







搭建完全分布式环境是在会先搭建单节点的伪分布式环境上面进行的,先拷贝一份伪分布式的hadoop安装程序,jdk安装之类的就先不讲了,然后再伪分布式环境上对配置文件进行修改,
首先看下配置文件吧
core-size.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 把dfs系统放在第一台服务了,就是hadoop1-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://learn.hadoop1.com:8020</value>
</property>
<!--格式化的临时目录 只有做格式化的时候这个属性有用 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/moduels/hadoop-2.5.0/data/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
</configuration>
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--设置几个dfs应用 我们设置是3 默认也是3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- secondarynamenode节点服务器放在的第一台 就是hadoop1 ,想放哪里 改成自己对应的服务器就行-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>learn.hadoop1.com:50090</value>
</property>
</configuration>
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史服务器放在了第一台服务器 就是hadoop1 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>learn.hadoop1.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>learn.hadoop1.com:19888</value>
</property>
</configuration>
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置集群 并把yarn运行在第二台服务器上面 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>learn.hadoop2.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
</configuration>
<!-- 配置做完全分布式的服务器的地址 这里放的是主机名...-->
learn.hadoop1.com
learn.hadoop2.com
learn.hadoop3.com然后开始操作..
1、这里已部署三台机器为例,修改上述中的几个配置文件,然后scp到其他两台服务器上,注意做集群的时候先做好SSH免密登录,要不然等下机器会出现没法通信问题。我们知道在伪分布式环境中,我们需要启动这几个节点,namenode节点,datanode节点,resourcemanager节点,nodemanager节点,secondarynamenode节点,historyserver几点,那么完全分布式环境其实就把这几个节点放到不同的服务器上面,然后可以相互通信,完成hadoop的各个功能,因此按照上面的配置文件,完全分布式环境拆分为:
第一台服务器作为namenode节点主服务器(主服务器就是只启动一台的意思,其实就是分担压力)
第一第二第三放datanode节点服务器
第二台服务器放resourcemanager节点主服务
第一第二第三放nodemanager节点服务器
第一台服务器放secondarynamenode节点主服务器
第一台服务器放historyserver节点主服务器
总结起来就是: hadoop的完全分布式环境也就是namnode只部署一台(1),datanode部署三台(1,2,3),resourcemanager节点部署一台(2),nodemanager部署三台(1,2,3),secondarynamenode部署一台(1),historyserver部署一台(1),至于这写节点怎么放 放哪里看自己决定,我这里没有把第三台服务器作为一个节点的主服务,是我当初放的时候没注意.......
2、三台服务器都发送好了之后,我们需要做格式化
[hadoop@learn hadoop-2.5.0]$ bin/hdfs namenode -format 在哪台服务器上格式化那就需要看namenode在哪个节点上了,namenode在哪台服务器就在哪里格式化。
格式化好之后就可以按照顺序开始启动hadoop,看下服务是否正常啦...
>>先看namenode的界面,这里的hadoop1就表示服务器1啦。我只有就是方便我自己记忆。

>>在看resourcemanager页面,resourcemanager我是放第二节点服务器的,所以游览器地址是hadoop2
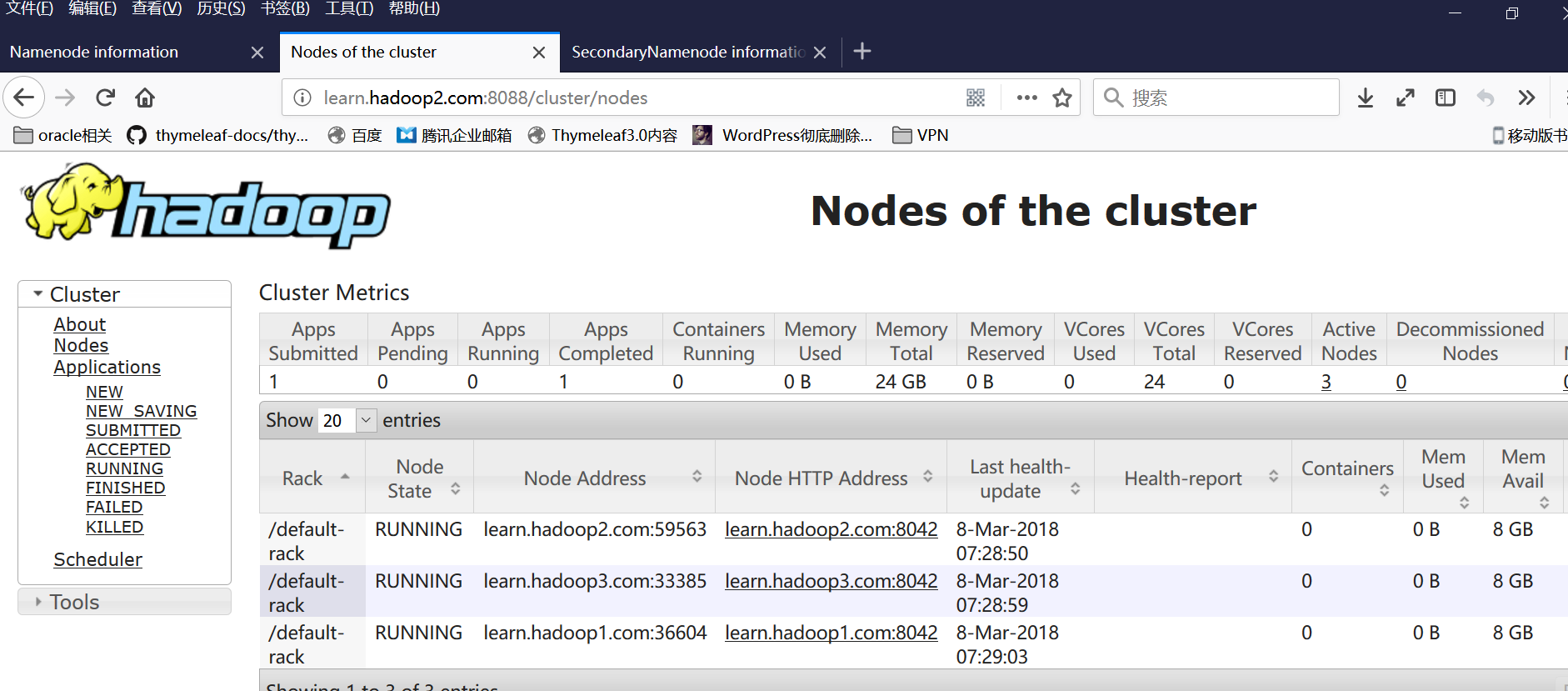
>>最后看secondarynamenode的游览器界面
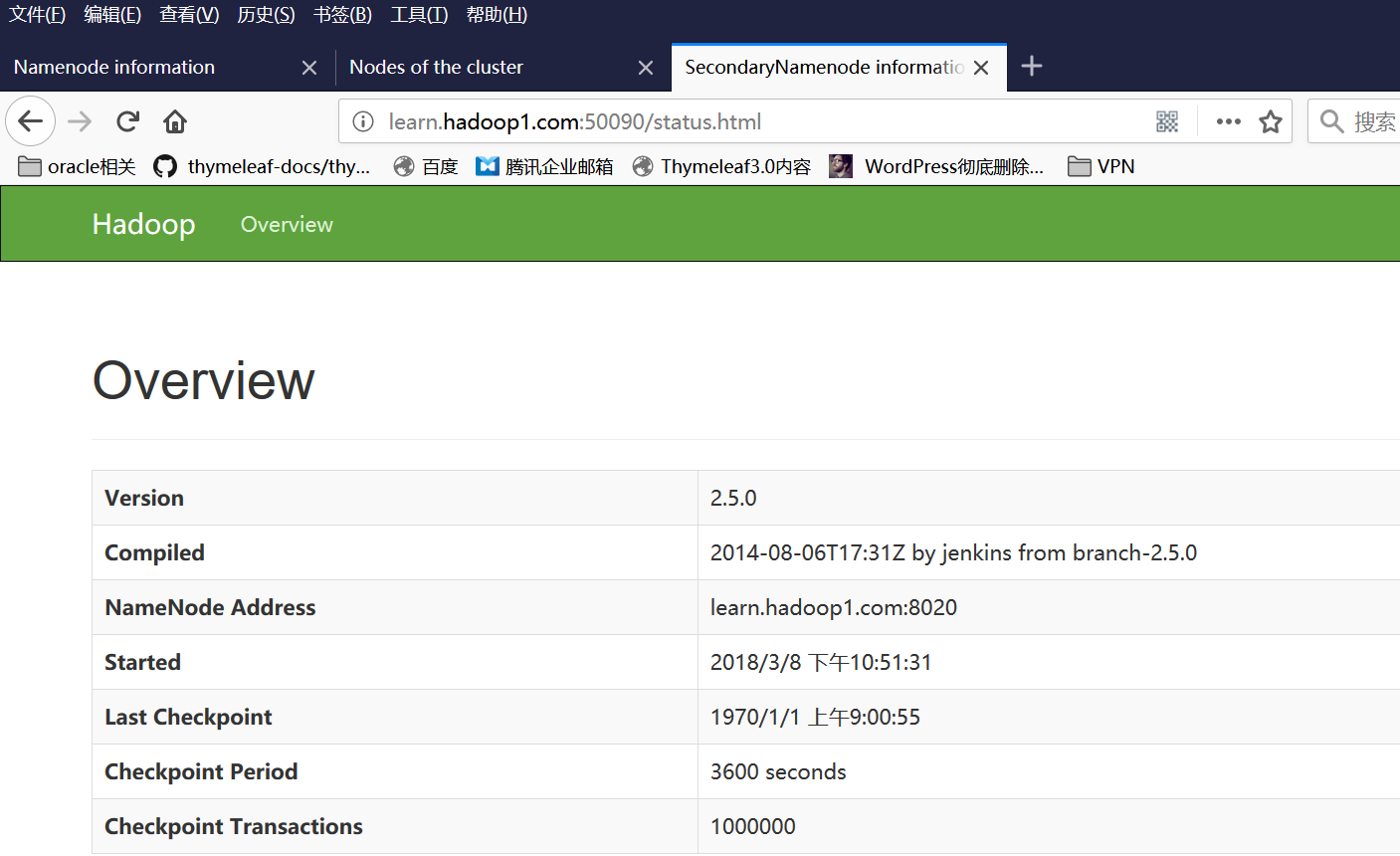
启动顺序就是 这个....
第一台服务器启动namenode|第一第二第三都启动datanode
第二台启动resorcemanager节点
第一第二第三启动nodemanager节点
第一台启动secondarynamenode节点
第一台启动historyserver服务器
最后,自己运行下WordCount程序,试试任务是否正常,历史是否可查看啦...........















 4288
4288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









