







学习目标
-
熟悉正则表达式,能够说出正则表达式的概念和作用
-
掌握正则表达式的创建,能够使用两种方式创建正则表达式
-
掌握正则表达式的使用,能够使用正则表达式进行字符串匹配
-
掌握正则表达式中元字符的使用,能够根据需求选择合适的元字符
-
掌握正则表达式中模式修饰符的使用,能够根据需求选择合适的模式修饰符
-
掌握正则表达式常用方法,能够实现字符串的匹配、分割和替换
项目开发中,经常需要对表单中输入内容的格式进行限制。例如,用户名、密码、手机号、身份证号的格式验证,这些内容遵循的规则繁多而又复杂,如果要成功匹配,可能要编写上百行代码,这种做法显然不可取。此时,就需要使用正则表达式,利用较简短的描述语法完成诸如查找、匹配、替换等功能。本章将围绕如何在JavaScript中使用正则表达式进行详细讲解。
9.1 认识正则表达式
9.1.1 什么是正则表达式
正则表达式(Regular Expression)是一种描述字符串规律的表达式,用于匹配字符串中的特定内容。
正则表达式的灵活性、逻辑性和功能性非常强,运用正则表达式可以迅速地用极简单的方式达到字符串的复杂控制。
最初是由神经学家沃伦·麦卡洛克(Warren McCulloch)和数学家沃尔特·皮茨(Walter Pitts)研究出的一种数学描述方式。
后来《神经网事件的表示法》论文中第一次提出了正则表达式的概念。
之后肯尼斯·蓝·汤普森(Kenneth Lane Thompson)将正则表达式应用到了UNIX的QED编辑器的搜索算法中。
到现在为止,正则表达式已经成为文本编辑器和搜索工具的一个重要部分,并被应用到各种编程语言中。
9.1.2 创建正则表达式
在JavaScript中,正则表达式是一种对象,可以通过以下两种方式创建正则表达式。
利用字面量创建正则表达式,语法格式如下。
/pattern/flags
通过RegExp()构造函数创建正则表达式,语法格式如下。
new RegExp(pattern[, flags])pattern表示模式,用于描述字符串特征,它由元字符和文本字符组成。
flags表示模式修饰符。
元字符是具有特殊含义的字符,例如,元字符“.”表示匹配除换行符、回车符之外的任意单个字符,元字符“*”表示匹配前面的字符零次或多次。
文本字符又称为原义字符,它没有特殊含义,用来表示原本的字符。例如,“a”表示字符a,“1”表示字符1。
模式修饰符用于指定额外的匹配策略,例如,“i”表示忽略大小写。如果不需要指定额外的匹配策略,则模式修饰符可以省略。
使用两种方式创建正则表达式的示例代码如下。
// 使用字面量方式创建正则表达式
var reg = /ab/i;
// 使用RegExp()构造函数创建正则表达式
var reg1 = new RegExp('ab', 'i');9.1.3 使用正则表达式
正则表达式创建完成后,如何使用呢?接下来通过以下3个例子,学习如何使用正则表达式。
检测字符串是否包含敏感词 获取正则表达式匹配结果 获取正则表达式全局匹配结果
test()方法用来检测目标字符串是否匹配正则表达式描述的规则,匹配成功返回true,否则返回false。
使用test()方法检测字符串是否符包含敏感词 admin 的示例代码如下。
var reg = /admin/;
console.log(reg.test('1admin')); // 输出结果:true
console.log(reg.test('address')); // 输出结果:falsematch()方法用于在目标字符串中进行搜索匹配,匹配成功时,该方法的返回值是一个包含附加属性的数组,否则返回null。
使用match()方法获取匹配结果的示例代码如下。
var reg = /a.min/;
// 输出结果:["admin", index: 1, input: "1admin2admin", groups: undefined]
console.log('1admin2admin'.match(reg));
// 输出结果:null
console.log('address'.match(reg));利用match()方法配合模式修饰符g可以获取正则表达式全局匹配结果,模式修饰符g表示全局匹配,也就是匹配到第1个符合正则表达式的内容后继续向后匹配。
匹配字符串'abs abc ads abd ass'中所有字符a和字符s中间包含一个字符的字符串,示例代码如下。
var reg = /a.s/g;
var str = 'abs abc ads abd ass amas';
// 输出结果:(3) ["abs", "ads", "ass"]
console.log(str.match(reg));在使用match()方法时,如果传入一个非正则表达式对象,则会通过RegExp()隐式地将其转换为正则表达式对象。
9.2 正则表达式中的元字符
元字符是具有特殊含义的字符,通过元字符可以描述字符串的特征,从而使正则表达式具有处理字符串的能力。接下来将学习以下元字符。
定位符
中括号、连字符和反义符
反斜线
点字符和限定符
竖线
小括号
9.2.1 定位符
假设有一组英文单词,我们想要匹配以a开头或以e结尾的单词,如何能够轻松地匹配到呢?
通过定位符可以匹配以指定内容开头或以指定内容结尾的字符串。
| 定位符 | 说明 |
|---|---|
| ^ | 匹配以指定内容开头的字符串 |
| $ | 匹配以指定内容结尾的字符串 |
检测一组英文单词“apple”“orange”“melon”“apricot”“banana”中以a开头的单词,示例代码如下。
var reg = /^a/;
console.log(reg.test('apple')); // 输出结果:true
console.log(reg.test('orange')); // 输出结果:false
console.log(reg.test('melon')); // 输出结果:false
console.log(reg.test('apricot')); // 输出结果:true
console.log(reg.test('banana')); // 输出结果:false当“^”和“$”都使用时,表示匹配以指定字符开始并且以指定字符结束的字符串,示例代码如下。
console.log(/^Happy day$/.test('Happy day')); // 输出结果:true
console.log(/^Sad day$/.test('Happy day')); // 输出结果:false9.2.2 中括号、连字符和反义符
开发中,有时需要匹配一个特定范围内的字符,例如,匹配a~z范围内的字符,此时,如果我们不想把所有的情况都写出来,应该如何实现匹配呢?
中括号、连字符和反义符的作用
正则表达式中的“[]”表示一个字符集合,只要待匹配的字符符合字符集合中的某一项,即表示匹配成功。
当需要匹配某个范围内的字符时,可以在正则表达式中使用中括号“[]”和连字符“-”来表示范围。
当需要匹配某个范围外的字符时,可以在“[”的后面加上“^”,此时“^”不再表示定位符,而是反义符,表示某个范围之外。
中括号、连字符和反义符的具体示例如下。
| 示例 | 说明 |
|---|---|
| [cat] | 匹配c、a、t中的任意一个字符 |
| [^cat] | 匹配除c、a、t以外的字符 |
| [A-Z] | 匹配A~Z范围内的字符 |
| [^a-z] | 匹配a~z范围外的字符 |
| [a-zA-Z0-9] | 匹配a~z、A~Z和0~9范围内的字符 |
连字符“-”只有在表示字符范围时才作为元字符来使用,其他情况下则只表示一个文本字符。 连字符“-”表示的范围遵循字符编码的顺序,如“a-z”和“A-Z”是合法的范围,“a-Z”,“z-a”和“a-9”是不合法的范围。
使用中括号、连字符和反义符的示例代码如下。
var str = 'beautiful 女孩!';
console.log(str.match(/[abc]/g)); // 输出结果:(2) ["b", "a"]
console.log(str.match(/[^a-z]/g)); // 输出结果:(4) [" ", "女", "孩", "!"]9.2.3 反斜线
一个字符串可能会存在以下两种特殊情况。
字符串中包含一些换行符、制表符等。 字符串中包含一些元字符。
当我们需要匹配的字符刚好属于这些特殊情况时,就需要用到反斜线了。
正则表达式中,反斜线“\”有以下两个作用。
使用反斜线进行特定匹配
使用反斜线将元字符转换为文本字符
正则表达式中可以使用反斜线加一些具有特定含义的字符来进行特定匹配,这种使用反斜线进行特定匹配的形式是一些常见模式的简写,被称为预定义符。常用的预定义符如下。
| 预定义符 | 说明 |
|---|---|
| \d | 匹配所有0~9之间的任意一个数字,相当于[0-9] |
| \D | 匹配所有0~9以外的字符,相当于0-9 |
| \w | 匹配任意的字母、数字和下画线,相当于[a-zA-Z0-9_] |
| \W | 匹配除字母、数字和下画线以外的字符,相当于a-zA-Z0-9_ |
| \s | 匹配空白字符(包括换行符、制表符、空格符等),相当于[\t\r\n\v\f] |
| \S | 匹配非空白字符,相当于\t\r\n\v\f |
| \f | 匹配一个换页符(form feed) |
| 预定义符 | 说明 |
|---|---|
| \b | 匹配单词分界符。如“\bg”可以匹配“best grade”,结果为“g” |
| \B | 匹配非单词分界符。如“\Bade”可以匹配“best grade”,结果为“ade” |
| \t | 匹配一个水平制表符(horizontal tab) |
| \n | 匹配一个换行符(line feed) |
| \xhh | 匹配ISO-8859-1值为hh(16进制2位数)的字符,如“\x61”表示“a” |
| \r | 匹配一个回车符(carriage return) |
| \v | 匹配一个垂直制表符(vertical tab) |
| \uhhhh | 匹配Unicode值为 hhhh (16进制4位数)的字符,如“\u597d”表示“好” |
以“\d”和“\w”为例进行演示,示例代码如下。
var str = 'Hello World123';
var reg1 = /\d/g;
var reg2 = /\W/g;
console.log(str.match(reg1)); // 输出结果:(3) ["1", "2", "3"]
console.log(str.match(reg2)); // 输出结果:[" "]当我们需要匹配的字符刚好是元字符时,正则表达式中就需要使用反斜线将元字符转换为文本字符。
使用字面量方式创建的正则表达式,使用反斜线将元字符转换为文本字符时,需要一个反斜线。 使用构造函数创建的正则表达式,使用反斜线将元字符转换为文本字符时,需要两个反斜线。
使用反斜线将元字符“^”“?”和“.”转换为文本字符的示例代码如下。
var reg = /\^/g;
var reg1 = /\?/g;
var reg2 = new RegExp('\\.', 'g');
console.log('^a1b2'.match(reg)); // 输出结果:["^"]
console.log('a1?b2'.match(reg1)); // 输出结果:["?"]
console.log('a1.b2'.match(reg2)); // 输出结果:["."]9.2.4 点字符和限定符
在实际开发中,当需要匹配除换行符(\n)和回车符(\r)之外的任意单个字符时,可以在正则表达式中使用点字符“.”。当要匹配某个连续出现的字符时,可以使用限定符,限定符包括“?”“+”“*”和“{}”。
点字符和限定符的说明如下所示。
| 字符 | 说明 |
|---|---|
| . | 匹配除换行符和回车符之外的任意单个字符 |
| ? | 匹配前面的字符零次或一次 |
| + | 匹配前面的字符一次或多次 |
| * | 匹配前面的字符零次或多次 |
| {n} | 匹配前面的字符n次 |
| {n,} | 匹配前面的字符最少n次 |
| {n,m} | 匹配前面的字符最少n次,最多m次 |
使用点字符“.”匹配h与t之间除换行符和回车符之外任意单个字符,使用限定符匹配字符h与t之间的字符i,示例代码如下。
console.log('hit'.match(/h.t/g)); // 输出结果:["hit"]
console.log('hiit'.match(/hi?t/g)); // 输出结果:null
console.log('hiit'.match(/hi+t/g)); // 输出结果:["hiit"]
console.log('ht'.match(/hi*t/g)); // 输出结果:["ht"]
console.log('hit'.match(/hi{1}t/g)); // 输出结果:["hit"]
console.log('hiit'.match(/hi{1,}t/g)); // 输出结果:["hiit"]
console.log('hiiit'.match(/hi{1,3}t/g)); // 输出结果:["hiiit"]当点字符和限定符连用时,可以实现匹配指定数量范围的任意字符。
在实现指定数量范围的任意字符匹配时,支持以下两种匹配方式。
贪婪匹配:表示匹配尽可能多的字符。
懒惰匹配:表示匹配尽可能少的字符。
正则表达式默认是贪婪匹配,若需要懒惰匹配,在限定符的后面加上“?”符号即可。
贪婪匹配和懒惰匹配的示例代码如下。
var str = 'webWEB';
var reg1 = /w.*b/ig; // 贪婪匹配
console.log(str.match(reg1)); // 输出结果:["webWEB"]
var reg2 = /w.*?b/ig; // 懒惰匹配
console.log(str.match(reg2)); // 输出结果:["web", "WEB"]9.2.5 竖线
当我们匹配的字符串有多个条件时,可以在正则表达式中使用竖线“|”连接前后两个条件,“|”表示“或”。只要给定的字符串中包含“|”前后中的一个,就会匹配成功。
在正则表达式中使用竖线的示例代码如下。
var reg = /hi|ha/g;
console.log('shill'.match(reg)); // 输出结果:["hi"]
console.log('happy'.match(reg)); // 输出结果:["ha"]9.2.6 小括号
在正则表达式中,使用小括号“()”可以对正则表达式分组,被小括号标注的内容称为子模式(或称为子表达式),一个子模式可以看作是一个组。
正则表达式中的小括号功能非常强大,它的功能主要有以下4个。
改变作用范围 捕获内容 反向引用 零宽断言
使用小括号改变作用范围后的变化
使用小括号对内容进行分组后,小括号中的“|”将只对当前子模式有效,而不会作用于整个模式。
限定符原本用来限定其前面的字符出现的次数,而分组后,则用来限定其前面的分组匹配到的内容出现的次数。
比较改变作用范围前和改变作用范围后的结果,示例代码如下。
// 示例1
var reg1 = /happy|te/; // 可匹配的结果:happy、te
var reg2 = /ha(ppy|te)/; // 可匹配的结果:happy、hate
// 示例2
var reg1 = /abc{2}/; // 可匹配的结果:abcc
var reg2 = /a(bc){2}/; // 可匹配的结果:abcbc当子模式匹配到内容时,匹配到的内容会被临时保存,这个过程就称为捕获。利用match()进行捕获时,其返回结果中会包含子模式的匹配结果,示例代码如下。

若不想捕获子模式的匹配内容,可以在子模式前使用“?:”实现非捕获匹配,示例代码如下
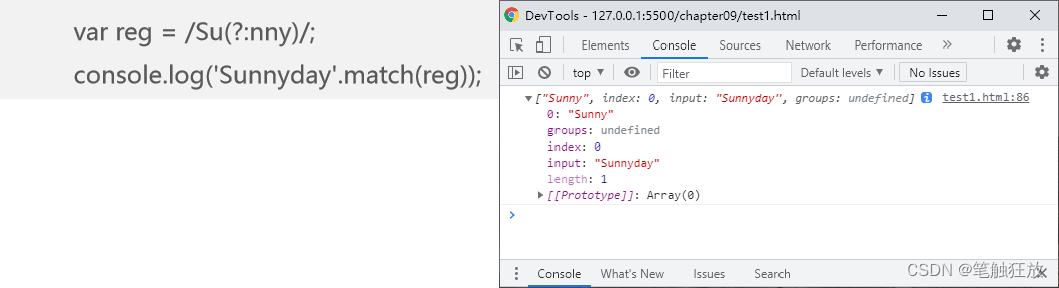
当一个正则表达式被分组后,每个组将会自动分配一个组号用于代表每个子模式,组号按从左到右的顺序编号,第1个子模式的组号为1,第2个子模式的组号为2。
有了组号以后,可以在正则表达式的后半部分引用前半部分中的子模式的捕获结果,这种引用方式称为反向引用。
反向引用的语法为“\组号”,例如,“\1”表示引用第1个子模式的捕获结果。
使用反向引用查找字符串中连续的3个相同数字,示例代码如下。
var str = '13335 12345 56668';
var reg = /(\d)\1\1/g;
var match = str.match(reg);
console.log(match); // 输出结果为:(2) ["333", "666"]零宽断言指的是一种零宽度的子模式匹配,其中,零宽度是指子模式匹配到的内容不会保存到匹配结果中,断言是指给子模式所在位置添加一个限定条件,用来规定此位置之前或者之后的内容必须满足限定条件才能使子模式匹配成功。
零宽断言分为先行断言、先行否定断言、后行断言和后行否定断言4种方式。
零宽断言的具体方式、语法和说明如下所示。
| 方式 | 语法 | 说明 |
|---|---|---|
| 先行断言 | x(?=y) | 只有当x后面是y时,才匹配成功 |
| 先行否定断言 | x(?!y) | 只有当x后面不是y时,才匹配成功 |
| 后行断言 | (?<=y)x | 只有当x前面是y时,才匹配成功 |
| 后行否定断言 | (?<!y)x | 只有当x前面不是y时,才匹配成功 |
在正则表达式中使用零宽断言的示例代码如下。
var reg1 = /Countr(?=y)/g; // 先行断言
var reg2 = /Countr(?!y)/g; // 先行否定断言
var reg3 = /(?<=A)dmin/g; // 后行断言
var reg4 = /(?<!A)dmin/g; // 后行否定断言
// 执行匹配
console.log('Country'.match(reg1)); // 输出结果:["Countr"]
console.log('Country'.match(reg2)); // 输出结果:null
console.log('Admin'.match(reg3)); // 输出结果:["dmin"]
console.log('Bdmin'.match(reg4)); // 输出结果:["dmin"]脚下留心:正则表达式优先级
正则表达式中的各种符号按照从高到低的顺序进行排列,具体如下。
用于将元字符转换为文本字符的“\”
()、[]
*、+、?、{}
^、$、用于特定匹配的“\”、.、文本字符
|
9.2.7 【案例】身份证号码验证
案例需求
本案例将实现验证用户输入的身份证号码是否合法,由于真实的身份证号规则比较复杂,这里我们采用一种简单的验证规则,要求合法的身份证号码为18位,前6位表示地区码,以非0数字开头;后面8位表示出生日期(年、月、日),要求年份在1800—3999年;最后4位由3位顺序码和1位校验码组成,1位校验码可以是0~9之间的任意一个数字或者是X,为了输入方便,允许将X输入成x。
身份证号码各部分验证规则:
地区:[1-9]\d{5}。
出生年份:(18|19|[23]\d)\d{2}。
出生月份:(0[1-9]|1[0-2])。
出生日期:(0-2|10|20|30|31)。
顺序码和校验码:\d{3}[0-9Xx]。
案例的实现思路:
声明变量,接收用户输入的身份证号码。
根据各部分规则,创建正则表达式。
根据正则表达式判断用户输入的身份证号码是否合法。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<script>
var str = prompt('请输入要验证的身份证号:')
var reg = /^[1-9]\d{5}(18|19|[23]\d)\d{2}(0[1-9]|1[0-2])([0-2][1-9]|10|20|30|31)\d{3}[0-9Xx]$/;
if (reg.test(str)) {
console.log('您输入的身份证号码合法');
} else {
console.log('您输入的身份证号码不合法');
}
</script>
</body>
</html>9.3 正则表达式中的模式修饰符
在实际开发中,合理使用模式修饰符,可以使正则表达式变得更加简洁、直观。常用的模式修饰符如下。
| 模式修饰符 | 说明 |
|---|---|
| g | 全局匹配 |
| i | 忽略大小写 |
| m | 多行匹配 |
| s | 允许点字符“.”匹配换行符和回车符 |
| u | 使用Unicode码的模式进行匹配 |
| y | 执行“粘性”(sticky)搜索,匹配从目标字符串的当前位置开始 |
模式修饰符可以组合使用,没有顺序要求。
在正则表达式中使用模式修饰符g、i、m、 s的示例代码如下。
console.log('abbbc'.match(/b/g)); // 输出结果:(3) ["b", "b", "b"]
console.log('Apple'.match(/apple/gi)); // 输出结果:["Apple"]
console.log('Hi Li\n Ming'.match(/Li$/gm)); // 输出结果:["Li"]
console.log('fat\ndog'.match(/^f.*$/s)); // 输出结果:["fat↵dog"]9.4 正则表达式常用方法
通过前面的学习,大家已经掌握了正则表达式对象的test()方法和match()方法的使用,而在String对象的方法中,也有一些方法可以使用正则表达式,如search()方法、split()方法和replace()方法,接下来将详细讲解这3个方法的使用。
9.4.1 search()方法
search()方法可以获取子字符串在给定的字符串中首次出现的索引,匹配成功返回其首次出现的索引,匹配失败返回-1。
search()方法的参数是一个正则表达式对象,如果传入一个非正则表达式对象,则会使用RegExp()隐式地将其转换为正则表达式对象。
使用search()方法查找出字符a和字符c中间只有一个字符的子字符串在目标字符串'abcadc'中首次出现的索引,示例代码如下。
var str = 'abcamc';
console.log(str.search('a.c')); // 输出结果:0
console.log(str.search(/a.c/)); // 输出结果:09.4.2 split()方法
split()方法用于根据指定的分割符将一个字符串分割成字符串数组,其分割后的字符串数组中不包括分割符本身。
当分割符不只一个时,需要定义正则表达式对象来完成字符串的分割操作。
在实现分割操作时还可以指定分割的次数。
使用正则表达式匹配的方式通过“@”和“.”两种分隔符对字符串进行分割,示例代码如下。
var str = 'test@qq.com';
var reg = /[@\.]/;
var split_res = str.split(reg);
console.log(split_res); // 输出结果:(3) ["test", "qq", "com"]当指定字符串分割次数后,若指定的次数小于实际字符串中符合规则分割的次数,则最后的返回结果中会忽略其他的分割结果,示例代码如下。
var str = 'We are a family';
var reg = /\s/;
var split_res = str.split(reg, 2);
console.log(split_res); // 输出结果:(2) ["We", "are"]9.4.3 replace()方法
在实际开发中,要将一篇文章中多次出现的错别字进行修改,如果一边查找一边修改是非常麻烦的,而且很可能漏查,如何才能高效的将错别字修改呢?
replace()方法用于替换字符串,用来操作的参数可以是一个字符串或正则表达式,返回值是替换后的新字符串,并不会修改原字符串的内容。
替换'Hello Word'中的Word为World的示例代码如下。
var str = 'Hello Word';
var reg = /(\w+)\s(\w+)/gi;
var newStr = str.replace(reg, '$1 World');
console.log(newStr); // 输出结果:Hello World9.4.4 【案例】过滤并替换敏感词
日常生活中,我们在网站上输入一些信息时,某些内容可能被替换成星号“”,或者当我们浏览一些论坛时,经常看到别人发表的内容中包含一些星号“”,这些被星号代替的内容一般是敏感词或者个人信息。本案例将实现过滤敏感词 admin 和 manager,忽略大小写并将匹配到的敏感词替换成“*”。
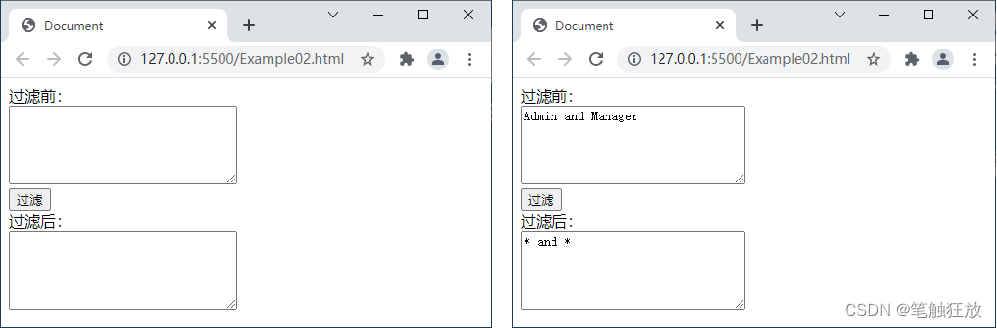
案例的实现思路:
定义两个文本域和一个按钮。
为按钮绑定单击事件。
创建正则表达式,并根据正则表达式替换用户输入的内容。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<div>过滤前的内容:<br>
<textarea id="before" cols="30" rows="5"></textarea>
</div>
<button id="btn">过滤</button>
<div>过滤后的内容:<br>
<textarea id="after" cols="30" rows="5"></textarea>
</div>
<script>
document.getElementById('btn').onclick = function () {
var str = document.getElementById('before').value;
var reg = /(admin)|(manager)/gi;
var newStr = str.replace(reg, '*');
document.getElementById('after').value = newStr;
};
</script>
</body>
</html>动手实践:表单验证
开发表单页面时,为了保证表单的严谨性,需要对表单进行验证。例如,用户注册、用户登录、填写个人信息的时候,都需要对用户填写的内容进行验证。下面以用户注册为例讲解表单验证。本案例对用户注册时填写的用户名、密码和手机号的格式要求如下。
用户名由英文大小写字母组成,长度为3~10位。 密码由英文大小写字母、数字和下画线组成,长度为6~20位。 手机号是以13、15、16、17、18、19开头的11位数字。
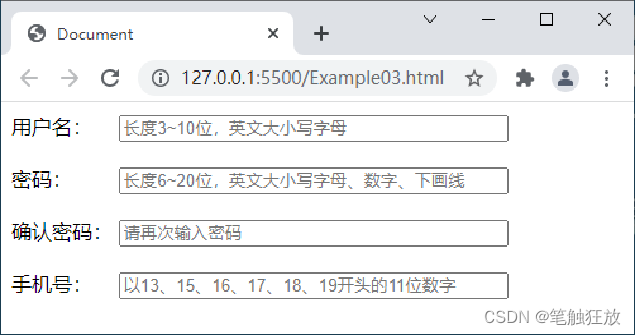
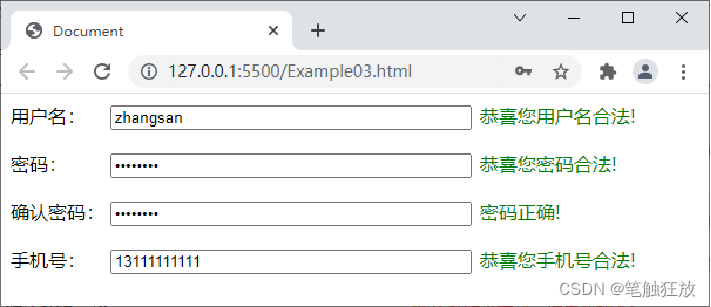
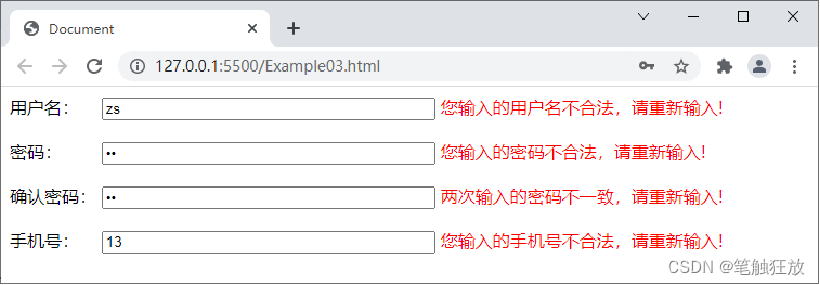
案例的实现思路:
编写HTML代码,实现页面结构。
编写CSS代码,为页面结构添加样式。
定义函数,实现验证用户名、密码、手机号是否合法。
定义函数,实现验证两次输入的密码是否一致。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
label { width: 80px; display: inline-block; margin-bottom: 20px; }
input { width: 300px; padding: 5px; }
.green { color: green; }
.red { color: red; }
</style>
</head>
<body>
<form>
<label>用户名:</label>
<input type="text" name="username" placeholder="长度3~10位,英文大小写字母"> <span></span><br>
<label>密码:</label>
<input type="password" name="psw" placeholder="长度6~20位,英文大小写字母、数字、下画线"> <span></span><br>
<label>确认密码:</label>
<input type="password" name="conf" placeholder="请再次输入密码"> <span></span><br>
<label>手机号:</label>
<input type="text" name="tell" placeholder="以13、15、16、17、18、19开头的11位数字"> <span></span><br>
</form>
<script>
// 验证用户名、密码、手机号是否合法
function checkItem(obj, name, reg) {
var osp = obj.nextElementSibling;
obj.onblur = function () {
if (reg.test(obj.value)) {
osp.innerHTML = '恭喜您' + name + '合法!';
osp.className = 'green';
} else {
osp.innerHTML = '您输入的' + name + '不合法,请根据提示重新输入!';
osp.className = 'red';
}
};
}
// 验证输入的两次密码是否一致
function checkPwd(obj, previous) {
obj.onblur = function () {
if (obj.value == previous.value) {
obj.nextElementSibling.innerHTML = '密码正确!';
obj.nextElementSibling.className = 'green';
} else {
obj.nextElementSibling.innerHTML = '两次密码不一致,请重新输入!';
obj.nextElementSibling.className = 'red';
}
}
}
// 获取所有input元素
var oinp = document.getElementsByTagName('input');
// 调用checkItem()函数
checkItem(oinp[0], '用户名', /^[a-zA-Z]{3,10}$/);
checkItem(oinp[1], '密码', /^\w{6,20}$/);
checkItem(oinp[3], '手机号', /^1[356789]\d{9}$/);
//调用checkPwd()函数
checkPwd(oinp[2], oinp[1]);
</script>
</body>
</html>
本章小结
本章首先讲解了什么是正则表达式、正则表达式的语法格式、正则表达式的使用,然后讲解了正则表达式中的元字符、模式修饰符的使用,最后讲解了正则表达式常用方法。通过本章的学习,希望读者能够掌握正则表达式的基本用法,能够使用正则表达式对字符串进行匹配、分割、替换等操作。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











