







备注:本文是阅读一篇硕士论文《大规模数据聚类技术研究与实现》后的笔记整理,敬请阅读,并向原作者钱彦江致敬
<一>概念透析
1、什么是聚类?
基于“物以类聚”的朴素思想,是将物理或抽象对象集合划分为由类似的对象组成的多个类或簇(cluster)的过程
ps:聚类使得每个簇中的数据点之间最大程度的相似,而不同簇中的数据点之间最大程度的不同
2、聚类分析的数学描述
给定数据集合V={vi|i=1,2,…,n},其中Vi为数据对象,根据数据对象间的相似程度将数据集合分成k组,{Cj|j=1,2,…,k},Cj⊆V,并满足:
1)Ci ∩ Cj=Φ,i≠j
2)⋃Ci=V
则该过程称为聚类,Ci,i=1,2,…,k成为簇
3、小结
在机器学习领域聚类与分类不同,它是一种无监督的学习过程。聚类一般没有训练过程,它直接处理未知样本,把这些样本聚合成不同的簇。
<二>聚类分析中的数据结构和数据类型
1、数据结构(这里仅介绍两种具有代表性的数据结构)
(1)数据矩阵(data matrix,也称对象—变量结构)
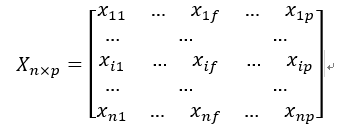
用p个属性(也称度量)来表现n个对象
(2)相异度矩阵(dissimilarity matrix,也称对象—对象结构)
存储n个对象两两之间的相异性(或相似性), 表现形式是一个n*n维的矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















10-26
07-09
 1786
1786
1786
02-19
3571
3571
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









