







一、前言
dom4j是一套非常优秀的java开源api,主要用于读写xml文档,具有性能优异、功能强大、和非常方便使用的特点。 另外xml经常用于数据交换的载体,像调用webservice传递的参数,以及数据做同步操作等等, 所以使用dom4j解析xml是非常有必要的。
与利用DOM、SAX、JAXP机制来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来作为解析xml的利器。
二、准备条件
dom4j.jar
下载地址:http://sourceforge.net/projects/dom4j/files/dom4j-2.0.0-ALPHA-2/
三、使用Dom4j实战
先来看看dom4j中对应XML的DOM树建立的继承关系

针对于XML标准定义,对应于图2-1列出的内容,dom4j提供了以下实现:

同时,dom4j的NodeType枚举实现了XML规范中定义的node类型。如此可以在遍历xml文档的时候通过常量来判断节点类型了。
常用API
class org.dom4j.io.SAXReader
read
interface org.dom4j.Document
iterator
getRootElement
interface org.dom4j.Node
getName
getNodeType
getNodeTypeName
interface org.dom4j.Element
attributes
attributeValue
elementIterator
elements
interface org.dom4j.Attribute
getName
getValue
interface org.dom4j.Text
getText
interface org.dom4j.CDATA
getText
interface org.dom4j.Comment
getText
1、解析xml文档
实现思路:
<1>根据读取的xml路径,传递给SAXReader之后 返回一个Document文档对象;
<2>然后操作这个Document对象,获取下面的节点以及子节点的信息;
具体代码如下:
- 将src下面的xml转换为输入流
- //一、根据saxReader的read重写方法可知,既可以通过inputStream输入流来读取,也可以通过file对象来读取
- SAXReader saxReader = new SAXReader();
- Document document = saxReader.read(new File("D:/project/dynamicWeb/src/resource/module01.xml"));//必须指定文件的绝对路径
- // InputStream inputStream = new FileInputStream(new File("D:/project/dynamicWeb/src/resource/module01.xml"));
- //Document document = saxReader.read(inputStream);
- //将src下面的xml转换为输入流
- //InputStream inputStream = this.getClass().getResourceAsStream("/module01.xml");
- //Document document = saxReader.read(inputStream);
-
-
- // 二 、另外还可以使用DocumentHelper提供的xml转换器也是可以的。
- //String str="<?xml version=\"1.0\" encoding=\"UTF-8\"?><modules id=\"123\"><module> 这 个是module标签的文本信息</module></modules>";//这是xml文档用字符串表示
- //Document document = DocumentHelper.parseText(str);
上面只是简单的获取了xml的根目录的元素,接下来使用Iterator 迭代器循环document文档对象。
具体代码如下:
- public void parseXml02(){
- try{
- //将src下面的xml转换为输入流
- InputStream inputStream = this.getClass().getResourceAsStream("/module02.xml");
- //创建SAXReader读取器,专门用于读取xml
- SAXReader saxReader = new SAXReader();
- //根据saxReader的read重写方法可知,既可以通过inputStream输入流来读取,也可以通过file对象来读取
- Document document = saxReader.read(inputStream);
- Element rootElement = document.getRootElement(); //rootElement.getName()值为根 modules标签
- Iterator<Element> modulesIterator = rootElement.elements("module").iterator();
- //DOM4j(Document Object Model For Java)将整个xml文档看做一个对象,每一个标签也是一个对象。通过标签对象就像java对象一样操作函数,对标签操作。
- //rootElement.element("name");获取rootElement下某一个标签为<name>的子元素
- //rootElement.elements("module");获取当前标签下子元素标签为<name> </name>节点的集合,返回List集合类型(孙子节点的不算)
- //注rootElement.elements("name");是获取不到的。只是在rootElement子元素中找,找到后放入list集合中,而不会再孙子中找
- //rootElement.elements("module").iterator();返回rootElement标签下所有便签为<module>对象的List<Iterator>,再通过各个对象迭代器取出 对象中子标签。
-
- while(modulesIterator.hasNext()){
- Element moduleElement = modulesIterator.next();
- Element nameElement = moduleElement.element("name");
- System.out.println(nameElement.getName() + ":" + nameElement.getText());
- Element valueElement = moduleElement.element("value");
- System.out.println(valueElement.getName() + ":" + valueElement.getText());
- Element descriptElement = moduleElement.element("descript");
- System.out.println(descriptElement.getName() + ":" + descriptElement.getText());
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- <?xml version="1.0" encoding="UTF-8"?>
- <modules id="123">
- <module> //使用迭代对有规律数据
- <name>oa</name>
- <value>系统基本配置</value>
- <descript>对系统的基本配置根目录</descript>
- </module>
-
- </modules>
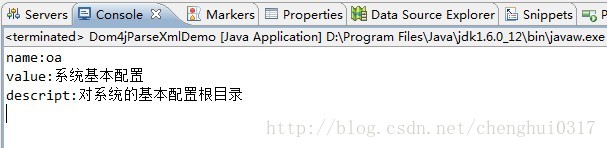
由此以知:
<1>dom4j迭代xml子元素非常的效率和便捷;
但是上面只是简单的迭代了xml的子节点元素,但是如果xml规则比较复杂,比如接下来要测试的module03.xml,具体如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <modules id="123">
- <module>这个是module标签的文本信息</module> <!--1-->
- <module id=" "> <!--2-->
- <name>oa</name>
- <value>系统基本配置</value>
- <descript>对系统的基本配置根目录</descript>
- <module>这个是子module标签的文本信息</module>
- </module>
- <module> <!--3-->
- <name>管理配置</name>
- <value>none</value>
- <descript>管理配置的说明</descript>
- <module id="106">
- <name>系统管理</name>
- <value>0</value>
- <descript>Config</descript>
- <module id="107">
- <name>部门编号</name>
- <value>20394</value>
- <descript>编号</descript>
- </module>
- </module>
- </module>
- </modules>
java.lang.NullPointerException
所以这个时候需要小心使用了,每次都不能把元素直接放进去迭代。具体实现代码如下:
- public void parseXml03(){
- try{
- //将src下面的xml转换为输入流
- InputStream inputStream = this.getClass().getResourceAsStream("/module03.xml");
- //创建SAXReader读取器,专门用于读取xml
- SAXReader saxReader = new SAXReader();
- //根据saxReader的read重写方法可知,既可以通过inputStream输入流来读取,也可以通过file对象来读取
- Document document = saxReader.read(inputStream);
- Element rootElement = document.getRootElement();
- if(rootElement.elements("module") != null ){
- //因为第一个module标签只有内容没有子节点,直接.iterator()就java.lang.NullPointerException了, 所以需要分开实现
- List<Element> elementList = rootElement.elements("module"); //返回rootElement中儿子标签为<module>的个数,只有3个,无孙子中
- for (Element element : elementList) {
- if(!element.getTextTrim().equals("")){
- System.out.println("【1】" + element.getTextTrim());
- }else{
- Element nameElement = element.element("name");
- System.out.println(" 【2】" + nameElement.getName() + ":" + nameElement.getText());
- Element valueElement = element.element("value");
- System.out.println(" 【2】" + valueElement.getName() + ":" + valueElement.getText());
- Element descriptElement = element.element("descript");
- System.out.println(" 【2】" + descriptElement.getName() + ":" + descriptElement.getText());
- List<Element> subElementList = element.elements("module");
- for (Element subElement : subElementList) {
- if(!subElement.getTextTrim().equals("")){
- System.out.println(" 【3】" + subElement.getTextTrim());
- }else{
- Element subnameElement = subElement.element("name");
- System.out.println(" 【3】" + subnameElement.getName() + ":" + subnameElement.getText());
- Element subvalueElement = subElement.element("value");
- System.out.println(" 【3】" + subvalueElement.getName() + ":" + subvalueElement.getText());
- Element subdescriptElement = subElement.element("descript");
- System.out.println(" 【3】" + subdescriptElement.getName() + ":" + subdescriptElement.getText());
- }
- }
- }
- }
- }
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
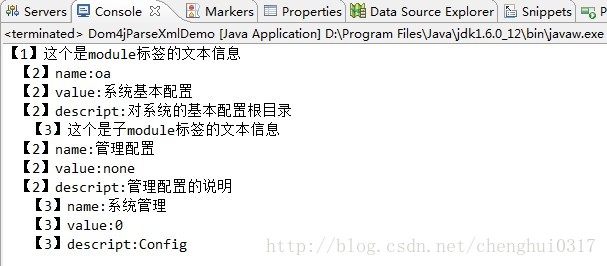
好了,这下可以解决迭代文档出现空引用的情况了。
另外代码其实可以重构一下,因为循环里面取出子元素的操作都是重复的,可以利用递归改善,但是可读性会变差一点。
如果有些时候需要获取xml中所有的文本信息,又或者别人传递的xml格式不规范,比如标签内名称大小写,虽然xml不区分大小写,但是必须成对出现,所以为了避免这种情况,索性可以将全部的标签名称换为大写,具体代码如下:
- public static void main(String[] args) {
- String str = "<?xml version=\"1.0\" encoding=\"UTF-8\"?><modules id=\"123\"><module> 这个是module标签的文本信息<name>oa</name><value>系统基本配置</value><descript>对系统的基本配置根目录</descript></module></modules>";
- System.out.println(str.replaceAll("<[^<]*>", "_"));
- Pattern pattern = Pattern.compile("<[^<]*>");
- Matcher matcher = pattern.matcher(str);
- while(matcher.find()){
- str = str.replaceAll(matcher.group(0), matcher.group(0).toUpperCase());
- }
- System.out.println(str);
- }

2、生成xml文档
dom4j能够解析xml,同样肯定能生成xml,而且使用起来更加简单方便。
实现思路:
<1>DocumentHelper提供了创建Document对象的方法;
<2>操作这个Document对象,添加节点以及节点下的文本、名称和属性值;
<3>然后利用XMLWriter写入器把封装的document对象写入到磁盘中;
具体代码如下:
- import java.io.FileWriter;
- import java.io.IOException;
- import java.io.Writer;
- import org.dom4j.Document;
- import org.dom4j.DocumentHelper;
- import org.dom4j.Element;
- import org.dom4j.io.XMLWriter;
- /**
- * 使用dom4j生成xml文档
- * @author Administrator
- *
- */
- public class Dom4jBuildXmlDemo {
- public void build01(){
- try {
- //DocumentHelper提供了创建Document对象的方法
- Document document = DocumentHelper.createDocument();
- //添加节点信息
- Element rootElement = document.addElement("modules");
- //这里可以继续添加子节点,也可以指定内容
- rootElement.setText("这个是module标签的文本信息");
- Element element = rootElement.addElement("module");
- Element nameElement = element.addElement("name");
- Element valueElement = element.addElement("value");
- Element descriptionElement = element.addElement("description");
- nameElement.setText("名称");
- nameElement.addAttribute("language", "java");//为节点添加属性值
- valueElement.setText("值");
- valueElement.addAttribute("language", "c#");
- descriptionElement.setText("描述");
- descriptionElement.addAttribute("language", "sql server");
- System.out.println(document.asXML()); //将document文档对象直接转换成字符串输出
- Writer fileWriter = new FileWriter("c:\\module.xml");
- //dom4j提供了专门写入文件的对象XMLWriter
- XMLWriter xmlWriter = new XMLWriter(fileWriter);
- xmlWriter.write(document);
- xmlWriter.flush();
- xmlWriter.close();
- System.out.println("xml文档添加成功!");
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- public static void main(String[] args) {
- Dom4jBuildXmlDemo demo = new Dom4jBuildXmlDemo();
- demo.build01(); //将方法定义为static就不用new对象了。
- }
- }
运行代码效果如下:
然后去c盘下面查看是否创建成功,结果发现在xml文件中的内容与控制台输出的内容一样。
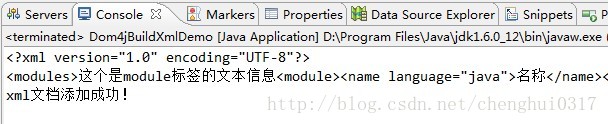
另外上面生成xml并没有指定编码格式,但是还是显示了UTF-8,说明这个是默认的编码格式,如果想重新指定可以在写入到磁盘之前加上document.setXMLEncoding("GBK");就好了。















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









