







第一次写博文,希望以后能一直坚持下去。
本文主要分享hadoop中如何实现多文件输出。
实际hadoop job开发中,我们的输出数据可能不止一类,并且需要将不同的数据类以不同的文件名输出保存。例如典型的wordcount实现,如果既要统计单词在所有文档中的出现次数,又要统计单词在所有文档中的出现行数,将这两个次数输出到count.txt文件和line.txt文件中。类似这样的需求很多很多,而hadoop确实也提供了对此类需求的支持。
我使用的hadoop版本是0.19.1,其他版本的实现方式可能有所差异。
实现多文件输出的步骤如下:
1.实现MutipleTextOutputFormat的子类并重写generateFileNameForKeyValue方法。
该方法名很直白地告诉我们,是根据key和value来命名输出的文件,其中 name参数就是原始输出的那些文件名:part-00000\part-00001..... 最简单地,下面的实现中,我们加上key作为文件名前缀:
public class MyMultipleOutputFormat
extendsMultipleTextOutputFormat<Text, Text> {
protected String generateFileNameForKeyValue(Text key, Text value, String name) {
return key.toString()+"_"+name;
}
}
很明显,如果key是"hadoop",则最后输出的文件名为 hadoop_part-00000,hadoop_part-00001..... (注意:若不加name,则由于每个reduce输出文件名相同,会导致覆盖,只保留最后一个reduce输出的文件。)
2.在JobConf中设置输出格式。
conf.setOutputFormat(MyMultipleOutputFormat.class);
3.在reduce中指定key。
output.collect(new Text("data"), new Text("data"));//输出到以"data"为前缀的文件中。
output.collect(new Text("ks"), new Text("ks"));//输出到以"ks"为前缀的文件中。
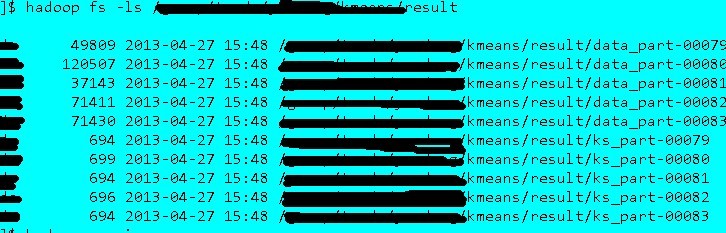
结果如下图所示:















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









