







exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当 exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录,反之如果exists里的条 件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为 false
如下:
select * from user where exists (select 1);
对user表的记录逐条取出,由于子条件中的select 1永远能返回记录行,那么user表的所有记录都将被加入结果集,所以与 select * from user;是一样的
又如下
select * from user where exists (select * from user where userId = 0);
可以知道对user表进行loop时,检查条件语句(select * from user where userId = 0),由于userId永远不为0,所以条件语句永远返回空集,条件永远为false,那么user表的所有记录都将被丢弃
not exists与exists相反,也就是当exists条件有结果集返回时,loop到的记录将被丢弃,否则将loop到的记录加入结果集
总的来说,如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询
select * from user where userId in (1, 2, 3);
等效于
select * from user where userId = 1 or userId = 2 or userId = 3;
not in与in相反,如下
select * from user where userId not in (1, 2, 3);
等效于
select * from user where userId != 1 and userId != 2 and userId != 3;
总的来说,in查询就是先将子查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后在将子查询条件的结果集分解成m个,再进行m次查询
值得一提的是,in查询的子条件返回结果必须只有一个字段,例如
select * from user where userId in (select id from B);
而不能是
select * from user where userId in (select id, age from B);
而exists就没有这个限制
下面来考虑exists和in的性能
考虑如下SQL语句
1: select * from A where exists (select * from B where B.id = A.id);
2: select * from A where A.id in (select id from B);
查询1.可以转化以下伪代码,便于理解
for ($i = 0; $i < count(A); $i++) {
$a = get_record(A, $i); #从A表逐条获取记录
if (B.id = $a[id]) #如果子条件成立
$result[] = $a;
}
return $result;
大概就是这么个意思,其实可以看到,查询1主要是用到了B表的索引,A表如何对查询的效率影响应该不大
假设B表的所有id为1,2,3,查询2可以转换为
select * from A where A.id = 1 or A.id = 2 or A.id = 3;
这个好理解了,这里主要是用到了A的索引,B表如何对查询影响不大
下面再看not exists 和 not in
1. select * from A where not exists (select * from B where B.id = A.id);
2. select * from A where A.id not in (select id from B);
看查询1,还是和上面一样,用了B的索引
而对于查询2,可以转化成如下语句
select * from A where A.id != 1 and A.id != 2 and A.id != 3;
可以知道not in是个范围查询,这种!=的范围查询无法使用任何索引,等于说A表的每条记录,都要在B表里遍历一次,查看B表里是否存在这条记录
故not exists比not in效率高
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select * from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;
select * from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。
相反的
2:
select * from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;
select * from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
场景1:当IN中的取值只有一个主键时
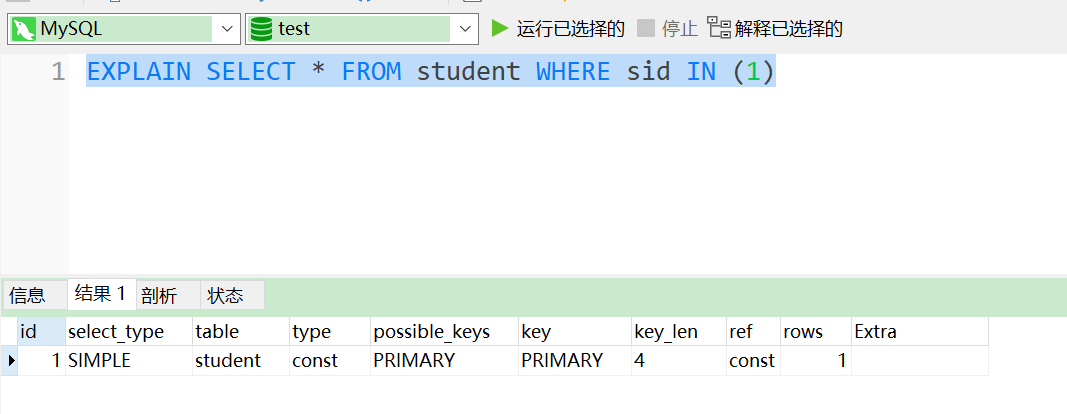
我们只需要注意一个最重要的type 的信息很明显的提现是否用到索引:
type结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
all:全表扫描
index:另一种形式的全表扫描,只不过他的扫描方式是按照索引的顺序
range:有范围的索引扫描,相对于index的全表扫描,他有范围限制,因此要优于index
ref: 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。这样即使使用索引快速查找到了第一条数据,仍然不能停止,要进行目标值附近的小范围扫描。但它的好处是它并不需要扫全表,因为索引是有序的,即便有重复值,也是在一个非常小的范围内扫描。
const:通常情况下,如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。至于如何转化以及何时转化,这个取决于优化器
一般来说,得保证查询至少达到range级别,最好能达到ref,type出现index和all时,表示走的是全表扫描没有走索引,效率低下,这时需要对sql进行调优。
当extra出现Using filesor或Using temproary时,表示无法使用索引,必须尽快做优化。
possible_keys:sql所用到的索引
key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
rows: 显示MySQL认为它执行查询时必须检查的行数。
场景2:扩大IN中的取值范围
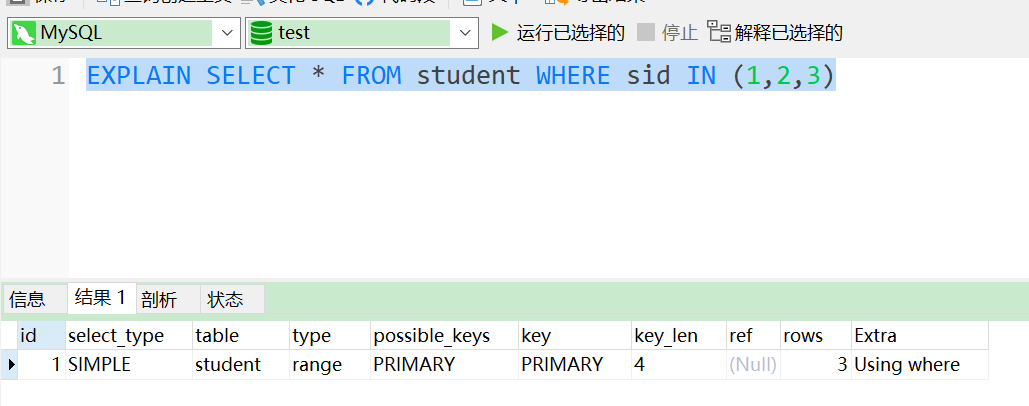
此时仍然走了索引,但是效率降低了
场景3:继续扩大IN的取值范围
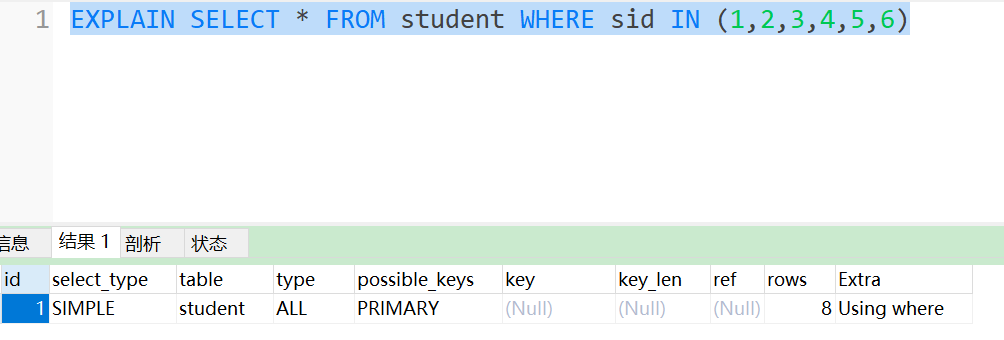
看上面的图,发现此时已经没有走索引了,而是全表扫描。
在说一下结论
结论:IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描。
By the way:如果使用了 not in,则不走索引。
对于in的优化可以使用join进行代替
delete in不走索引的排查
MySQL版本是5.7,假设当前有两张表account和old_account,表结构如下:
CREATE TABLE `old_account` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',
`name` varchar(255) DEFAULT NULL COMMENT '账户名',
`balance` int(11) DEFAULT NULL COMMENT '余额',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='老的账户表';
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',
`name` varchar(255) DEFAULT NULL COMMENT '账户名',
`balance` int(11) DEFAULT NULL COMMENT '余额',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
复制代码执行的SQL如下:
delete from account where name in (select name from old_account);
复制代码我们explain执行计划走一波,

从explain结果可以发现:先全表扫描 account,然后逐行执行子查询判断条件是否满足;显然,这个执行计划和我们预期不符合,因为并没有走索引。
但是如果换成把delete换成select,就会走索引。如下:

为什么select in子查询会走索引,delete in子查询却不会走索引呢?
原因分析
select in子查询语句跟delete in子查询语句的不同点到底在哪里呢?
我们执行以下SQL看看
explain select * from account where name in (select name from old_account);
show WARNINGS;
复制代码show WARNINGS 可以查看优化后,最终执行的sql
结果如下:
select `test2`.`account`.`id` AS `id`,`test2`.`account`.`name` AS `name`,`test2`.`account`.`balance` AS `balance`,`test2`.`account`.`create_time` AS `create_time`,`test2`.`account`.`update_time` AS `update_time` from `test2`.`account`
semi join (`test2`.`old_account`)
where (`test2`.`account`.`name` = `test2`.`old_account`.`name`)
复制代码可以发现,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。
优化方案
那如何优化这个问题呢?通过上面的分析,显然可以把delete in子查询改为join的方式。我们改为join的方式后,再explain看下:

可以发现,改用join的方式是可以走索引的,完美解决了这个问题。
实际上,对于update或者delete子查询的语句,MySQL官网也是推荐join的方式优化

其实呢,给表加别名,也可以解决这个问题哦,如下:
explain delete a from account as a where a.name in (select name from old_account)
复制代码
为什么加别个名就可以走索引了呢?
what?为啥加个别名,delete in子查询又行了,又走索引了?
我们回过头来看看explain的执行计划,可以发现Extra那一栏,有个LooseScan。

LooseScan是什么呢? 其实它是一种策略,是semi join子查询的一种执行策略。
因为子查询改为join,是可以让delete in子查询走索引;而加别名,会走LooseScan策略,而LooseScan策略,本质上就是semi join子查询的一种执行策略。
因此,加别名就可以让delete in子查询走索引啦!
作者:捡田螺的小男孩
链接:https://juejin.cn/post/7013127536972398606
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









