







对于一个游戏,如果有聊天功能,那么我们就会希望我们的聊天系统能够对玩家的输入进行判断,如果玩家的输入中含有一些敏感词汇,那么我们就禁止玩家发送聊天,或者把敏感词转换为 * 来替换。
为什么要使用 DFA 算法
设我们已经有了一个敏感词词库(从相关部门获取到的,或者网上找来的),那么我们最容易想到的过滤敏感词的方法就是:
遍历整个敏感词库,拿到敏感词,再判断玩家输入的字符串中是否有该敏感词,如果有就把敏感词字符替换为 *
但这样的方法,我们需要遍历整个敏感词库,并且对玩家输入的字符串进行替换。而整个敏感词库中一般会有上千个字符串。而玩家聊天输入的字符串一般也就 20~30 个字符。
因此,这种方法的效率是非常低的,无法应用到真实的开发中。
而使用 DFA 算法就可以实现高效的敏感词过滤。使用 DFA 算法,我们只需要遍历一遍玩家输入的字符串即可将所有存在的敏感词进行替换。
DFA 算法原理
DFA 算法是通过提前构造出一个 树状查找结构(实际上应该说是一个 森林),之后根据输入在该树状结构中就可以进行非常高效的查找。
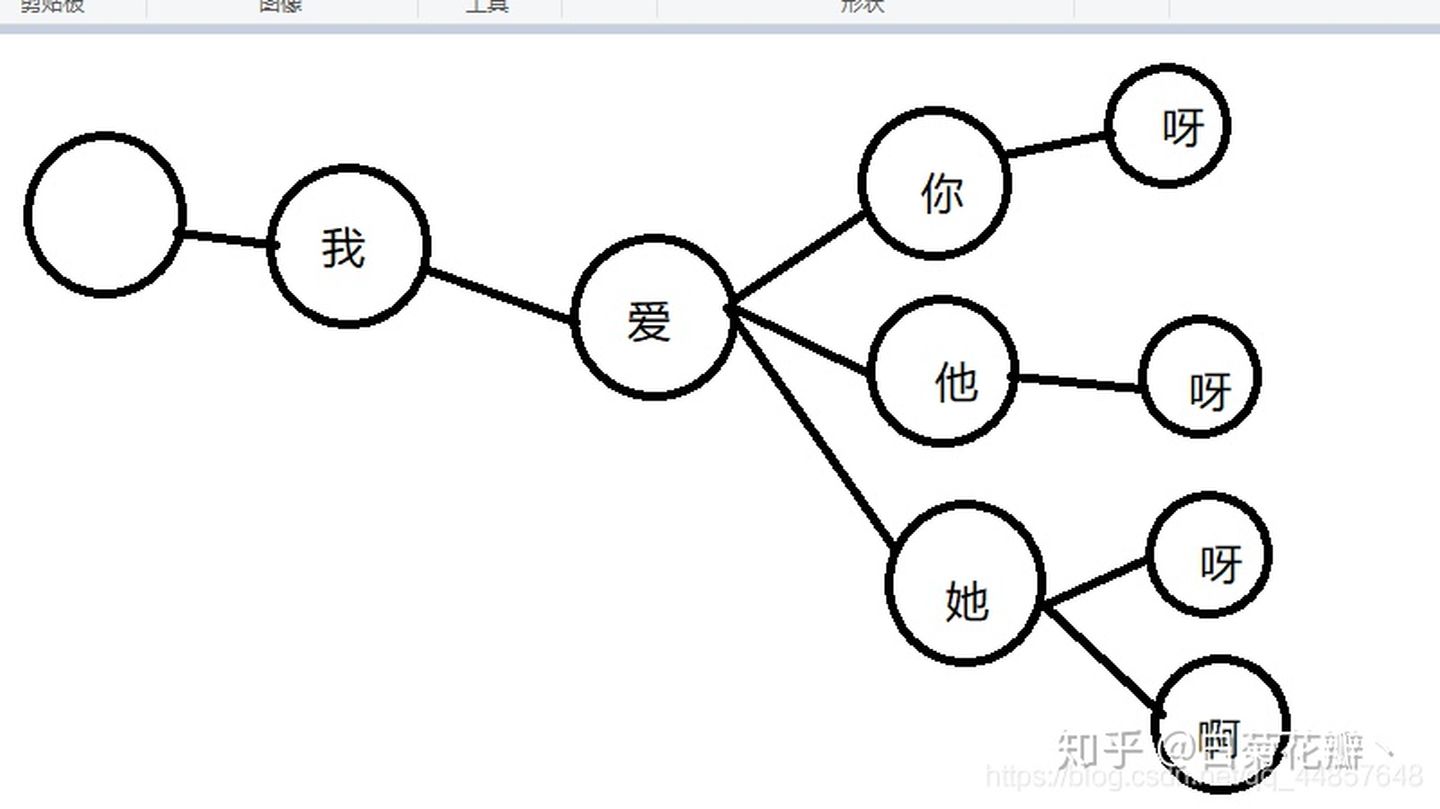
设我们有一个敏感词库,词酷中的词汇为:
我爱你
我爱他
我爱她
我爱你呀
我爱他呀
我爱她呀
我爱她啊
那么就可以构造出这样的树状结构:
设玩家输入的字符串为:白菊我爱你呀哈哈哈
我们遍历玩家输入的字符串 str,并设指针 i 指向树状结构的根节点,即最左边的空白节点:
str[0] = ‘白’ 时,此时 tree[i] 没有指向值为 ‘白’ 的节点,所以不满足匹配条件,继续往下遍历
str[1] = ‘菊’,同样不满足匹配条件,继续遍历
str[2] = ‘我’,此时 tree[i] 有一条路径连接着 ‘我’ 这个节点,满足匹配条件,i 指向 ‘我’ 这个节点,然后继续遍历
str[3] = ‘爱’,此时 tree[i] 有一条路径连着 ‘爱’ 这个节点,满足匹配条件,i 指向 ‘爱’,继续遍历
str[4] = ‘你’,同样有路径,i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









