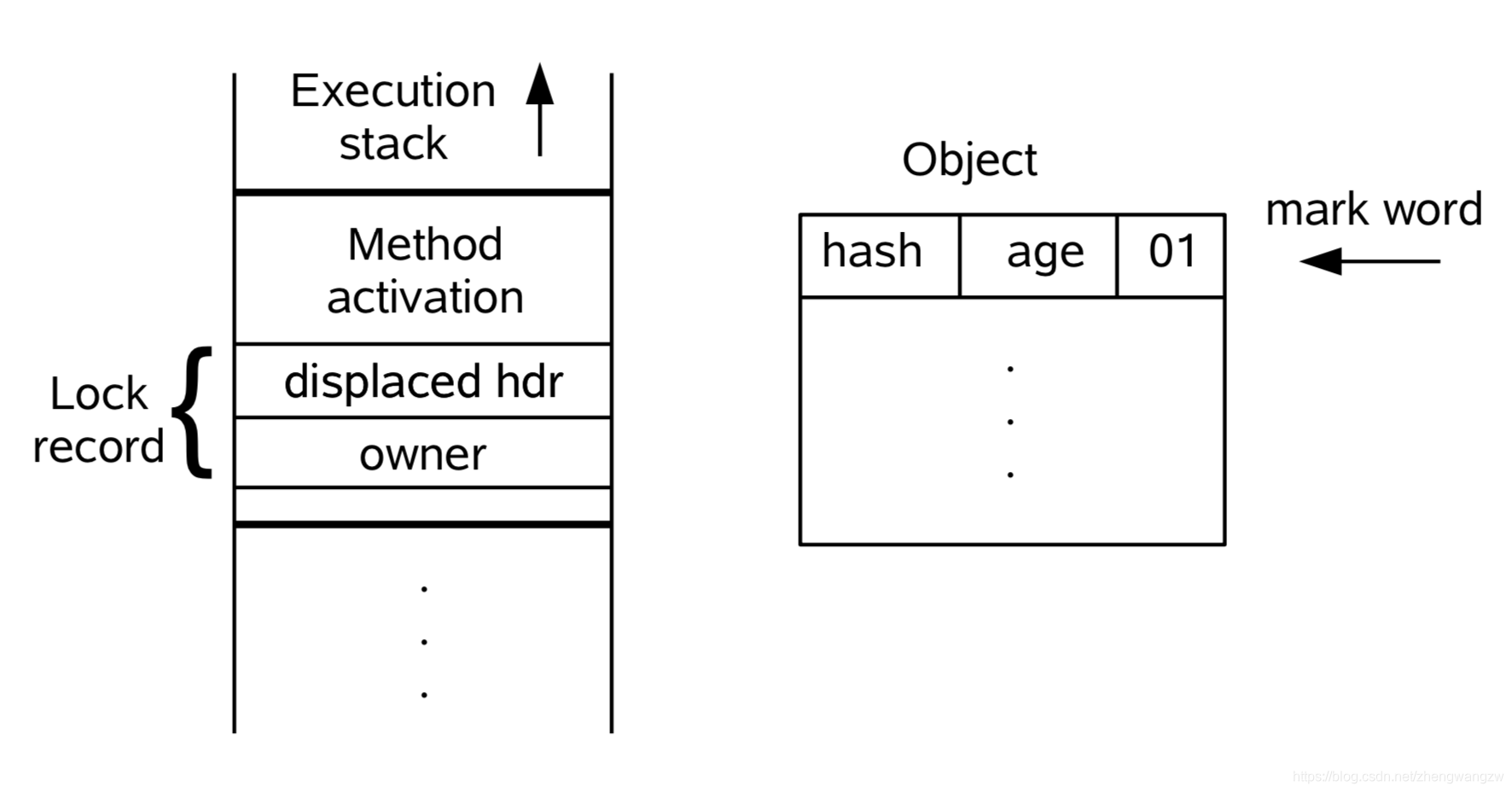
- 将锁记录中的 Owner 指针指向加锁的对象(存放对象地址)。
- 将锁对象的对象头的 MarkWord 替换为指向锁记录的指针。这二步如下图所示:
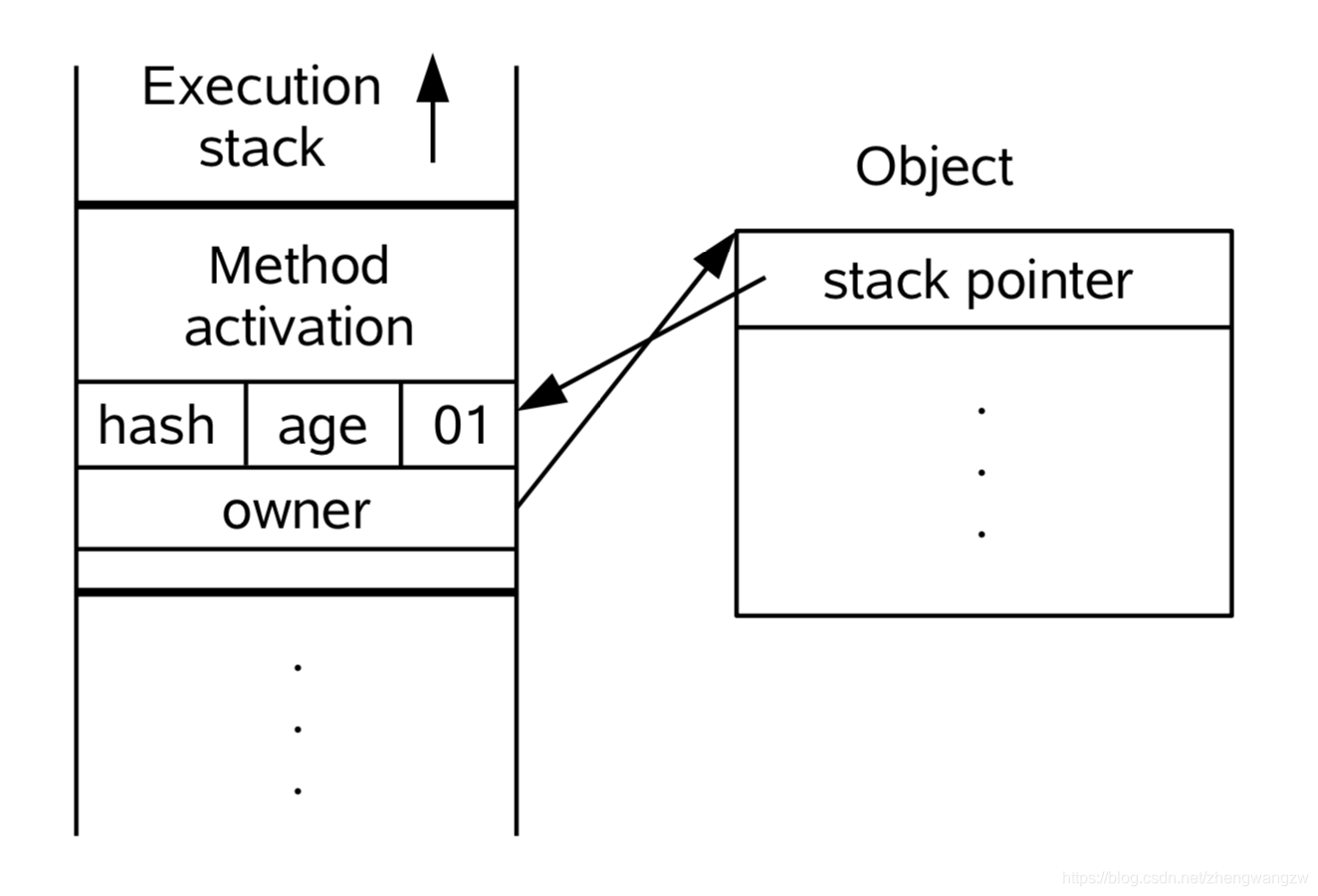
- 这时锁标志位变成 00 ,表示轻量级锁
面试官: 看来对 synchronized 很有研究嘛。我钟馗不信难不倒你,那轻量级锁什么时候会升级为重量级锁, 请回答? 安琪拉: 当锁升级为轻量级锁之后,如果依然有新线程过来竞争锁,首先新线程会自旋尝试获取锁,尝试到一定次数(默认 10 次)依然没有拿到,锁就会升级成重量级锁。 面试官: 为什么这么设计? 安琪拉: 一般来说,同步代码块内的代码应该很快就执行结束,这时候线程 B 自旋一段时间是很容易拿到锁的,但是如果不巧,没拿到,自旋其实就是死循环,很耗 CPU 的,因此就直接转成重量级锁咯,这样就不用了线程一直自旋了。 这就是锁膨胀的过程,下图是 Mark Word 和锁状态的转化图 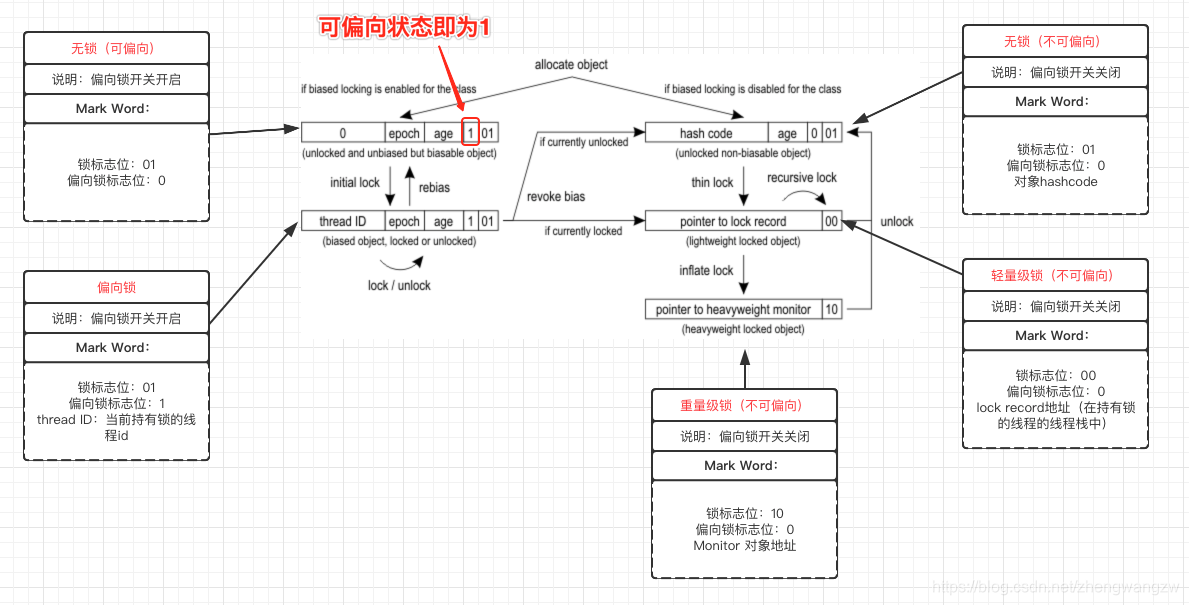 主要👆图我标注出来的,锁当前为可偏向状态,偏向锁状态位置就是 1,看到很多网上的文章都写错了,把这里写成只有锁发生偏向才会置为 1,一定要注意。 面试官: 既然偏向锁有撤销,还会膨胀,性能损耗这么大,还需要用他们呢? 安琪拉: 如果确定竞态资源会被高并发的访问,建议通过
主要👆图我标注出来的,锁当前为可偏向状态,偏向锁状态位置就是 1,看到很多网上的文章都写错了,把这里写成只有锁发生偏向才会置为 1,一定要注意。 面试官: 既然偏向锁有撤销,还会膨胀,性能损耗这么大,还需要用他们呢? 安琪拉: 如果确定竞态资源会被高并发的访问,建议通过-XX:-UseBiasedLocking 参数关闭偏向锁,偏向锁的好处是并发度很低的情况下,同一个线程获取锁不需要内存拷贝的操作,免去了轻量级锁的在线程栈中建 Lock Record,拷贝 Mark Down 的内容,也免了重量级锁的底层操作系统用户态到内核态的切换,因为前面说了,需要使用系统指令。另外 Hotspot 也做了另一项优化,基于锁对象的 epoch 批量偏向和批量撤销偏向,这样可以大大降低了单次偏向锁的 CAS 和锁撤销带来的损耗,👇图是研究人员做的压测: 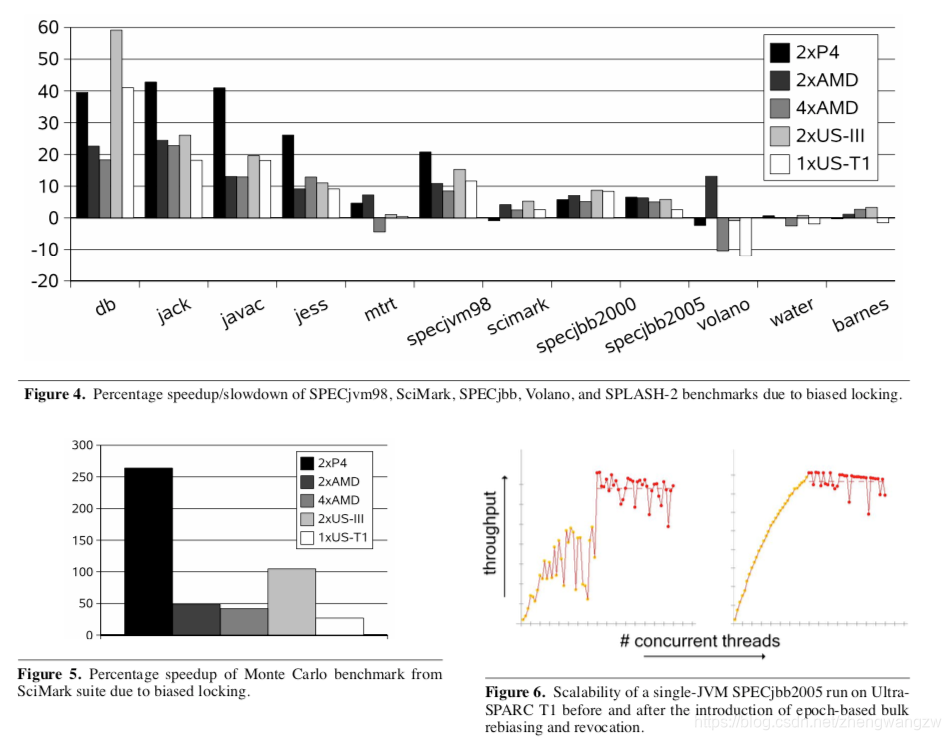
Eliminating Synchronization-Related Atomic Operations with Biased Locking and Bulk Rebiasing
安琪拉: 他们在几款典型软件上做了测试,发现基于 epoch 批量撤销偏向锁和批量加偏向锁能大幅提升吞吐量,但是并发量特别大的时候性能就没有什么特别大的提升了。 面试官:可以可以,那你看过 synchronized 底层实现源码没有? 安琪拉: 那当然啦,源码是我的二技能,高爆发的伤害能不能打出来就看它了,我们一步一步来。 我们把文章开头的示例代码编译成 class 文件,然后通过javap -v SynchronizedSample.class 来看下 synchronized 到底在源码层面如何实现的? 如下图所示: 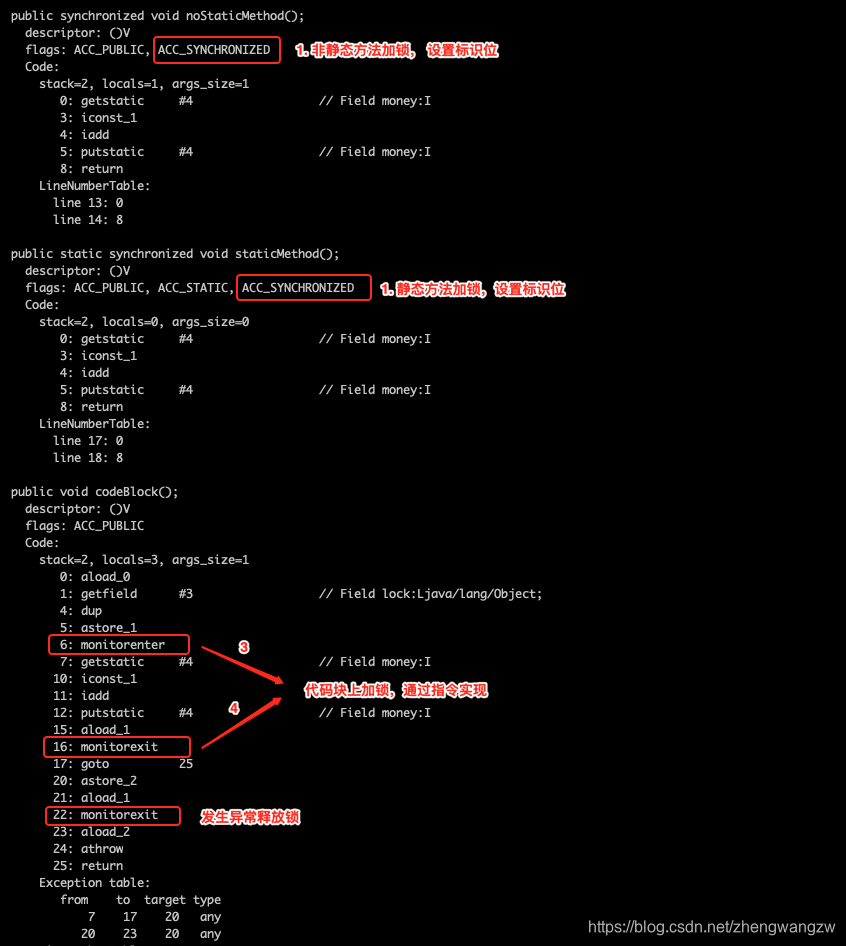 安琪拉: synchronized 在代码块上是通过 monitorenter 和 monitorexit 指令实现,在静态方法和 方法上加锁是在方法的 flags 中加入 ACC_SYNCHRONIZED 。JVM 运行方法时检查方法的 flags,遇到同步标识开始启动前面的加锁流程,在方法内部遇到 monitorenter 指令开始加锁。
安琪拉: synchronized 在代码块上是通过 monitorenter 和 monitorexit 指令实现,在静态方法和 方法上加锁是在方法的 flags 中加入 ACC_SYNCHRONIZED 。JVM 运行方法时检查方法的 flags,遇到同步标识开始启动前面的加锁流程,在方法内部遇到 monitorenter 指令开始加锁。
monitorenter 指令函数源代码在 InterpreterRuntime::monitorenter中
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
//是否开启了偏向锁
if (UseBiasedLocking) {
// 尝试偏向锁
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
// 轻量锁逻辑
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
偏向锁代码
// -----------------------------------------------------------------------------
// Fast Monitor Enter/Exit
// This the fast monitor enter. The interpreter and compiler use
// some assembly copies of this code. Make sure update those code
// if the following function is changed. The implementation is
// extremely sensitive to race condition. Be careful.
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
//是否使用偏向锁
if (UseBiasedLocking) {
// 如果不在全局安全点
if (!SafepointSynchronize::is_at_safepoint()) {
// 获取偏向锁
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
// 在全局安全点,撤销偏向锁
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
// 进轻量级锁流程
slow_enter (obj, lock, THREAD) ;
}
偏向锁的实现具体代码在 BiasedLocking::revoke_and_rebias 中,因为函数非常长,就不贴出来,有兴趣的可以在Hotspot 1.8-biasedLocking.cpp去看。 轻量级锁代码流程
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
//获取对象的 markOop 数据 mark
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
//判断 mark 是否为无锁状态 & 不可偏向(锁标识为 01,偏向锁标志位为 0)
if (mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
// 保存 Mark 到 线程栈 Lock Record 的 displaced_header 中
lock->set_displaced_header(mark);
// CAS 将 Mark Down 更新为 指向 lock 对象的指针,成功则获取到锁
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else
// 根据对象 mark 判断已经有锁 & mark 中指针指的当前线程的 Lock Record(当前线程已经获取到了,不必重试获取)
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
lock->set_displaced_header(markOopDesc::unused_mark());
// 锁膨胀
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
做个假设,现在线程 A 和 B 同时执行到临界区 if (mark->isneutral()): 1、线程 A 和 B 都把 Mark Word 复制到各自的displacedheader 字段,该数据保存在线程的栈帧上,是线程私有的; 2、Atomic::cmpxchgptr 属于原子操作,保障了只有一个线程可以把 Mark Word 中替换成指向自己线程栈 displaced_header 中的,假设 A 线程执行成功,相当于 A 获取到了锁,开始继续执行同步代码块; 3、线程 B 执行失败,退出临界区,通过 ObjectSynchronizer::inflate 方法开始膨胀锁;
面试官: synchronized 源码这部分可以了,👂不下去了。你跟我讲讲 Java 中除了 synchronized 还有别的锁吗?
安琪拉: 还有 ReentrantLock 也可以实现加锁。
面试官: 那写段代码实现之前加经济的同样效果。
安琪拉: coding 如👇图: 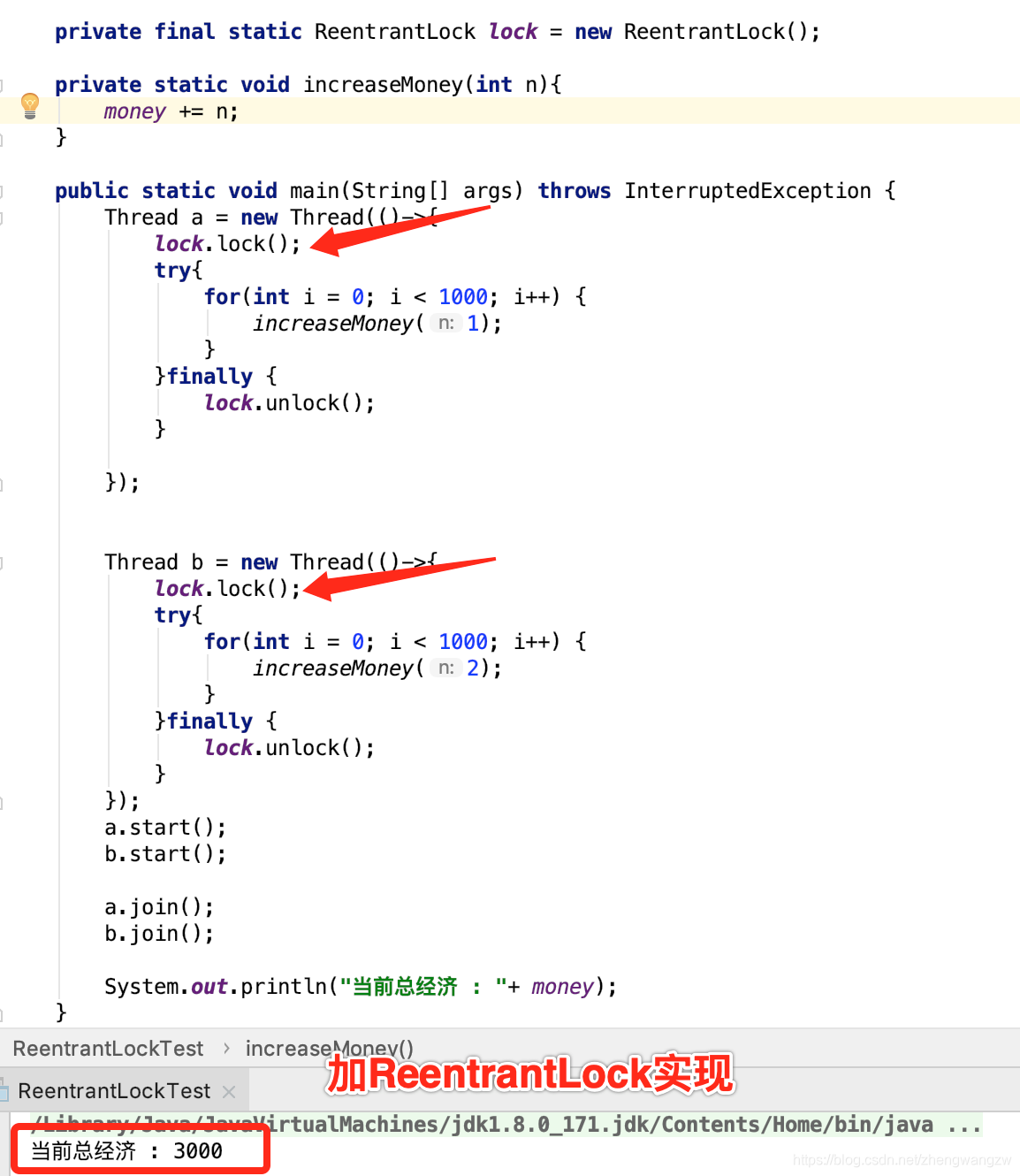 面试官: 哦,那你跟我说说 ReentrantLock 的底层实现原理?
面试官: 哦,那你跟我说说 ReentrantLock 的底层实现原理?
安琪拉: 天色已晚,我们能改日再聊吗?
面试官: 那你回去等通知吧。
安琪拉: 【内心是崩溃的】,看来这次面试就黄了,😔,心累。
补充说明: 在代码中查看对象头信息方法:
- maven 添加以下依赖:
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> </dependency> - 示例代码和输出
public static void main(String[] args) {
Test obj = new Test();
ClassLayout layout = ClassLayout.parseInstance(obj);
//打印空对象大小
System.out.println(layout.instanceSize());
System.out.println(layout.toPrintable());
synchronized (obj){
System.out.println("after lock");
System.out.println(layout.toPrintable());
}
System.out.println("after re-lock");
System.out.println(layout.toPrintable());
}
控制台输出如下: 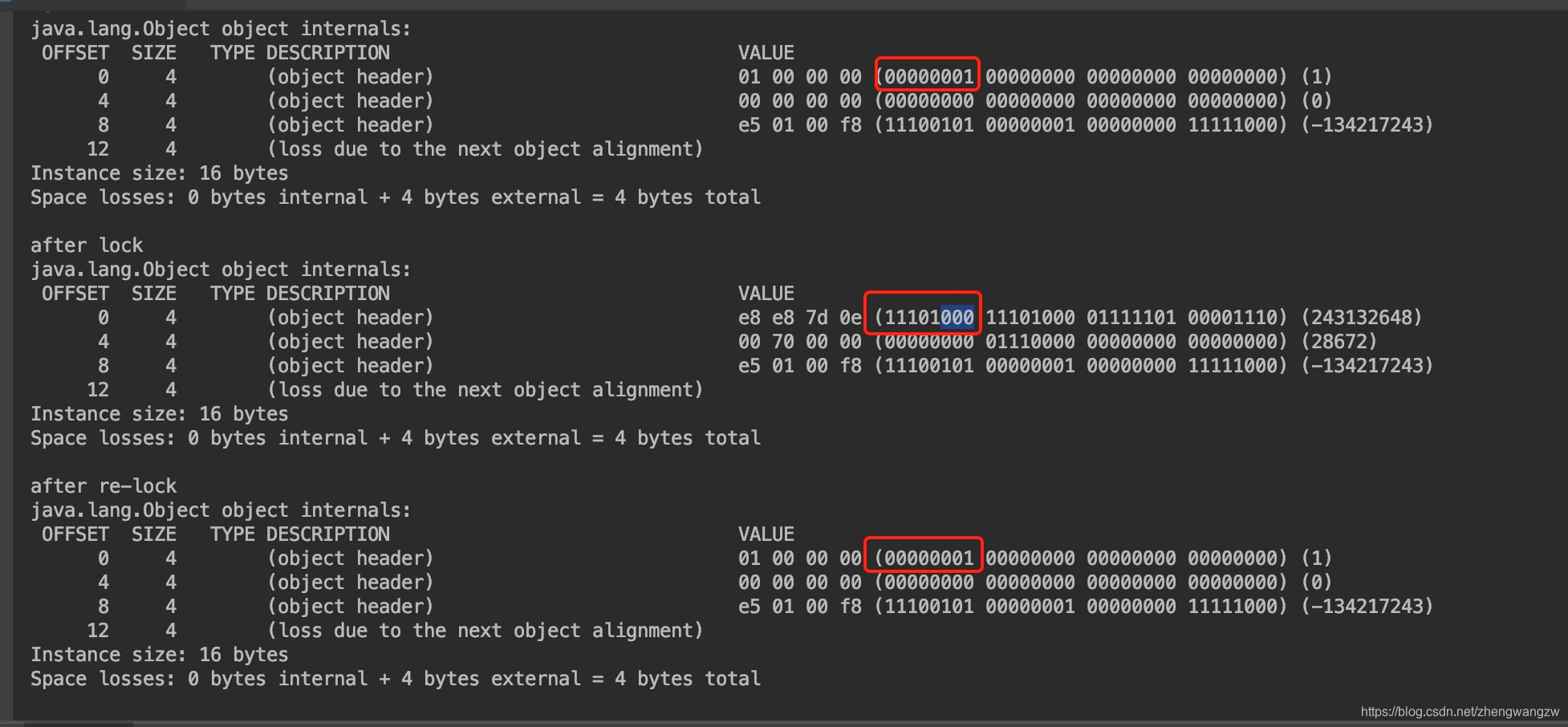 这个是反着的,这里是高地址位表示低位数据,低地址位表示高位数据, 👆可以看出对象后三位是 001,0 代表不可偏向状态,01 代表无锁状态,第二个 000,表示轻量级锁状态,最后释放锁,变回 01 状态无锁状态。
这个是反着的,这里是高地址位表示低位数据,低地址位表示高位数据, 👆可以看出对象后三位是 001,0 代表不可偏向状态,01 代表无锁状态,第二个 000,表示轻量级锁状态,最后释放锁,变回 01 状态无锁状态。

关注 Wx 公众号【安琪拉的博客】 —揭秘 Java 后端技术,还原技术背后的本质
《安琪拉与面试官二三事》系列文章 持续更新中 一个 HashMap 能跟面试官扯上半个小时 一个 synchronized 跟面试官扯了半个小时
互动评论
评论
林家振7 天前
面试官要是让通过的话自己饭碗岌岌可危啊~
1
查看更多














 2874
2874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









