







题目
尽管合并排序的最坏情况运行时间为
 , 插入排序的最坏情况运行时间为
, 插入排序的最坏情况运行时间为
 ,但插入 排序中的常数因子使得它在n较小时,运行得要更快一些。因此,在合并排序算法中,当 子问题足够小时,采用插入排序就比较合适了。考虑对合并排序做这样的修改,即采用插 入排序策略,对n/k个长度为k的子序列表进行排序,然后,再用标准的合并机制将它们合 并起来,此处k是一个待定的值。
,但插入 排序中的常数因子使得它在n较小时,运行得要更快一些。因此,在合并排序算法中,当 子问题足够小时,采用插入排序就比较合适了。考虑对合并排序做这样的修改,即采用插 入排序策略,对n/k个长度为k的子序列表进行排序,然后,再用标准的合并机制将它们合 并起来,此处k是一个待定的值。
a)证明在最坏情况下,n/k个子列表(每一个子列表的长度为k)可以用插入排序在 时间内完 成排序。
时间内完 成排序。
b)证明这些子列表可以在 最坏情况时间内完成合并。
最坏情况时间内完成合并。
c)如果已知修改后的合并排序算法的最坏情况运行时间为 ,要使修改后的算法具有与标准合并排序算法一样的渐近运行时间,k的最大渐 近值(即
,要使修改后的算法具有与标准合并排序算法一样的渐近运行时间,k的最大渐 近值(即
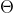 形式) 是什么(以n的函数形式表示)?
形式) 是什么(以n的函数形式表示)?
d)在实践中,k的值应该如何选取?
a)证明在最坏情况下,n/k个子列表(每一个子列表的长度为k)可以用插入排序在
b)证明这些子列表可以在
c)如果已知修改后的合并排序算法的最坏情况运行时间为
d)在实践中,k的值应该如何选取?
分析
问题a
证明:因为插入排序的最坏情况运行时间为
所以对于规模为k的输入,最坏情况运行时间为
又因为有n/k个这样的序列,也就是对n/k个这样的序列调用合并排序过 程,最坏情况运行时间就是 , 即
, 即

所以对于规模为k的输入,最坏情况运行时间为
又因为有n/k个这样的序列,也就是对n/k个这样的序列调用合并排序过 程,最坏情况运行时间就是
问题b
| 证明: | 既是证明使用插入排序的合并排序的合并步骤的运行时间 画出递归树可以看到这颗树的深度为 每一层的规模都是n,所以对每一层调用MERGE过程的最坏情况运行时间都是 所以,对于 |
问题c
因为nk + nlg(n/k)=nk + nlgn - nlgk,又因为k小于等于n,所以nlgk一定小于nlgn,所以nlgk 比nlgn的阶数小,所以
 =
=
 。
。
如果k大于lgn,则nk>nlgn,那么nk+nlgn的阶数就高于nlgn,所以k的最大渐近值为
如果k大于lgn,则nk>nlgn,那么nk+nlgn的阶数就高于nlgn,所以k的最大渐近值为
问题d
如问题c的分析,实践中需要使用插入排序的合并排序快于合并排序,k应取
伪代码
- INSERTION-MERGE-SORT(a, p, r, k)
- if p < r
- then q <- (r - q)/2
- if q - p <= k
- then INSERTION-SORT(a, p, q)
- INSERTION-SORT(a, q+1, r)
- else INSERTION-MERGE-SORT(a, p, q, k)
- INSERTION-MERGE-SORT(a, q+1, r, k)
- MERGE(a, p, q, r)
Python代码实现
def insertion_merge_sort(a, p, r, k):
if p < r:
q = (r - p) / 2
if q - p <= k:
insertion_sort(a, p, q)
insertion_sort(a, q+1, r)
else:
insertion_merge_sort(a, p, q, k)
insertion_merge_sort(a, q+1, r, k)
merge(a, p, q, r)















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









