







1.爬虫指的是: 一段自动抓取互联网信息的程序,其价值是互联网数据为我所用
爬虫调度端
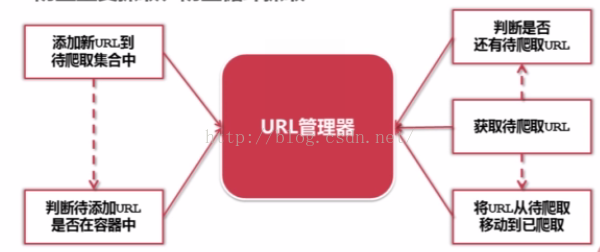
URL管理器:管理待抓取URL集合和已抓取URL集合,原因是防止重复抓取、防止循环抓取
网页下载器:将互联网上URL对应的网页下载到本地的工具
urllib2 :Python官方基础模块
requests:第三方强大的插件
urllib2下载网页
方法1:最简洁的方法 urllib2.urlopen(url)
import urllib2
#直接请求
response=urllib2.urlopen('http://www.baidu.com');
#获取状态码,如果200表示获取成功
print respose.getcode();
#读取内容
code=response.read();
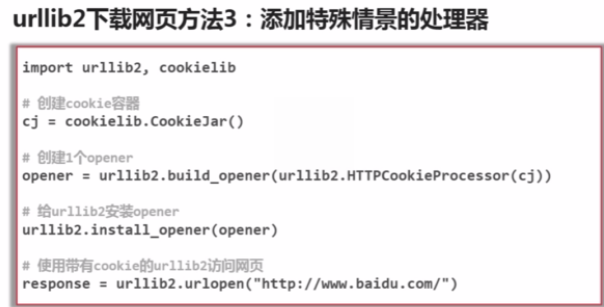
方法二:添加data,http header
import urllib2
#创建
Request=urllib2.Request(url);
#添加数据
request.add_data('a','1');
#添加http的header
request.add_header('User-Agent','Mozilla/5.0')
#发送请求获取结果
response=urlli2.urlopen(request);
http://www.imooc.com/video/10683
网页解析器
1.正则表达式:模糊化匹配
2.html.parser:结构化解析
3.Beautiful Soup:结构化解析
4.lxml:结构化解析
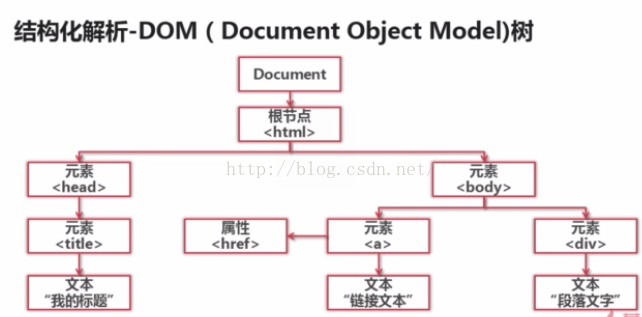
这次使用Beautiful Soup
-Python第三方库,用于从HTML或XML中提取数据
-官网:http://www.crummy.com/software/BeautifulSoup/
2.爬取得到百度百科Python词条相关的1000个页面数据














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









