




学习资料来自于https://www.codecademy.com/,所有的sql语句以SQLite关系型数据库管理系统为例。
Unit 1. Manipulation
示例表: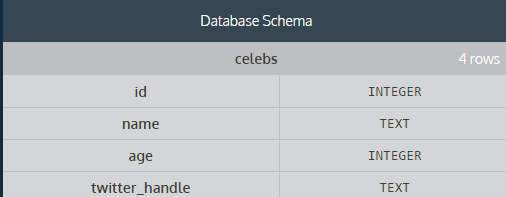
1.1创建表
示例: create table celebs(id integer, name text, age integer);//括号中列出各字段以及各字段的类型
1.2 插入记录
示例: insert into celebs(id, name, age) values(1, 'Justin Bieber', 21 );//第一个括号的字段顺序不一定,但是只要values后面的字段与前面的字段顺序对应就行了
1.3 修改/更新记录
示例: update celebs set age=22 where id = 1;
1.4 修改/更新表结构
示例: alter table celebs add column twitter_handle text;//当添加了新的列时,以前已经存在的数据的这一列自动设置为NULL值
1.5 删除
示例: delete from celebs where twitter_handle is null;
Unit 2. Queries
示例表:

2.1 distinct的使用
说明:过滤掉结果集中的重复值。SELECT DISTINCT
is used toreturn unique values in the result set. It filters out all duplicate values.
示例: select distinct genre from movies;
2.2 where子句可用的关系运算符
说明:关系运算操作产生了一个条件运算,它可以返回True或者False,用于where子句中。 Operators create a condition thatcan be evaluated as either true or false. Common operators used with the
WHERE clause are: =, !=, >, <, >=, <=
2.3 like的使用
说明:1.like用于where子句中,用于查找某一列的特定的模式。
2.like后面的模式串中可以使用通配符。可以使用下滑线_和%。
示例: select * from movies where name like 'Se_en';
返回结果:
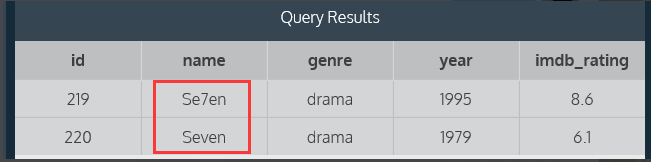
说明:Se_en中的_表示通配符,可以使用任何单个字符替代它,而%可代表0个或多个字符。
示例:select * from movies where name like 'a%';
返回结果:

示例: select * from movies where name like '%man%';
返回结果:

说明:SELECT * FROM movies WHERE name LIKE 'A%';
% is a wildcard character(通配符) that matches zero or more missing letters in the pattern.%代表0个或多个字符。
• A% matches all movies with names that
begin with "A"
• %a matches all movies that
end with "a"
SELECT * FROM movies WHERE name LIKE '%man%';
You can use % both before and after a pattern. Here, any movie that contains the word "man" in its name will be returned in the result set. Notice, that LIKE is not case sensitive. "Batman" and "Man Of Steel" both appear in the result set. like对大小写不敏感。
2.4 between and的使用
示例: select * from movies where name between 'A' and 'J';
select * from movies where year between 1990 and 2000;
2.5 AND 与OR运算
说明:AND
and OR operator can be used with the
WHERE clause,大小写皆可。
2.6 排序order by
示例: select * from movies order by imdb_rating desc;
说明:按某列进行排序,排序可依据与字母序和数值大小顺序;desc是降序,asc是升序,DESC is a keyword in SQL that is used with ORDER BY to sort the results in descending order (high to low or Z-A). Here, it sorts all of the movies from highest to lowest by their IMDb rating.It is also possible to sort the results in ascending order. ASC is a keyword in SQL that is used with ORDER BY to sort the results in ascending order (low to high or A-Z).
2.7 limit的使用
要求:write a query that only returns the three lowest rated movies.
示例: select * from movies order by imdb_rating asc limit 3;
说明:Sometimes even filtered results can return thousands of rows in large databases. In these situations it becomes important to cap the number of rows in a result set.
LIMIT is a clause that lets you specify the maximum number of rows the result set will have. Here, we specify that the result set can not have more than three rows.
Unit 3. Aggregate Functions
示例表:
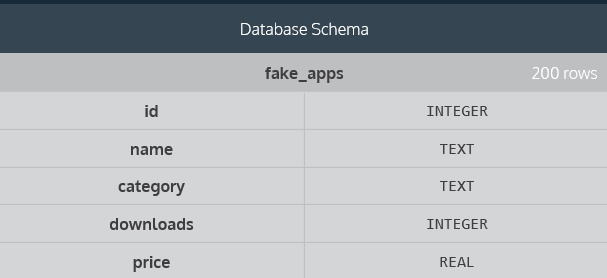
3.1 count()的使用
要求:count how many apps are in the database
示例:select count(*) from fake_apps;
说明:用于计算行数。一般用列名作为参数,计算参数列的列值不为NULL的行数,如果不是依据于某列而是每一行,则使用*作为参数。The fastest way to calculate the number of rows in a table is to use the COUNT() function.
COUNT() is a function that takes the name of a column as an argument and counts the number of rows where the column is not NULL. Here, we want to count every row so we pass * as an argument.
3.2 group by的使用
要求:Count the number of apps at each price.
示例: select price, count(*) from fake_apps group by price;
返回结果:
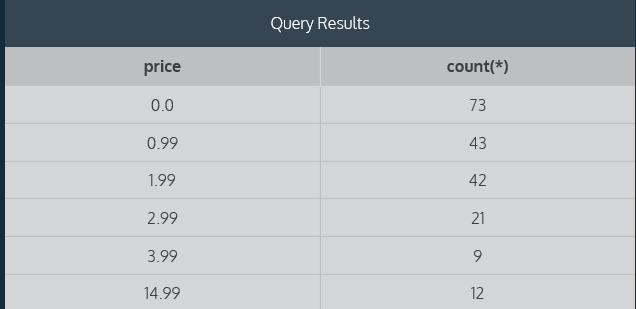
说明:group by仅用于聚合函数,它与select子句协作,把具有相同值得数据分为一组。Here, our aggregate function is COUNT() and we are passing price as an argument to GROUP BY. SQL will count the total number of apps for each price in the table. It is usually helpful to SELECT the column you pass as an argument to GROUP BY. Here we select price and COUNT(*). You can see that the result set is organized into two columns making it easy to see the number of apps at each price.
要求:Count the total number of apps at each price that have been downloaded more than 20,000 times.
示例: select price, count(*) from fake_apps where downloads > 20000 group by price;
3.3 sum()的使用
要求:What is the total number of downloads for all of the apps combined?
示例: select sum(downloads) from fake_apps;
要求:Calculate the total number of downloads for each category.
示例:select category, sum(downloads) from fake_apps group by category;
3.4 max()的使用
要求:How many downloads does the most popular app have?
示例: select max(downloads)from fake_apps;
要求:Return the names of the most downloaded apps in each category.
示例: select name, category, max(downloads)from fake_apps group by category;
3.5 min()的使用
要求:What is the least number of times an app has been downloaded?
示例:select min(downloads)from fake_apps;
3.6 avg()的使用
要求:Calculate the average number of downloads for an app in the database.
示例: select avg(downloads)from fake_apps;
要求:Calculate the average number of downloads at each price.
示例: select price, avg(downloads) from fake_apps group by price;
返回结果:

3.7 round()的使用
要求:Make the result set more readable by rounding the average number of downloads to two decimal places for each price.
示例: select price, round(avg(downloads),2) from fake_apps group by price;
返回结果:

说明:round函数以一个列名和一个整数作为参数,保留整数参数的小数位数,ROUND() is a function that takes a column name and an integer as an argument. It rounds the values in the column to the number of decimal places specified by the integer. Here, we pass the column AVG(downloads) and 2 as arguments. SQL first calculates the average for each price and then rounds the result to two decimal places in the result set.
Unit4. Multiple Tables
The data in these tables are related to each other. Through SQL, we can write queries that combine data from multiple tables that are related to one another. This is one of the most powerful features of relational databases.
Imagine a database with two tables, artists and albums. An artist can produce manydifferent albums, and an album is produced by an artist.
示例表:

4.1 主键
要求:假设表albums已有,现在创建表artists
示例:create table
artists(id integer primary key, name text);
说明:A primary key serves as a unique identifier for each row or record in a given table. The primary key is literally an id value for a record. We're going to use this value to connect artists to the albums they
have produced.
By specifying that the id column is the PRIMARY KEY, SQL makes sure that:
(1) None of the values in this column are NULL
(2) Each value in this column is unique
A table can not have more than one PRIMARY KEY column.
4.2 多表查询
示例: select albums.name, year,artists.name from albums, artists;
4.3 join的使用
示例:select * from albums join artists on albums.artist_id = artists.id;
4.4 left join的使用
数据库里并不是每一个album 都对应一个artist,而4.3的查询将不会返回那些没有artist的album,如果也要返回这样的album,那么可使用left join
示例:select * from albums left join artists on albums.artist_id= artists.id;
返回结果:
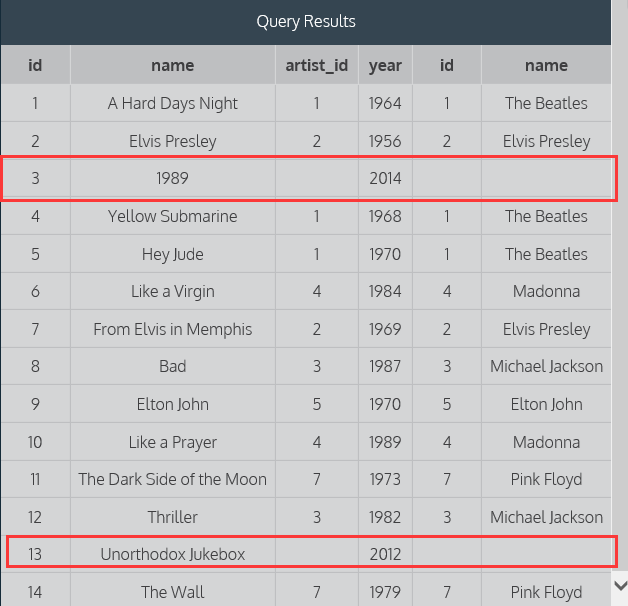
说明:Outer joins also combine rows from two or more tables, but unlike inner joins, they do not require the join condition to be met. Instead, every row in the left table is returned in the result set, and if the join condition is not met, then NULL values
are used to fill in the columns from the right table.
The left table is simply the first table that appears in the statement. Here, the left table is albums. Likewise, the right table is the second table that appears. Here, artists is the right table.
4.5 使用as重命列名
当两个表有相同的列名时容易产生混淆,可用as解决
示例:select albums.name as 'Album', albums.year, artists.name as 'Artist' from albums join artists on albums.artist_id = artists.id where albums.year > 1980;
说明:AS is a keyword in SQL that allows you to rename a column or table using an alias. The new name can be anything you want as long as you put it inside of single quotes. Here we want to rename the albums.name column as 'Album', and the artists.name column
as 'Artist'.
It is important to note that the columns have not been renamed in either table. The aliases only appear in the result set.
补充
1. having的使用
参考自:http://www.cnblogs.com/wang-123/archive/2012/01/05/2312676.html
示例:
create TABLE Table1 (
ID int identity(1,1) primary key NOT NULL,
classid int,
sex varchar(10),
age int);
查询table表查询每一个班级中年龄大于20,性别为男的人数:
select COUNT(*) as '>20岁人数',classid from Table1 where sex='男' group by classid,age having age>20 ;
说明:
--需要注意说明:当同时含有where子句、group by 子句 、having子句及聚集函数时,执行顺序如下:
--执行where子句查找符合条件的数据;
--使用group by 子句对数据进行分组;对group by 子句形成的组运行聚集函数计算每一组的值;最后用having 子句去掉不符合条件的组。
--having 子句中的每一个元素也必须出现在select列表中。有些数据库例外,如oracle.
--having子句和where子句都可以用来设定限制条件以使查询结果满足一定的条件限制。
--having子句限制的是组,而不是行。where子句中不能使用聚集函数,而having子句中可以。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









