






http://write.blog.csdn.NET/postedit
在上次我们搭建了hadoop2.8的高可用NameNode的HA环境,并引入了zookeeper
这次我们要在这个环境的基础上搭建Hbase
先说规划
| 编号 | 主机名 | 用途 |
| 0 | xxCentosZero | HMaster(备用,尚未加入) |
| 1 | xxCentosOne | HMaster |
| 2 | xxCentosTwo | HRegionServer |
| 3 | xxCentosThree | HRegionServer |
| 4 | xxCentosFour | HRegionServer |
如上所示,暂时没有加入xxCentosZero到HMaster的集群中
先说搭建的过程吧。
一、下载与部署
0,首先要注意的是hbase与Hadoop的版本的对应匹配关系。详见官网
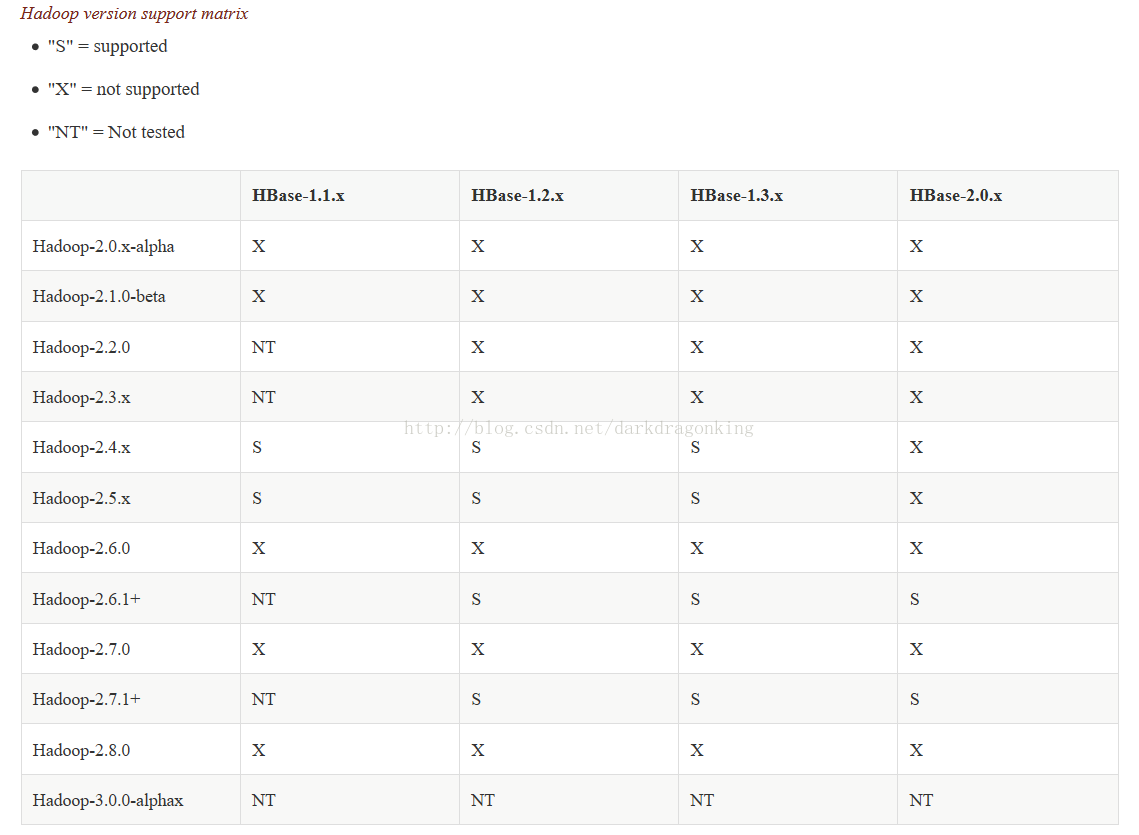
1,点击这里下载hbase的稳定版
2,放到/usr/local/下解压缩,改名为hbase
3,配置环境变量,修改/etc/profile
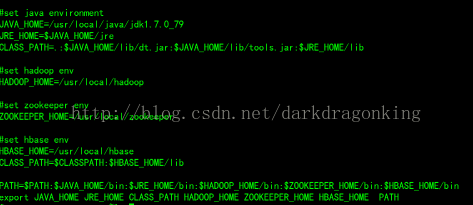
二、修改配置文件
1,修改/usr/local/hbase/conf/hbase-env.sh 环境变量文件,主要修改以下几个地方
- <span style="font-family:KaiTi_GB2312;font-size:14px;"># The java implementation to use. Java 1.7+ required.
- #jdk的安装目录
- export JAVA_HOME=/usr/local/java/jdk1.7.0_79</span>
- <span style="font-family:KaiTi_GB2312;font-size:14px;"># Extra Java CLASSPATH elements. Optional.
- #用到的一些外部jar包的路径,有人这里写的是/usr/local/hbase/conf这个路径,我觉得是否写错了啊
- export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop</span>
- <span style="font-family:KaiTi_GB2312;font-size:14px;"># The maximum amount of heap to use. Default is left to JVM default.
- # hbase用到的总体的堆内存的量。但是不确定写成“400M”这个样式会否被正确识别。同时我的虚拟机仅有1G内存分配给它们,所以我没有显式指定
- # export HBASE_HEAPSIZE=400m</span>
- <span style="font-family:KaiTi_GB2312;font-size:14px;"># Tell HBase whether it should manage it's own instance of Zookeeper or not.
- #如果用的是自己安装的zookeeper,这里就写成false,如果用的是hbase自带zookeeper,就是true。
- export HBASE_MANAGES_ZK=false</span>
2,修改/usr/local/hbase/conf/hbase-site.xml配置文件。分为简化版和比较详细版
先来个简化版
- <span style="font-family:KaiTi_GB2312;font-size:14px;"><configuration>
- <!--如果不是集群的话,应该与core-site.xml文件的fs.defaultFS一致-->
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://xxCentosOne:9000/hbase</value>
- </property>
- <!--是否分布式-->
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <!--zookeeper部署的主机名和访问的端口号-->
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>xxCentosZero:2181,xxCentosOne:2181,xxCentosTwo:2181,xxCentosThree:2181,xxCentosFour:2181</value>
- </property>
- <!--每台服务器上zookeeper的data文件夹下路径-->
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/usr/local/zookeeper/data</value>
- </property>
- </configuration></span>
再来个较详细版
- <span style="font-family:KaiTi_GB2312;font-size:14px;"><?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <!--
- /**
- *
- * Licensed to the Apache Software Foundation (ASF) under one
- * or more contributor license agreements. See the NOTICE file
- * distributed with this work for additional information
- * regarding copyright ownership. The ASF licenses this file
- * to you under the Apache License, Version 2.0 (the
- * "License"); you may not use this file except in compliance
- * with the License. You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
- -->
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://xxCentosOne:9000/hbase</value><!--这里必须跟core-site.xml中的fs.defaultFS键配置一样-->
- </property>
- <!-- 开启分布式模式 -->
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <!--只配置端口,为了配置多个HMaster -->
- <property>
- <name>hbase.master</name>
- <value>xxCentosOne:60000</value>
- </property>
- <property>
- <name>hbase.tmp.dir</name>
- <value>/usr/local/hbase/tmp</value>
- </property>
- <!--这里设置hbase API客户端侧缓存值,大于此值就进行一次提交,/opt/hbase-1.2.1/conf/hbase-site.xml统一配置为5M,对所有HTable都生效,那么客户端API就可不设置-->
- <!--htable.setWriteBufferSize(5242880);//5M -->
- <property>
- <name>hbase.client.write.buffer</name>
- <value>5242880</value>
- </property>
- <!--这里设置Master并发最大线程数,经常有人设为300左右-->
- <property>
- <name>hbase.regionserver.handler.count</name>
- <value>20</value>
- </property>
- <!--
- 默认值 :256M
- 说明 :在当前ReigonServer上单个Reigon的最大存储空间,单个Region超过该值时,这个Region会被自动split成更小的region。
- 数据表创建时会预分区,每个预分区最大大小这里设置为10G,防止频繁的split阻塞数据读写,
- 只有当预分区超过10G时才会进行split,正式环境应该首先预测数据存储时间内的大致数据量,
- 然后如果每个预分区为10G,计算出分区数,建表时指定分区设置,防止后期频繁split
- 写法,如果你想设为128兆,但绝不可以写成128M这样,最安全的写法是128*1024*1024的数值,如下
- -->
- <property>
- <name>hbase.hregion.max.filesize</name>
- <value>134217728</value>
- </property>
- <!--
- 默认hbase每24小时会进行一次major_compact,major_compact会阻塞读写,这里先禁用,但不代表这个操作不做,
- 可以后期指定linux shell加入到cron定时任务在hbase集群空闲情况下执行
- -->
- <property>
- <name>hbase.hregion.majorcompaction</name>
- <value>0</value>
- </property>
- <!--
- hbase本质上可以说是HADOOP HDFS的客户端,虽然Hadoop的core-site.xml里设置了文件副本数,但是仍然是客户端传值优先,这里设置为2,
- 意思是一个文件,最终在Hadoop上总个数为2,正式环境最好设置为3,目前发现此值小于3时,
- 在遇到All datanodes xxx.xxx.xxx.xxx:port are bad. Aborting...错误信息时,如果某个DataNode宕机,原则上hbase调用的DFSClient会去其他Datanode
- 上重试写,但发现配置的值低于3就不会去尝试
- -->
- <property>
- <name>dfs.replication</name>
- <value>2</value>
- </property>
- <!--
- IncreasingToUpperBoundRegionSplitPolicy策略的意思是,数据表如果预分区为2,配置的memstore flush size=128M,那么下一次分裂大小是2的平方然后乘以128MB,即2*2*128M=512MB;
- ConstantSizeRegionSplitPolicy策略的意思是按照上面指定的region大小超过30G才做分裂
- -->
- <property>
- <name>hbase.regionserver.region.split.policy</name>
- <value>org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy</value>
- </property>
- <!--一个edit版本在内存中的cache时长,默认3600000毫秒-->
- <property>
- <name>hbase.regionserver.optionalcacheflushinterval</name>
- <value>7200000</value>
- </property>
- <!--分配给HFile/StoreFile的block cache占最大堆(-Xmx setting)的比例。默认0.3意思是分配30%,设置为0就是禁用,但不推荐。-->
- <property>
- <name>hfile.block.cache.size</name>
- <value>0.3</value>
- </property>
- <!--当memstore的大小超过这个值的时候,会flush到磁盘。这个值被一个线程每隔hbase.server.thread.wakefrequency检查一下。-->
- <property>
- <name>hbase.hregion.memstore.flush.size</name>
- <value>52428800</value>
- </property>
- <!--
- 默认值 :0.4/0.35
- 说明 :hbase.hregion.memstore.flush.size 这个参数的作用是当单个Region内所有的memstore大小总和超过指定值时,flush该region的所有memstore
- 单个region server的全部memtores的最大值。超过这个值,一个新的update操作会被挂起,强制执行flush操作。
- 以前版本中是通过hbase.regionserver.global.memstore.upperLimit设置,老版本中含义是在hbase-env.sh中配置的HEAP_SIZE比如4G,
- 那么以该值4G乘以配置的0.5就是2G,意思是所有memstore总和达到2G值时,阻塞所有读写,现在1.2.1版本hbase中被hbase.regionserver.global.memstore.size替代,
- 计算方法仍然是HEAP_SIZE乘以配置的百分比比如下面的0.5,那么阻塞读写的阀值就为2G
- -->
- <property>
- <name>hbase.regionserver.global.memstore.size</name>
- <value>0.5</value>
- </property>
- <!--
- 当强制执行flush操作的时候,当低于这个值的时候,flush会停止。
- 默认是堆大小的 35% . 如果这个值和 hbase.regionserver.global.memstore.upperLimit 相同就意味着当update操作因为内存限制被挂起时,
- 会尽量少的执行flush(译者注:一旦执行flush,值就会比下限要低,不再执行)。
- 在老版本中该值是通过hbase.regionserver.global.memstore.size.lower.limit设置,
- 计算方法是以hbase-env.sh的HEAP_SIZE乘以配置的百分比比如0.3就是HEAP_SIZE4G乘以0.3=1.2G,达到这个值的话就在所有memstore中选择最大的那个做flush动作,
- 新版本则完全不同了,首先是通过hbase.regionserver.global.memstore.lowerLimit设置,而且不是以HEAP_SIZE作为参考,
- 二是以配置的hbase.regionserver.global.memstore.size的值再乘以配置的比例比如0.5,如果HEAP_SIZE=4G,
- hbase.regionserver.global.memstore.size配置为0.5,hbase.regionserver.global.memstore.size.lower.limit配置的为0.5,
- 则计算出来的值为4G乘以0.5再乘以0.5就是1G了,达到1G就先找最大的memstore触发flush
- -->
- <property>
- <name>hbase.regionserver.global.memstore.size.lower.limit</name>
- <value>0.5</value>
- </property>
- <!--这里设置HDFS客户端最大超时时间,尽量改大,后期hbase经常会因为该问题频繁宕机-->
- <property>
- <name>dfs.client.socket-timeout</name>
- <value>600000</value>
- </property>
- <!--
- hbase.table.sanity.checks是一个开关,主要用于hbase各种参数检查,当为true时候,检查步骤如下
- 1.check max file size,hbase.hregion.max.filesize,最小为2MB
- 2.check flush size,hbase.hregion.memstore.flush.size,最小为1MB
- 3.check that coprocessors and other specified plugin classes can be loaded
- 4.check compression can be loaded
- 5.check encryption can be loaded
- 6.Verify compaction policy
- 7.check that we have at least 1 CF
- 8.check blockSize
- 9.check versions
- 10.check minVersions <= maxVerions
- 11.check replication scope
- 12.check data replication factor, it can be 0(default value) when user has not explicitly set the value, in this case we use default replication factor set in the file system.
- 详细情况可以去查看源代码org.apache.hadoop.hbase.master.HMaster的方法sanityCheckTableDescriptor,
- 该代码位于hbase源码的模块hbase-server下
- -->
- <property>
- <name>hbase.table.sanity.checks</name>
- <value>false</value>
- </property>
- <!--ZooKeeper 会话超时.HBase把这个值传递改zk集群,向他推荐一个会话的最大超时时间-->
- <property>
- <!--every 30s,the master will check regionser is working -->
- <name>zookeeper.session.timeout</name>
- <value>30000</value>
- </property>
- <!-- Hbase的外置zk集群时,使用下面的zk端口。因为我这5台机子打算都安装hbase,所以都指定zookeeper。
- 有个问题就是,hbase和hadoop使用同一个zookeeper,是否可以,这样如果某台服务器上的某个应用挂了,zookeeper会不会认错。
- 把这个机子上挂的A应用误会成B应用呢
- -->
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>xxCentosZero:2181,xxCentosOne:2181,xxCentosTwo:2181,xxCentosThree:2181,xxCentosFour:2181</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/usr/local/zookeeper/data</value>
- </property>
- </configuration></span>
我本地使用的是这个较详细版本。
3,修改/usr/local/hbase/conf/regionservers
- <span style="font-family:KaiTi_GB2312;font-size:14px;">xxCentosTwo
- xxCentosThree
- xxCentosFour</span>
需要修改的配置文件基本来说就这三个,但是需要注意的是
因为hbase所支持的最稳定的hadoop版本未必与你下载的hadoop版本一致,所以建议最好将你的hadoop中的一些jar包替换到hbase
安全起见,我是把/usr/local/hbase/lib/路径下的hadoop开头的jar包都替换了一遍,旧版本改名做备份,以便恢复用
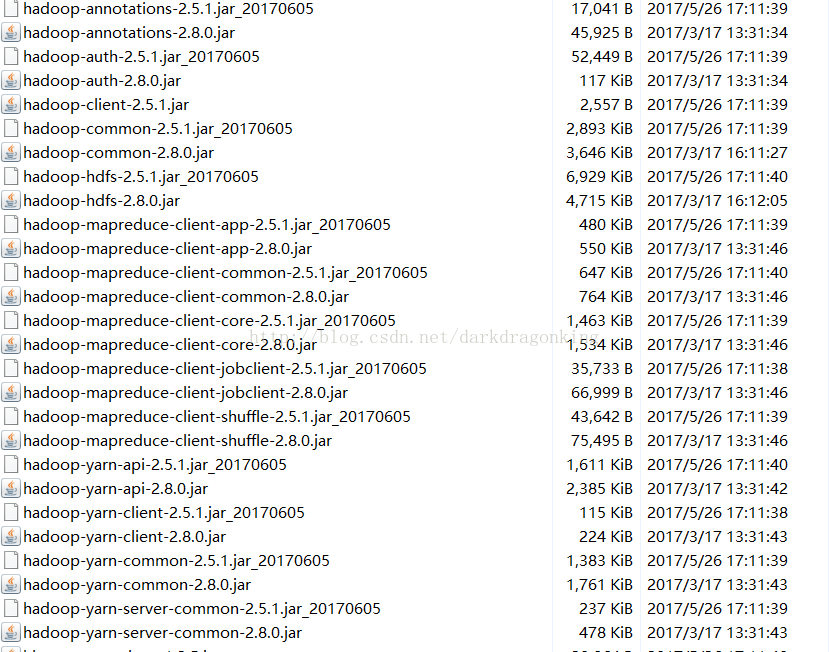
然后分发到各个服务器上
三、启动
在保证hadoop和zookeeper启动的前提下,启动hbase即可
- <span style="font-family:KaiTi_GB2312;font-size:14px;">/usr/local/hbase/bin/start-hbase.sh</span>
如果正常启动,可以看到hbase的主页了
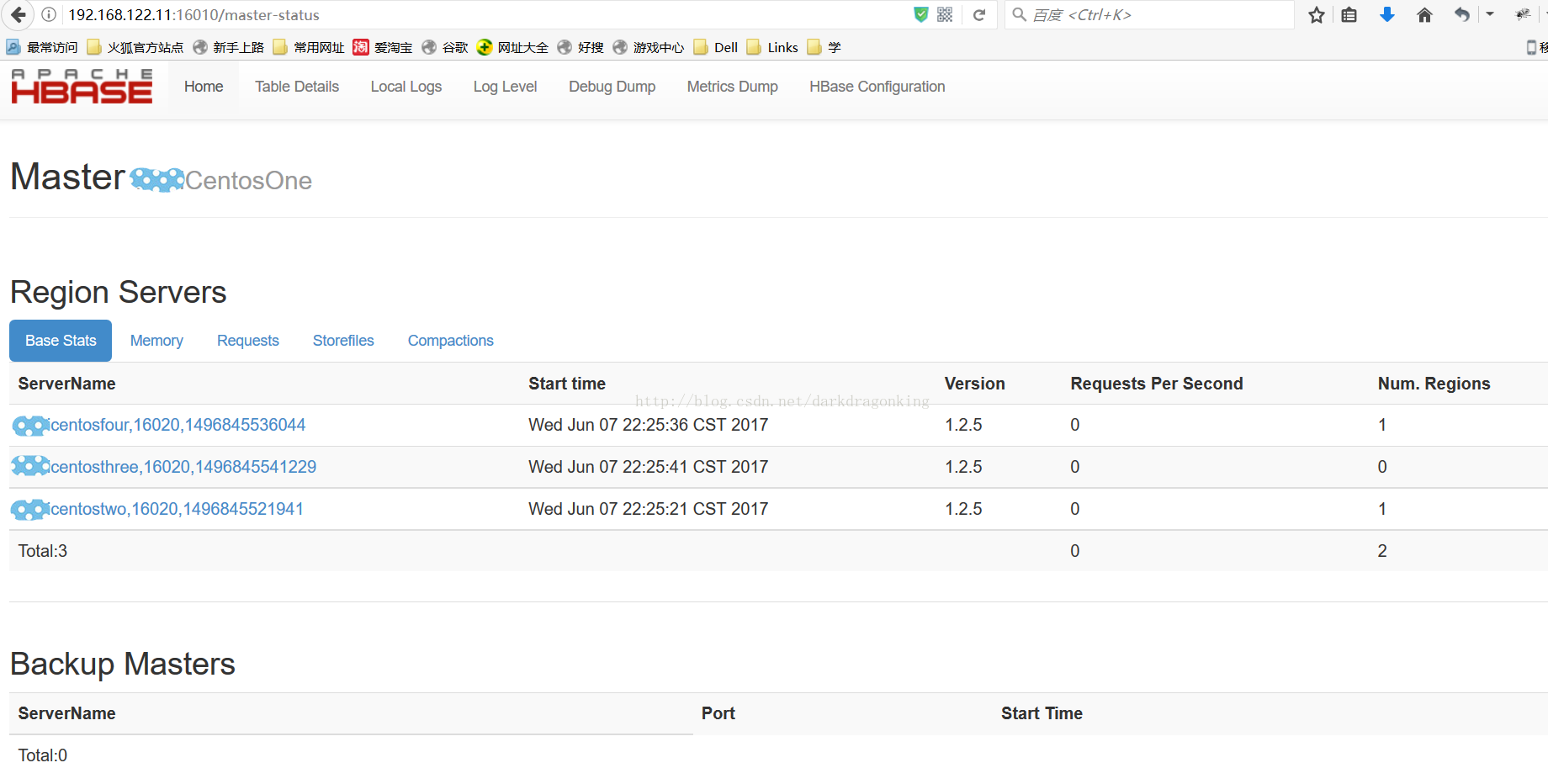
在HMaster服务器上执行hbase shell能看到类似下面的东西

上图是没有报错的正常情况
四、说说遇到的问题吧
1:zookeeper和hdfs最好重新格式化
本来以为,在启动过hbase之后甚至启动hbase之前,需要重新格式化一次zookeeper。以确保在zookeeper的目录下,产生hbase相关的东西。不过我最终没有做格式化zookeeper这一步,但是在zookeeper的目录下仍然看到对应的目录了。
但是在第一次启动之后,执行hbase shell看到一些报错信息
- <span style="font-family:KaiTi_GB2312;font-size:14px;">SLF4J: Class path contains multiple SLF4J bindings.
- SLF4J: Found binding in [jar:file:/usr/hbase/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: Found binding in [jar:file:/usr/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
- SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.</span>
需要删掉重复的jar包,也就是删掉下面的这个即可
- <span style="font-family:KaiTi_GB2312;font-size:14px;">/usr/hbase/lib/slf4j-log4j12-1.6.4.jar</span>
2:重新格式化后的报错信息
- <span style="font-family:KaiTi_GB2312;font-size:14px;">ERROR:org.apache.hadoop.hbase.PleaseHoldException: Master is initializing</span>
网上搜了下,发现hbase-site.xml中的hbase.rootdir对应的value没有端口号。加上再分发到每个服务器,重启就好了。
其实就是最早我的hbase-site.xml是这样的
- <span style="font-family:KaiTi_GB2312;font-size:14px;"><property>
- <name>hbase.rootdir</name>
- <value>hdfs://lwns/hbase</value><!--这里必须跟core-site.xml中的fs.defaultFS键配置一样-->
- </property></span>
既没有端口号,同时我写的是HA的别名,然后我开始保持集群名不变,加上了端口号9000.启动,
执行hbase shell进入后,执行status或list,仍然报错。但是错误信息改变了,如下所示
- <span style="font-family:KaiTi_GB2312;font-size:14px;">ERROR: Can't get master address from ZooKeeper; znode data == null </span>
有的说重启hbase就好了。还有的说要重新格式化hadoop的namenode
我选择先重启。发现起不来。查看日志,显示如下
- <span style="font-family:KaiTi_GB2312;font-size:14px;">java.lang.RuntimeException: Failed construction of Master: class org.apache.hadoop.hbase.master.HMaster.
- at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2512)
- at org.apache.hadoop.hbase.master.HMasterCommandLine.startMaster(HMasterCommandLine.java:231)
- at org.apache.hadoop.hbase.master.HMasterCommandLine.run(HMasterCommandLine.java:137)
- at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
- at org.apache.hadoop.hbase.util.ServerCommandLine.doMain(ServerCommandLine.java:126)
- at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:2522)
- Caused by: java.io.IOException: Port 9000 specified in URI hdfs://lwns:9000/hbase but host 'lwns' is a logical (HA) namenode and does not use port information.
- at org.apache.hadoop.hdfs.NameNodeProxiesClient.createFailoverProxyProvider(NameNodeProxiesClient.java:254)
- at org.apache.hadoop.hdfs.NameNodeProxiesClient.createProxyWithClientProtocol(NameNodeProxiesClient.java:124)
- at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:343)
- at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:287)
- at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:156)
- at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2811)
- at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:100)
- at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2848)
- at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2830)
- at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:389)
- at org.apache.hadoop.fs.Path.getFileSystem(Path.java:356)
- at org.apache.hadoop.hbase.util.FSUtils.getRootDir(FSUtils.java:1003)
- at org.apache.hadoop.hbase.regionserver.HRegionServer.initializeFileSystem(HRegionServer.java:609)
- at org.apache.hadoop.hbase.regionserver.HRegionServer.<init>(HRegionServer.java:564)
- at org.apache.hadoop.hbase.master.HMaster.<init>(HMaster.java:412)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
- at org.apache.hadoop.hbase.master.HMaster.constructMaster(HMaster.java:2505)
- ... 5 more</span>
考虑还是我的hbase-site.xml的“hbase.rootdir”属性的问题。我改成不使用hadoop的HA的别名,直接使用HMaster的主机名
- <span style="font-family:KaiTi_GB2312;font-size:14px;"><property>
- <name>hbase.rootdir</name>
- <value>hdfs://xxCentosOne:9000/hbase</value>
- </property></span>
3、解决了上面的问题后,执行hbase shell,进入执行list,再次有问题
又出现第一次的错误ERROR:org.apache.hadoop.hbase.PleaseHoldException: Master is initializing
继续查,网上说可以尝试先分别启动regionserver,再启动hmaster,我尝试了,仍然同样的问题。
只好尝试删除NameNode的tmp文件夹和zookeeper的data文件夹下的version内容,然后重新格式化NameNode和zookeeper
为了安全起见,将/usr/local/hadoop/journalnode/下的内容也一起删除。
这是因为在格式化zk和hadoop的namenode的时候,会涉及到JournalNode的东西
然后我先把每台hadoop中的tmp文件夹清空,再把somedata文件夹清空(这个文件夹是存放NameNode或DataNode节点的数据的,
同时它是在hdfs-site.xml配置文件的dfs.namenode.name.dir和dfs.datanode.name.dir里面对应的路径得到的)
然后再把zookeeper下的data路径下的version-2文件夹清空(zoo.cfg中的dataDir键对应的值)
后面的格式化和重启过程在这里就不赘述了。详见上一篇文章
该格式化和重启的都弄完,重启hbase,跟踪日志,发现错误如下
- <span style="font-family:KaiTi_GB2312;font-size:14px;">2017-06-07 00:48:57,661 INFO [xxCentosOne:16000.activeMasterManager] zookeeper.MetaTableLocator: Failed verification of hbase:meta,,1 at address=xxcentosfour,
- 16020,1496766839655, exception=org.apache.hadoop.hbase.NotServingRegionException: Region hbase:meta,,1 is not online on xxcentosfour,16020,1496767744442
- at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:2942)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1072)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionInfo(RSRpcServices.java:1356)
- at org.apache.hadoop.hbase.protobuf.generated.AdminProtos$AdminService$2.callBlockingMethod(AdminProtos.java:22233)
- at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2188org.apache.hadoop.fs.PathIsNotEmptyDirectoryException)
- at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
- at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
- at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
- at java.lang.Thread.run(Thread.java:745)</span>
然后再报出这个错误之前,还有一个错误,就是hbase.hregion.max.filesize这个键对应的值不正确
我配置的值是"128M"。既然说不对,我查了下网上的别人写法,有人写成"1G",有人写成"134217728"这样的形式,我选择了后者。修改并分发到所有主机上
再重启,上面的"Failed verification of hbase"仍然会出现,但是我再执行"hbase shell"和"status","list"都不会报错了。说明可以正常启动了。
2017-06-07:追加报错与解决
当我重启了几台虚拟机之后,再次启动hbase,发现hmaster服务器的日志中还是有报错信息,然后我追查了一下
- <span style="font-family:KaiTi_GB2312;font-size:14px;">org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.fs.PathIsNotEmptyDirectoryException): `/hbase/WALs/xxcentosthree,16020,1496845541229-splitting is non empty': Directory is not empty
- at org.apache.hadoop.hdfs.server.namenode.FSDirDeleteOp.delete(FSDirDeleteOp.java:115)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.delete(FSNamesystem.java:2783)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.delete(NameNodeRpcServer.java:1047)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.delete(ClientNamenodeProtocolServerSideTranslatorPB.java:626)
- at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
- at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
- at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:845)
- at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:788)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1807)
- at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2455)
- at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1481)
- at org.apache.hadoop.ipc.Client.call(Client.java:1427)
- at org.apache.hadoop.ipc.Client.call(Client.java:1337)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
- at com.sun.proxy.$Proxy14.delete(Unknown Source)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.delete(ClientNamenodeProtocolTranslatorPB.java:559)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:398)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
- at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:335)
- at com.sun.proxy.$Proxy15.delete(Unknown Source)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.hbase.fs.HFileSystem$1.invoke(HFileSystem.java:279)
- at com.sun.proxy.$Proxy16.delete(Unknown Source)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.hbase.fs.HFileSystem$1.invoke(HFileSystem.java:279)
- at com.sun.proxy.$Proxy16.delete(Unknown Source)
- at org.apache.hadoop.hdfs.DFSClient.delete(DFSClient.java:1642)
- at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:794)
- at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:791)
- at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
- at org.apache.hadoop.hdfs.DistributedFileSystem.delete(DistributedFileSystem.java:791)
- at org.apache.hadoop.hbase.master.SplitLogManager.splitLogDistributed(SplitLogManager.java:296)
- at org.apache.hadoop.hbase.master.MasterFileSystem.splitLog(MasterFileSystem.java:398)
- at org.apache.hadoop.hbase.master.MasterFileSystem.splitMetaLog(MasterFileSystem.java:313)
- at org.apache.hadoop.hbase.master.MasterFileSystem.splitMetaLog(MasterFileSystem.java:304)
- at org.apache.hadoop.hbase.master.HMaster.splitMetaLogBeforeAssignment(HMaster.java:1046)
- at org.apache.hadoop.hbase.master.HMaster.assignMeta(HMaster.java:976)
- at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:783)
- at org.apache.hadoop.hbase.master.HMaster.access$600(HMaster.java:189)
- at org.apache.hadoop.hbase.master.HMaster$2.run(HMaster.java:1803)
- at java.lang.Thread.run(Thread.java:745)</span>
开始以括号前面的条件作为条件去百度,结果得到的都是乱七八糟的东西。感觉有问题
然后以括号内为条件去百度。有一个帖子对我有点借鉴作用HBase简介
其中有一段就说这个报错的。里面说进入hadoop系统,删除为空的目录即可。因为那个目录不是普通的Linux文件系统的目录
然后我执行hadoop fs -ls /hadoop/WALs发现
- <span style="font-family:KaiTi_GB2312;font-size:14px;">ls: Port 9000 specified in URI hdfs://lwns:9000 but host 'lwns' is a logical (HA) namenode and does not use port information.</span>
很奇怪的错误,字面意思是这个HA的别名不应该有端口号
然后我检查了一下我的hadoop下的core-site.xml文件fs.defaultFS这个键对应的值中,果然有端口号
然后去掉端口号,分发到其他服务器上。重启。却告诉我有一个文件找不到
- <span style="font-family:KaiTi_GB2312;font-size:14px;">stopping hbasecat: /tmp/hbase-root-master.pid: No such file or directory</span>
其实就是记录了当前这个HRegionServer或者HMaster的进程号。
jps了一下那几个HRegionServer的服务器,发现HRegionServer进程都存在
然后在HMaster服务器上jps,不存在这个进程。。。。
考虑直接启动HMaster试试看
- <span style="font-family:KaiTi_GB2312;font-size:14px;">单独启动某台服务器的regionserver
- /usr/local/hbase/bin/hbase-daemon.sh start regionserver
- 启动集群所有regionserver
- /usr/local/hbase/bin/hbase-daemons.sh start regionserver
- 单独启动hmaster
- /usr/local/hbase/bin/hbase-daemon.sh start master</span>
同时跟踪日志,发现报错
- <span style="font-family:KaiTi_GB2312;font-size:14px;">2017-06-08 05:22:47,566 FATAL [xxCentosOne:16000.activeMasterManager] master.HMaster: Unhandled exception. Starting shutdown.
- org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error
- at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:88)
- at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1896)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1346)
- at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:2924)
- at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:1106)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:858)
- at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:447)
- at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:989)
- at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:845)
- at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:788)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1807)
- at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2455)
- at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1481)
- at org.apache.hadoop.ipc.Client.call(Client.java:1427)
- at org.apache.hadoop.ipc.Client.call(Client.java:1337)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227)
- at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
- at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
- at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:787)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:398)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155)
- at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
- at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:335)
- at com.sun.proxy.$Proxy15.getFileInfo(Unknown Source)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.hbase.fs.HFileSystem$1.invoke(HFileSystem.java:279)
- at com.sun.proxy.$Proxy16.getFileInfo(Unknown Source)
- at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1700)
- at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1436)
- at org.apache.hadoop.hdfs.DistributedFileSystem$27.doCall(DistributedFileSystem.java:1433)
- at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
- at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1433)
- at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1436)
- at org.apache.hadoop.hbase.master.MasterFileSystem.checkRootDir(MasterFileSystem.java:431)
- at org.apache.hadoop.hbase.master.MasterFileSystem.createInitialFileSystemLayout(MasterFileSystem.java:153)
- at org.apache.hadoop.hbase.master.MasterFileSystem.<init>(MasterFileSystem.java:128)
- at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:693)
- at org.apache.hadoop.hbase.master.HMaster.access$600(HMaster.java:189)
- at org.apache.hadoop.hbase.master.HMaster$2.run(HMaster.java:1803)
- at java.lang.Thread.run(Thread.java:745)
- 2017-06-08 05:22:47,566 INFO [xxCentosOne:16000.activeMasterManager] regionserver.HRegionServer: STOPPED: Unhandled exception. Starting shutdown.</span>
根据字面意思,是说不能在standby的hadoop上启动hmaster。真的是吗
我打开页面,访问192.168.122.10和11两台服务器的50070端口,果然,11是standby,10是active
熟悉我这个架构的朋友应该知道,我的11是设计为active的hadoop,10是设计为standby的hadoo
同时10服务器上没有安装hbase
问题因该就在这里了,就是11在这次启动的时候成为了standby的hadoop所以才不能在这种hadoop上启动hmaster
然后杀掉所有HRegionServer,再重启整个hadoop,确认192.168.122.11服务器是active后,再启动hbase
发现11服务器上已经起来了HMaster进程。
2017-06-08:
继续处理昨天那个“路径非空”的问题
- <span style="font-size:14px;">2017-06-08 17:33:18,766 INFO [xxCentosOne:16000.activeMasterManager] zookeeper.MetaTableLocator: Failed verification of hbase:meta,,1 at address=xxcentosthree,16020,1496912989215, exception=org.apache.hadoop.hbase.NotServingRegionException: Region hbase:meta,,1 is not online on xxcentosthree,16020,1496914404566
- at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:2942)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1072)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionInfo(RSRpcServices.java:1356)
- at org.apache.hadoop.hbase.protobuf.generated.AdminProtos$AdminService$2.callBlockingMethod(AdminProtos.java:22233)
- at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2188)
- at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
- at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
- at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
- at java.lang.Thread.run(Thread.java:745)</span>
然后可以看到这个路径下有好多东西,删除掉提示说非空的那些路径即可。
完毕后,重启hbase,跟踪日志,报下面的错误
- <span style="font-size:14px;">2017-06-08 17:33:18,766 INFO [xxCentosOne:16000.activeMasterManager] zookeeper.MetaTableLocator: Failed verification of hbase:meta,,1 at address=xxcentosthree,16020,1496912989215, exception=org.apache.hadoop.hbase.NotServingRegionException: Region hbase:meta,,1 is not online on xxcentosthree,16020,1496914404566
- at org.apache.hadoop.hbase.regionserver.HRegionServer.getRegionByEncodedName(HRegionServer.java:2942)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegion(RSRpcServices.java:1072)
- at org.apache.hadoop.hbase.regionserver.RSRpcServices.getRegionInfo(RSRpcServices.java:1356)
- at org.apache.hadoop.hbase.protobuf.generated.AdminProtos$AdminService$2.callBlockingMethod(AdminProtos.java:22233)
- at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2188)
- at org.apache.hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
- at org.apache.hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
- at org.apache.hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
- at java.lang.Thread.run(Thread.java:745)</span>
网上说这是某个regionserver处于offline状态。
首先执行hbase hbck,用来检查hbase的一致性(类似于hadoop fsck命令,fsck是用来检查hdfs的不一致问题的命令)
如果发现问题,可以使用hbase hbck -fix修复
但是我执行了hbase hbck之后,貌似没有问题
- <span style="font-size:14px;">Version: 1.2.5
- Number of live region servers: 3
- Number of dead region servers: 0
- Master: xxcentosone,16000,1496914389895
- Number of backup masters: 0
- Average load: 0.6666666666666666
- Number of requests: 0
- Number of regions: 2
- Number of regions in transition: 0
- 2017-06-08 17:43:00,449 INFO [main] util.HBaseFsck: Loading regionsinfo from the hbase:meta table
- Number of empty REGIONINFO_QUALIFIER rows in hbase:meta: 0</span>
- <span style="font-size:14px;">Table hbase:meta is okay.
- Number of regions: 1
- Deployed on: xxcentosthree,16020,1496914404566
- Table hbase:namespace is okay.
- Number of regions: 1
- Deployed on: xxcentosfour,16020,1496914405385
- 0 inconsistencies detected.
- Status: OK</span>
怀疑又是启动过程中出现的临时错误吧。暂时不做处理
不过把别人的解决方式放到下面做个记录
方案一:
1 ) 停掉hbase集群
2)删除hbase在hdfs目录下所有表目录下的recovered.edits
3)重启hbase集群,所有的region就都online了
注意,这种通过删除recovered.edits的方式来恢复集群,会丢失部分数据。
方案二:
根据上面的思路,我们需要在集群所有RegionServer的hbase-site.xml配置文件里面增加如下配置:
<property>
<name>hbase.regionserver.executor.openregion.threads</name>
<value>100</value>
</property>然后重启HBase集群就可以了。
这种解决方案应该不会丢数据,推荐使用这种方式来恢复。
HRegionServer的一些配置信息
参数名称
| 默认值 | 含义 | |
| hbase.client.retries.number | 10 | 客户端的重试次数 |
| hbase.regionserver.msginterval | 3000 | 未知 |
| hbase.regionserver.checksum.verify | false | 是否启用hbase的 checksum |
| hbase.server.thread.wakefrequency | 10秒 | 检查线程的频率 |
| hbase.regionserver.numregionstoreport | 10 | 未知 |
| hbase.regionserver.handler.count | 10 | 处理用户表的工作 线程数量 |
| hbase.regionserver.metahandler.count | 10 | 处理meta和root表 的工作线程数量 |
| hbase.rpc.verbose | false | 未知 |
| hbase.regionserver.nbreservationblocks | false | 未知 |
| hbase.regionserver.compactionChecker. majorCompactPriority | max int | 未知 |
| hbase.regionserver.executor.openregion.threads | 3 | 开打用户表region 的线程数量 |
| hbase.regionserver.executor.openroot.threads | 1 | 打开root表region 的线程数量 |
| hbase.regionserver.executor.openmeta.threads | 1 | 打开meta表region 的线程数量 |
| hbase.regionserver.executor.closeregion.threads | 3 | 关闭用户表region 的线程数量 |
| hbase.regionserver.executor.closeroot.threads | 1 | 关闭root表region 的线程数量 |
| hbase.regionserver.executor.closemeta.threads | 1 | 关闭meta表region 的线程数量 |
2017-06-11:新增HMaster的高可用配置
在文章的开篇我就写过,有一个叫xxCentosZero的主机,我是打算做HMaster的备份的但是之前不会配置HMaster的高可用,所以就一直搁置了下来
最近参考了一篇帖子,感觉不错,尝试了一下,竟然成功了 有一种帖子叫人家的帖子
那篇文章感兴趣的诸位可以看看,我就说我改动的地方吧
1、各种配置文件
hbase-site.xml
- <!--这里必须跟core-site.xml中的fs.defaultFS键配置一样。-->
- <!--
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://xxCentosOne:9000/hbase</value>
- </property>
- -->
- <!-- 原本我在这里写的是某一台主机的名称外加端口。然后参考了一些别人的帖子,以及打算超HMaster的HA方向努力
- 所以尝试了一下去掉HMaster的主机名,改为hadoop的hdfs的集群名称,并且去掉端口号。 -->
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://lwns/hbase</value>
- </property>
- <!-- 如果只配置端口,为了配置多个HMaster(HMaster的HA),否则就是单HMaster模式 -->
- <!--
- <property>
- <name>hbase.master</name>
- <value>xxCentosOne:60000</value>
- </property>
- -->
- <property>
- <name>hbase.master</name>
- <value>60000</value>
- </property>
上面我注释掉的地方就是我之前的非HA的写法,保留下来的是HA的写法。
通过对比可知,其实就是将过去写死成服务器名称的地方或者改为hdfs的NameSpace,就是将原有的主机名去掉,只留端口
2、hadoop的core-site.xml的写法。我就上一个地方, 用以和hbase-site.xml对比使用
- <!-- 指定hdfs的nameservice为lw_ns,需要与hdfs-site.xml中的名字一致。注意好像这里不可以有端口号 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://lwns</value>
- </property>
区别只是在于,hbase-site.xml中在hdfs;//lwns后面加上了"/hbase"而已。
3、启动
记得我之前说过,在standby的hadoop上面是无法启动HMaster的么,我之前说的应该不够详细
之前的详细情况是这样的。
在没有修改hbase-site.xml配置文件的前提下,启动了所有的zookeeper,并且启动了hadoop集群之后
只能在状态为active的hadoop的NameNode上面启动hbase(执行/usr/local/hbase/bin/start-hbase.sh )
否则在状态为standby的hadoop的NameNode上执行上面的命令,会提示hadoop的NameNode状态不对的错误
核心原因就是在于,hbase-site.xml中hbase.rootdir和hbase.master写死了主机名的原因。
现在我们则不需要考虑hadoop的NameNode是否standby状态的问题了,
可以任意在某一个NameNode上执行/usr/local/hbase/bin/start-hbase.sh。都可以启动当前这个HMaster和所有的HRegionServer
而其他的HMaster,则需要在每台主机上分别执行/usr/local/hbase/bin/hbase-daemon.sh start master来启动
4、效果及对比
启动后可以在前台看到当前的HMaster和备份的HMaster的区别,如下图
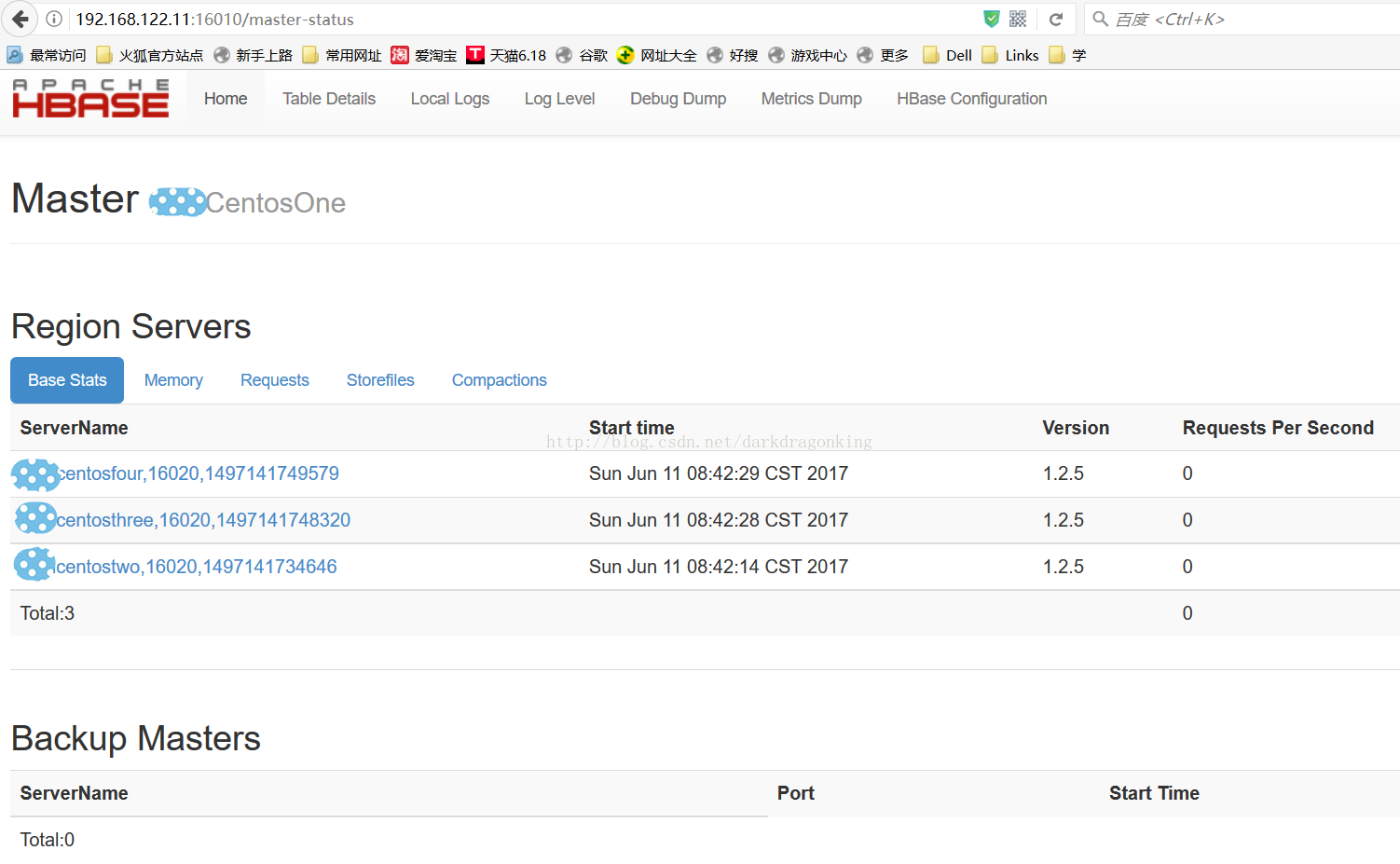
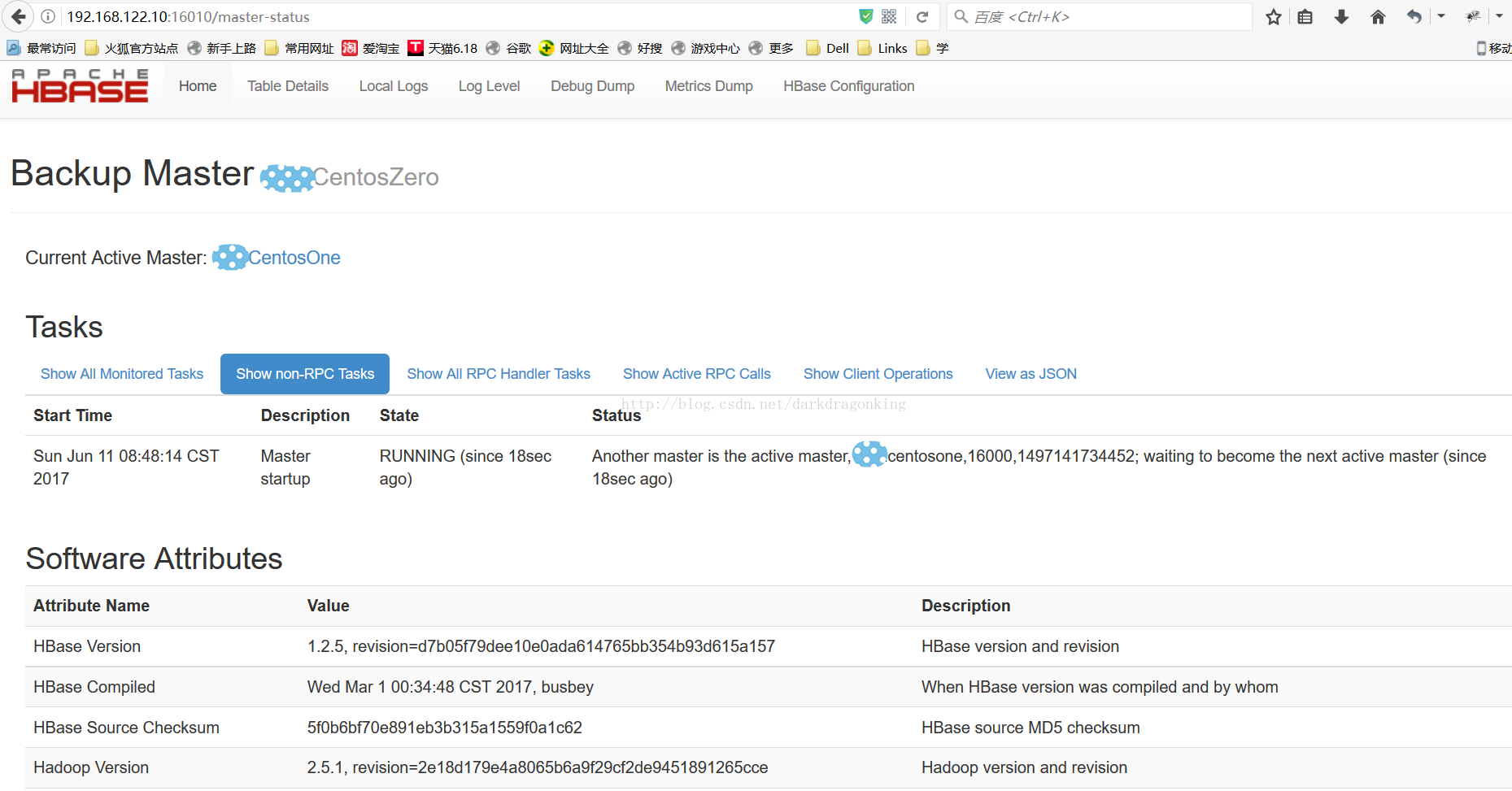
从日志中也能看到备份HMaster与当前HMaster的区别
- 2017-06-11 08:48:13,156 INFO [RpcServer.responder] ipc.RpcServer: RpcServer.responder: starting
- 2017-06-11 08:48:13,160 INFO [RpcServer.listener,port=16000] ipc.RpcServer: RpcServer.listener,port=16000: starting
- 2017-06-11 08:48:13,393 INFO [main] mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
- 2017-06-11 08:48:13,402 INFO [main] http.HttpRequestLog: Http request log for http.requests.master is not defined
- 2017-06-11 08:48:13,427 INFO [main] http.HttpServer: Added global filter 'safety' (class=org.apache.hadoop.hbase.http.HttpServer$QuotingInputFilter)
- 2017-06-11 08:48:13,427 INFO [main] http.HttpServer: Added global filter 'clickjackingprevention' (class=org.apache.hadoop.hbase.http.ClickjackingPreventionFilter)
- 2017-06-11 08:48:13,429 INFO [main] http.HttpServer: Added filter static_user_filter (class=org.apache.hadoop.hbase.http.lib.StaticUserWebFilter$StaticUserFilter) to context master
- 2017-06-11 08:48:13,429 INFO [main] http.HttpServer: Added filter static_user_filter (class=org.apache.hadoop.hbase.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
- 2017-06-11 08:48:13,430 INFO [main] http.HttpServer: Added filter static_user_filter (class=org.apache.hadoop.hbase.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
- 2017-06-11 08:48:13,459 INFO [main] http.HttpServer: Jetty bound to port 16010
- 2017-06-11 08:48:13,460 INFO [main] mortbay.log: jetty-6.1.26
- 2017-06-11 08:48:14,186 INFO [main] mortbay.log: Started SelectChannelConnector@0.0.0.0:16010
- 2017-06-11 08:48:14,194 INFO [main] master.HMaster: hbase.rootdir=hdfs://lwns/hbase, hbase.cluster.distributed=true
- 2017-06-11 08:48:14,226 INFO [main] master.HMaster: Adding backup master ZNode /hbase/backup-masters/xxcentoszero,16000,1497142091312
- 2017-06-11 08:48:14,445 INFO [xxCentosZero:16000.activeMasterManager] <span style="background-color: rgb(255, 255, 102);"><span style="color:#FF6666;">master.ActiveMasterManager: Another master is the active master, xxcentosone,16000,1497141734452; waiting to become the next active master</span></span>
- 2017-06-11 08:48:14,555 INFO [master/xxCentosZero/192.168.122.10:16000] zookeeper.RecoverableZooKeeper: Process identifier=hconnection-0x66c6b2fe connecting to ZooKeeper ensemble=xxCentosZero:2181,xxCentosOne:2181,xxCentosTwo:2181,xxCentosThree:2181,xxCentosFour:2181
- 2017-06-11 08:48:14,561 INFO [master/xxCentosZero/192.168.122.10:16000] zookeeper.ZooKeeper: Initiating client connection, connectString=xxCentosZero:2181,xxCentosOne:2181,xxCentosTwo:2181,xxCentosThree:2181,xxCentosFour:2181 sessionTimeout=30000 watcher=hconnection-0x66c6b2fe0x0, quorum=xxCentosZero:2181,xxCentosOne:2181,xxCentosTwo:2181,xxCentosThree:2181,xxCentosFour:2181, baseZNode=/hbase
- 2017-06-11 08:48:14,565 INFO [master/xxCentosZero/192.168.122.10:16000-SendThread(xxCentosTwo:2181)] zookeeper.ClientCnxn: Opening socket connection to server xxCentosTwo/192.168.122.12:2181. Will not attempt to authenticate using SASL (unknown error)
- 2017-06-11 08:48:14,568 INFO [master/xxCentosZero/192.168.122.10:16000-SendThread(xxCentosTwo:2181)] zookeeper.ClientCnxn: Socket connection established to xxCentosTwo/192.168.122.12:2181, initiating session
- 2017-06-11 08:48:14,573 INFO [master/xxCentosZero/192.168.122.10:16000-SendThread(xxCentosTwo:2181)] zookeeper.ClientCnxn: Session establishment complete on server xxCentosTwo/192.168.122.12:2181, sessionid = 0x25c947d51cd0005, negotiated timeout = 30000
- 2017-06-11 08:48:14,636 INFO [master/xxCentosZero/192.168.122.10:16000] regionserver.HRegionServer: ClusterId : 9d1223e6-9947-422e-a966-94d9e48d101f
到这里,HMaster的高可用可以告一段落了。
转载自:http://blog.csdn.net/darkdragonking/article/details/72901330















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









