







 本文深入探讨Celery任务队列的原理与应用,包括其分布式处理能力、与Flask结合使用的方法,以及核心模块和角色介绍。分析Celery如何处理大量消息,支持实时和定时任务调度,特别适合异步处理和后台作业。
本文深入探讨Celery任务队列的原理与应用,包括其分布式处理能力、与Flask结合使用的方法,以及核心模块和角色介绍。分析Celery如何处理大量消息,支持实时和定时任务调度,特别适合异步处理和后台作业。
文章目录
1 celery 简要概述
Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具。
它是一个任务队列,专注于实时处理,同时还支持任务调度。
celery 的优点
-
简单:celery的 配置和使用还是比较简单的, 非常容易使用和维护和不需要配置文件
-
高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
如果连接丢失或发生故障,worker和client 将自动重试,并且一些代理通过主/主或主/副本复制方式支持HA。
-
快速:一个单进程的celery每分钟可处理上百万个任务
-
灵活: 几乎celery的各个组件都可以被扩展及自定制
1.1 celery 可以做什么?
典型的应用场景, 比如
- 异步发邮件 , 一般发邮件比较耗时的操作,需要及时返回给前端,这个时候 只需要提交任务给celery 就可以了.之后 由worker 进行发邮件的操作 .
- 比如有些 跑批接口的任务,需要耗时比较长,这个时候 也可以做成异步任务 .
- 定时调度任务等
2 celery 的核心模块
2-1 celery 的5个角色
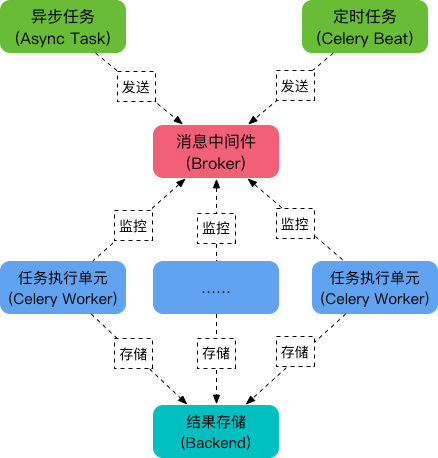
Task
就是任务,有异步任务和定时任务
Broker
中间人,接收生产者发来的消息即Task,将任务存入队列。任务的消费者是Worker。
Celery本身不提供队列服务,推荐用Redis或RabbitMQ实现队列服务。
Worker
执行任务的单元,它实时监控消息队列,如果有任务就获取任务并执行它。
Beat
定时任务调度器,根据配置定时将任务发送给Broker。
Backend
用于存储任务的执行结果。
注 图片来自 https://foofish.net/images/584bbf78e1783.png

3 celery 和flask 如何结合起来
3.1项目结构
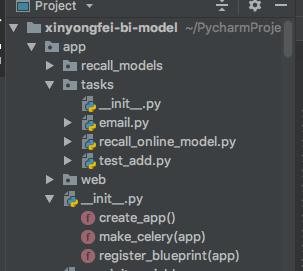
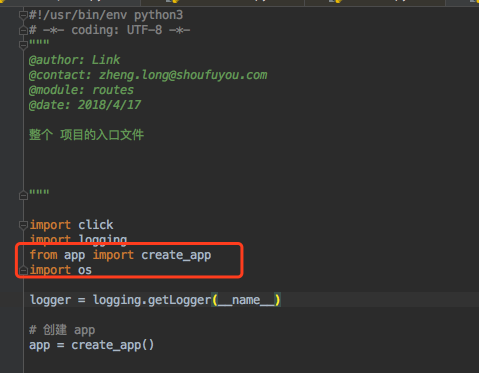
3.2 项目入口 文件 routes.py
3.3 celery 实例创建,如何和flask绑定在一起呢
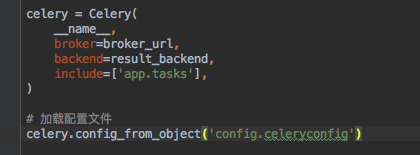
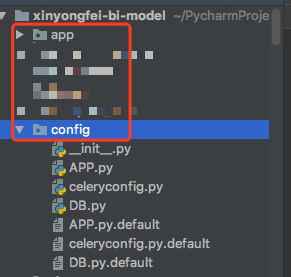
说明 这里 app.tasks 是在 app包下面创建的tasks 包
结构如下
flask 实例的创建 如下图:
def create_app():
app = Flask(__name__)
# 加载app配置文件
app.config.from_object('config.DB')
# 注册蓝图
register_blueprint(app)
from app.recall_models.models.dbbase import db
# db 初始化
db.init_app(app)
with app.app_context():
# 创建表
db.create_all()
return app
3.3 task 如何定义
可以从 celery.Task 继承,如果要想实现回调, task执行成功后, 要发起一个回调的话, 最好要继承 Task 实现 on_success , on_failure 这两个方法
from celery import Task
class MyTask(Task):
def on_success(self, retval, task_id, args, kwargs):
"""
任务 成功到时候 ,发起一个回调
# 更新状态, 更新完成时间
:param retval:
:param task_id:
:param args:
:param kwargs:
:return:
"""
logger.info(f"on_success recall task[{task_id}] success.")
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""
任务失败的时候,发起一个回调
:param exc:
:param task_id:
:param args:
:param kwargs:
:param einfo:
:return:
"""
logger.info(f"on_failure recall task[{task_id}] failure. exc:{exc} ")
回溯任务 可以直接定义一个函数 ,这里的任务可以是一些比较耗时的操作, 可能需要跑批数据等等这种情况.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@Time : 2019/5/17 16:47
@File : recall_online_model.py
@Author : frank.chang@shoufuyou.com
"""
from datetime import datetime
import logging
from celery import Task
from celery.exceptions import CeleryError
from app.recall_models.base import ModelAppearance
from app.recall_models.models.dbbase import RecallRecord
from app.app_init_variables import db_config, db_name
from app import celery
from app.recall_models.base import ReCallReader
from app.recall_models.models.dbbase import db
from config.APP import MODEL_SUFFIX
from util.transfer import str_fmt
logger = logging.getLogger(__name__)
@celery.task(bind=True, base=MyTask)
def recall_model(self, model_name, sql, input_java_factors, input_python_factors, score, prob):
logger.info(f"self.request.id:{self.request.id}")
task_id = self.request.id
recall = ModelAppearance(
model_name=model_name,
sql=sql,
score=score,
prob=prob,
python_factors=input_python_factors,
java_factors=input_java_factors,
task_id=task_id
)
# 模拟耗时操作
# time.sleep(5)
try:
# 这里是一些耗时任务
return recall()
except CeleryError as e:
logger.error(e)
self.retry(exc=e, countdown=1 * 60, max_retries=3)
raise e
except Exception as e:
logger.error(e)
raise e
3.3.1 绑定任务
有的时候 可能需要绑定 任务,拿到任务的相关的信息.
一个任务绑定 意味着第一个参数 是任务本身的实例 ,这类似与python 中 绑定的方法. self 就是实例本身一样
参考 官方文档 http://docs.celeryproject.org/en/latest/userguide/tasks.html
@celery.task(bind=True, base=MyTask)
def recall_model(self, model_name, sql, score, prob):
# 比如需要拿到 任务请求的id
task_id = self.request.id
pass
不绑定任务 就是这样 的
@celery.task(base=MyTask)
def recall_model( model_name, sql, score, prob):
# 任务处理逻辑
pass
3.4 worker 启动入口
启动 Worker,监听 Broker 中是否有任务
如何启动 worker 可以通过 命令:
celery worker -A celery_worker.celery --concurrency=2 -l INFO
线上配置 可以 使用 celeryd 配置文件
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@Time : 2019/5/14 17:10
@File : celery_worker.py
@Author : frank.chang@shoufuyou.com
项目的根目录下,有个 celery_worker.py 的文件,
这个文件的作用类似于 wsgi.py,是启动 Celery worker 的入口。
# 启动worker
celery worker -A celery_worker.celery -l INFO
# test
celery worker -A celery_worker.celery --concurrency=2 -l INFO
celery 启动参数
-A 启动app 的位置
-l 日志级别Der
"""
import logging
from app import create_app, celery
logger = logging.getLogger(__name__)
app = create_app()
app.app_context().push()
3.5 消费者如何工作
3.5.1 消费者如何消费数据呢?
worker 如何工作呢?
3.6 如何通过task_id 去获取任务状态呢
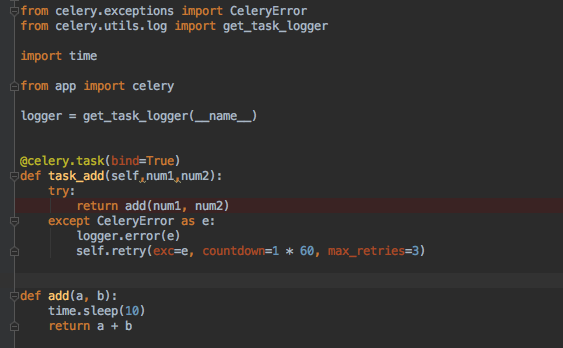
from app import celery
@celery.task(bind=True, base=MyTask)
def recall_model(self, model_name, sql, input_java_factors, input_python_factors, score, prob):
logger.info(f"self.request.id:{self.request.id}")
task_id = self.request.id
recall = ModelAppearance(
model_name=model_name,
sql=sql,
score=score,
prob=prob,
python_factors=input_python_factors,
java_factors=input_java_factors,
task_id=task_id
)
# 模拟耗时操作
# time.sleep(5)
try:
return recall()
except CeleryError as e:
logger.error(e)
self.retry(exc=e, countdown=1 * 60, max_retries=3)
raise e
except Exception as e:
logger.error(e)
raise e
注意这里 recall_model 是一个celery.task 修饰的函数名称. 通过 下面的方式就可以拿到 result
result = recall_model.AsyncResult(task_id)
status = result.status
result._get_task_meta() # 这样就可以拿到task 的状态信息
4 源码解析
4.1 celery 的工作流
在 celery.app.amqp.py 模块里面 这个 AMQP 类起了关键的作用
创建消息,发送消息,消费消息
这里 生产者 ,消费者 是由 kombu 框架来实现的.
from kombu import Connection, Consumer, Exchange, Producer, Queue, pools
class AMQP(object):
"""App AMQP API: app.amqp."""
Connection = Connection
Consumer = Consumer
Producer = Producer
#: compat alias to Connection
BrokerConnection = Connection
queues_cls = Queues
#: Cached and prepared routing table.
_rtable = None
#: Underlying producer pool instance automatically
#: set by the :attr:`producer_pool`.
_producer_pool = None
# Exchange class/function used when defining automatic queues.
# For example, you can use ``autoexchange = lambda n: None`` to use the
# AMQP default exchange: a shortcut to bypass routing
# and instead send directly to the queue named in the routing key.
autoexchange = None
#: Max size of positional argument representation used for
#: logging purposes.
argsrepr_maxsize = 1024
#: Max size of keyword argument representation used for logging purposes.
kwargsrepr_maxsize = 1024
def __init__(self, app):
self.app = app
self.task_protocols = {
1: self.as_task_v1,
2: self.as_task_v2,
}
整个接口调度逻辑
从视图函数进来 的时候
定义的任务
视图函数 task_add
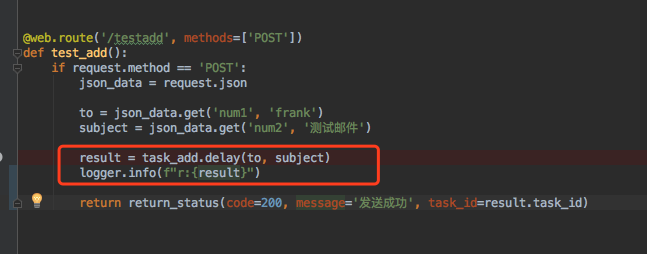
Task.delay() --> apply_async --> send_task --> amqp.create_task_message --> amqp.send_task_message --> result=AsyncResult(task_id) 返回 result
delay 之后 调用实际上是 apply_async 之后 调用的send_task 之后开始创建任务,发送任务, 然后生成一个异步对象. 把这个结果返回.
4.2 celery 的入口
celery 启动的worker 的入口 , __ main__.py 里面 .
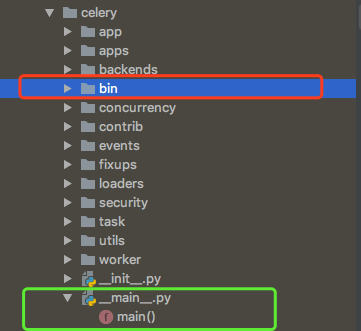
这里 实际上是 celery.bin.celery 中的main 函数
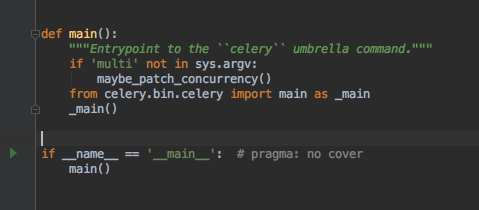
打开文件 就会发现这个 main 函数
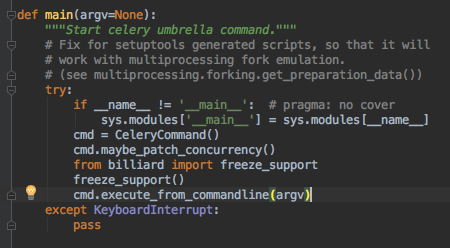
调用command.execute_from_commandline(argv)
def execute_from_commandline(self, argv=None):
argv = sys.argv if argv is None else argv
if 'multi' in argv[1:3]: # Issue 1008
self.respects_app_option = False
try:
sys.exit(determine_exit_status(
super(CeleryCommand, self).execute_from_commandline(argv)))
except KeyboardInterrupt:
sys.exit(EX_FAILURE)
调用 的是 celery.bin.base.Command 类的方法
self.setup_app_from_commandline 核心调用的是这个 方法
celery.bin.celery.CeleryCommand
def execute_from_commandline(self, argv=None):
"""Execute application from command-line.
Arguments:
argv (List[str]): The list of command-line arguments.
Defaults to ``sys.argv``.
"""
if argv is None:
argv = list(sys.argv)
# Should we load any special concurrency environment?
self.maybe_patch_concurrency(argv)
self.on_concurrency_setup()
# Dump version and exit if '--version' arg set.
self.early_version(argv)
try:
argv = self.setup_app_from_commandline(argv)
except ModuleNotFoundError as e:
self.on_error(UNABLE_TO_LOAD_APP_MODULE_NOT_FOUND.format(e.name))
return EX_FAILURE
except AttributeError as e:
msg = e.args[0].capitalize()
self.on_error(UNABLE_TO_LOAD_APP_APP_MISSING.format(msg))
return EX_FAILURE
self.prog_name = os.path.basename(argv[0])
return self.handle_argv(self.prog_name, argv[1:])
def setup_app_from_commandline(self, argv):
preload_options = self.parse_preload_options(argv)
quiet = preload_options.get('quiet')
if quiet is not None:
self.quiet = quiet
try:
self.no_color = preload_options['no_color']
except KeyError:
pass
workdir = preload_options.get('workdir')
if workdir:
os.chdir(workdir)
app = (preload_options.get('app') or
os.environ.get('CELERY_APP') or
self.app)
preload_loader = preload_options.get('loader')
if preload_loader:
# Default app takes loader from this env (Issue #1066).
os.environ['CELERY_LOADER'] = preload_loader
loader = (preload_loader,
os.environ.get('CELERY_LOADER') or
'default')
broker = preload_options.get('broker', None)
if broker:
os.environ['CELERY_BROKER_URL'] = broker
result_backend = preload_options.get('result_backend', None)
if result_backend:
os.environ['CELERY_RESULT_BACKEND'] = result_backend
config = preload_options.get('config')
if config:
os.environ['CELERY_CONFIG_MODULE'] = config
if self.respects_app_option:
if app:
self.app = self.find_app(app)
elif self.app is None:
self.app = self.get_app(loader=loader)
if self.enable_config_from_cmdline:
argv = self.process_cmdline_config(argv)
else:
self.app = Celery(fixups=[])
self._handle_user_preload_options(argv)
return argv
5 总结
本文简单介绍了 celery 的基本的功能 , 以及celery 能够处理的任务特点,以及可以和 flask 结合起来使用. 简单分析了 celery 的工作机制 . 当然 如果想要深入了解 celery,可以 参考 celery的官方文档.
6 参考链接
1 celery 文档 http://docs.celeryproject.org/en/latest/getting-started/first-steps-with-celery.html
2 project layout http://docs.celeryproject.org/en/latest/getting-started/next-steps.html#project-layout
2-1 celery 的 配置介绍 http://docs.celeryproject.org/en/latest/userguide/configuration.html#configuration
3 可以设置任务的类型 http://docs.jinkan.org/docs/celery/_modules/celery/app/task.html#Task.apply_async
4 kombu Messaging library for Python https://kombu.readthedocs.io/en/stable/
4-1 kombu github 地址 https://github.com/celery/kombu
4-2 komub producer https://kombu.readthedocs.io/en/stable/userguide/producers.html
5 Celery 最佳实践(转) https://rookiefly.cn/detail/229
6 celery community http://www.celeryproject.org/community/
7 celery 通过 task_id 拿到任务的状态 http://docs.celeryproject.org/en/master/faq.html#how-do-i-get-the-result-of-a-task-if-i-have-the-id-that-points-there
8 python celery 任务队列 https://www.pyfdtic.com/2018/03/16/python-celery-%E4%BB%BB%E5%8A%A1%E9%98%9F%E5%88%97/
9 worker 相关 http://docs.celeryproject.org/en/latest/userguide/workers.html
10 Celery 简介 http://docs.jinkan.org/docs/celery/getting-started/introduction.html

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}