









实体链指(2)EL:Disambiguation-Only
前面已经由一篇综述大致了解了Entity Linking的定义和任务框架,且知道其实现有2种主流的方法:Disambiguation-Only 和 End-to-End ,接下来分别介绍这种方法具有代表性的几篇文章。本篇主要介绍Disambiguation-Only。
| PAPER | CONF | CODE |
|---|---|---|
| Neural Cross-Lingual Entity Linking | AAAI, 2018 | |
| Scalable Zero-shot Entity Linking with Dense Entity Retrieval | EMNLP, 2020 | https://github.com/facebookresearch/BLINK/tree/main/blink |
1 Neural cross-lingual entity linking
这是一篇2018年的文章,处于前BERT时期,是跨语言实体链指任务,其中链指是English Wikipedia link:。先从一组示例来看看作者idea的出发点:

query提到的Alex Smith是一个美国橄榄球运动员,是给出的三个候选实体都是运动员,其中e3是Golf而不是American football,仅使用简单的相似度计算就能排除掉,但对于e1和e2中的Alexander Smith,都提到了American football players,甚至都还提到了关键词NEL(美国国家橄榄球联盟)。这就非常难以区分了。所以作者认为需要进行更精细粒度的context特征提取,来从各个层面衡量mention和实体的title page之间的相似性,才有能力处理这种hard ambiguous cases。
这篇文章的模型框架很简单,就是在输入特征准备好的情况下做分类,而这篇的关键之处,是在于如何构建细粒度上下文进行建模。文章中召回阶段使用的是Fast Match Search,通过在wiki数据上构建类似倒排索引来产出候选。下面主要介绍排序阶段的模型搭建,由下而上来看看作者是如何精心设计各种细粒度的特征表征和相似度计算的。
Embeddings
- Monolingual Word Embeddings
单语数据集上词嵌入使用的是基于COW的word2vec - Multi-lingual Embeddings
跨语言词嵌入使用了CCA、MultiCCA、WLS:是一些处理跨语言的方法,主要是将平行语料中某种语言的word embeding投影到英文word embedding的向量空间 - Wikipedia Link Embeddings
利用预训练好的word embeddings 进行加权平均,权重为IDF,为了减少高频词的影响: e p = ∑ e ∈ p e w i d f w ∑ e ∈ p i d f w e_p=\frac{\sum_{e\in p}e_widf_w}{\sum_{e\in p}idf_w} ep=∑e∈pidfw∑e∈pewidfw,然后接FC-tanh layer 以将其映射到与mention context同一语义空间。
典型相关分析 (CCA):该技术基于 (Faruqui 和 Dyer 2014),他们首先通过对不同语言的文本执行 SVD 来学习向量,然后在平行语料库中对齐的单词的向量对上应用 CCA。对于跨语言 EL,我们使用 (Tsai and Roth 2016) 提供的嵌入,使用从 Wikipedia 中的跨语言链接获得的标题映射构建。
MultiCCA:由 (Ammar et al. 2016) 引入,该技术建立在 CCA 的基础上,并使用线性算子将每种语言(英语除外)中预训练的单语嵌入投影到预训练的英语单词嵌入的向量空间。
加权最小二乘法 (LS):由 (Mikolov, Le, and Sutskever 2013) 引入,外语嵌入直接投影到英语上,映射是通过多元回归构建的。
Modeling Contexts
Modeling Sentences
输入文本Document侧:作者认为整个doc中不是所有的句子都对m的识别和消歧有用,而是那些包含了m或在m附近的句子,所以提取了这部分句子,然后使用CNN+mean pooling。
候选entity context建模:使用wiki的第一段,也是CNN+mean pooling。
Fine-grained context modeling
作者认为mention附近的单词比离得远的词更具有指示性,而前面提到的context表征是基于大部分句子的建模,可能无法提取出这种区分度,所以需要更细粒度的context 表征:作者采用一个长度为4的窗口来提取m附近的单词,每个m的上文使用前向LSTM,下文使用后向LSTM,m的上文和下文分别做mean-pooling后最后拼接在一起经过一个NTN网络,得到最后的context表征:
N
T
N
(
l
,
r
;
W
)
=
f
(
[
l
r
]
t
W
1
,
.
.
.
,
k
[
l
r
]
)
NTN(l,r;W)=f(\begin{bmatrix}l\\r\\\end{bmatrix}^t W_{1,...,k}\begin{bmatrix}l\\r\\\end{bmatrix})
NTN(l,r;W)=f([lr]tW1,...,k[lr])

Feature Abstraction Layer
有了前面的embedding和context表征的基础,接下来就是从各个层面提取不同粒度的相似性打分,最后综合各种相似度打分来最终决策候选实体是否是正确的link。
所以接下来就是本文的关键:来提取各种不同粒度的相似性打分。第一类是上下文表征的相似性 + MPBL,第二类是语义相似性和不同性:
- A.Similarity Features by comparing Context Representations
- “Sentence context - Wiki Link” Similarity
m相关句子表征(Sentence context )和候选实体的embedding的余弦相似度 - “Sentence context - Wiki First Paragraph” Similarity
Sentence context 和 候选实体的Sentence context(第一段) 的余弦相似度 - “Fine-grained context - Wiki Link” Similarity
mention细粒度的context表征 和 候选实体的embedding的余弦相似度 - Within-language Features
最后还有一些基于LIEL system的局部特征:例如m和e的title重合多少个字,e的别名在query doc中出行多少次等
- “Sentence context - Wiki Link” Similarity
- B.Semantic Similarities and Dissimilarities
- Lexical Decomposition and Composition (LDC)
LDC:通过词汇分解和组合进行句子相似度学习。 - Multi-perspective Context Matching (MPCM)
Context表征 + MPCM layer(多视角context匹配)
- Lexical Decomposition and Composition (LDC)
Neural Model Architecture
模型框架很简单,就是上述输入特征准备好的情况下做分类,即利用各种粒度和不同层次不同视角的qyery-mention、entity表征来计算各种不同粒度的相似度打分,如下图所示:

图中顶部C是二元Boolean变量,S即特征抽取层产出的不同的相似度打分。
Experiments & Results

首先是在英文单语言数据集上:CoNLL数据集含有1393篇文章、 3.4w个mentions;TAC2010含有3750个web queries和新闻, 含有人名、组织机构、地缘政治3种实体。在CONLL数据集上,加了细粒度上下文的模型(This work+CtxLSTMS)几乎优于所有模型,除了最后一个(Yamada et al. 2016)。其中第2个模型(Gupta et al. 2017)还实体了KB中实体type信息,本文比该模型高出7.5%;倒数第2项工作(Globerson et al. 2016)使用了多角度的attention机制,本文比模型高出1.27%。再加入LDC和MPCM后,作者的工作又有了显著的提升,高了1个点,并且超越了所有模型。在TAC2010数据集上:作者的模型比目前最好的模型也要高出0.2个点。
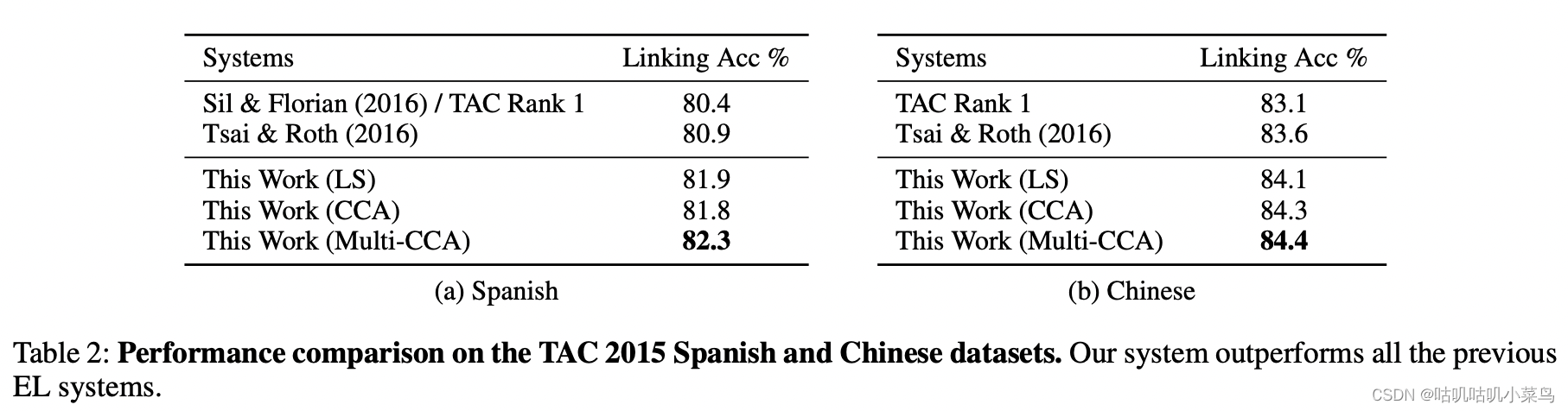
TAC 2015 是三语EL数据集,含有166篇中文文章和167西班牙文章,mention包含人名、地缘政治实体、组织机构、地点、基础设施等5种实体(在跨语言的数据集中,是利用训练好的多语言的词向量表示,词向量可是采用前文提到的CCA、Multi-CCA、WLS等方式)。从结果上看,无论使用哪种跨语言词嵌入,本文的方法都优于当前最好的方法,这也说明我作者的提取多层次细粒度的context表征是非常有效的。
总结:
- 本文旨在采用更精细粒度的、不同层面不同视角的相似度计算,然后综合各个层面来决策最终的gold entity
- 本文不论是在单语言还是在跨语言的EL数据集上都实现了SOTA效果,说明作者最初的出发点是work的。
2 Scalable zero-shot entity linking with dense entity retrieval
这篇是2019年的一篇文章,处理后BERT时代,用于解决zero shot EL,即训练时使用的KB和测试时的KB交集为0:
E
t
r
a
i
n
∩
E
t
e
s
t
=
∅
E_{train} \cap E_{test} = \emptyset
Etrain∩Etest=∅。本文模型是基于BERT,特点就是简单、高效、准确。简单之处体现在:它不像之前那篇去精心设计各种粒度的context 表征和相似度计算,而是依靠强大的BERT去抽取context 表征,最后还针对accuracy-speed trade-off(模型的准确率和速度上的平衡)提出了相应的解决思路。

看模型架构图,实体链指依然是分为2阶段:召回和排序阶段。
Bi-encoder
第1步是召回,使用Bi-encoder即2个独立的Bert transformers 对(m,e)pair建模,由于候选实体的表征可以预存,所以Bi-encoder能支持快速的、实时的infer。其中候选的表征是基于wiki页面的前10个句子作为实体描述信息,mention表征是基于其context。Metion和entity通过Bi-encoder得到各自的表征,在同一向量空间基于点乘计算匹配度,然后通过最近邻搜索(KNN)方式得到与mention最接近的topk个候选实体。
- Context and Mention Modeling:
[CLS] c t x t l \rm{ctxt_l} ctxtl [ M s ] \rm{[M_s]} [Ms] mention [ M e ] \rm{[M_e]} [Me] c t x t r \rm{ctxt_r} ctxtr [SEP] - Entity Modeling:
[CLS] t i t l e \rm{title} title [ E N T ] \rm{[ENT]} [ENT] description [SEP]
Cross-encoder
第2步是重排阶段,使用cross-encoder将mention context和entity 描述文本拼接在一起再喂入BERT,其实就是让(m,e)pair的交互发生在更早阶段,模型能学到更多信息。最后再接一个线性层,然后得到所有候选实体的概率分布,以决策最终的gold entity。
- Context-candidate Modeling
[CLS] c t x t l \rm{ctxt_l} ctxtl [ M s ] \rm{[M_s]} [Ms] mention [ M e ] \rm{[M_e]} [Me] c t x t r \rm{ctxt_r} ctxtr [SEP] t i t l e \rm{title} title [ E N T ] \rm{[ENT]} [ENT] description [SEP]
训练时的一些training tricks:使用了random in-batch negatives和hard negatives。bi-encoder和cross-encoder两阶段的训练损失函数相同:
L
(
m
i
,
e
i
)
=
−
s
(
m
i
,
e
i
)
+
log
∑
j
=
1
B
exp
(
s
(
m
i
,
e
j
)
)
L(m_i, e_i)=-s(m_i, e_i)+\log \sum_{j=1}^B \exp(s(m_i,e_j))
L(mi,ei)=−s(mi,ei)+logj=1∑Bexp(s(mi,ej))
其中
s
(
m
i
,
e
i
)
s(m_i, e_i)
s(mi,ei)为打分。
Knowledge Distillation
最后要提到的是作者为了解决acc-speed tradeoff的问题,还使用了知识蒸馏:为了更好地优化准确性-速度权衡,作者进行了使用Cross-encoder作为teacher模型去指导bi-encoder作为学生模型的知识蒸馏实验,使得bi-encoder能在快速infer的基础上,也能进一步提升准确率。也就是说预期最后在只保留Bi-encoder的情况下,infer时又快又准。相当于当mention表征与各个候选实体的(预存)表征的点乘打分最高的则直接作为gold entity。
使用带有温度参数的softmax: σ ( z , T ) = exp ( z i / T ) ∑ j exp ( z j / T ) \sigma(z,T)=\frac{\exp(z_i/T)}{\sum_j \exp(z_j/T)} σ(z,T)=∑jexp(zj/T)exp(zi/T)。
蒸馏loss:
L
d
i
s
t
=
H
(
σ
(
z
t
;
τ
)
,
σ
(
z
s
;
τ
)
)
)
L_{dist}=H(\sigma(z_t;\tau), \sigma(z_s;\tau)))
Ldist=H(σ(zt;τ),σ(zs;τ)))
学生loss:
L
s
t
=
H
(
e
,
σ
(
z
s
;
1
)
)
L_{st}=H(e, \sigma(z_s;1))
Lst=H(e,σ(zs;1))
总loss:
L
=
α
⋅
L
s
t
+
(
1
−
α
)
⋅
L
d
i
s
t
L = \alpha \cdot L_{st} + (1-\alpha) \cdot L_{dist}
L=α⋅Lst+(1−α)⋅Ldist
Experiments & Results
实验主要在3个数据集上进行。

第1个是Zero-shot EL dataset,大概4.9w的训练集和1w的测试集,且测试集和训练集的实体来自不同的领域,候选数为top64。从表中结果可以看到本文的模型获得了更好的效果,比当前该数据集上的最好模型高出近5个点。

第2个数据集是TACKBP-2010,一个被广泛使用的EL数据集,本文模型首先在wiki数据上进行了预训练,然后在此数据集上finetune,候选数设置为top100,并且作者还使用了基于不同版本模型做了一些消融实验,从结果上看:cross-encoder确实比bi-encoder在ranking上效果更好,但是这两版模型都超过了当前SOTA模型:
- Ours:指在wiki数据上做预训练,在TACKBP数据上finetune的版本
- bi-encoder only: 只使用Bi-encoder并直接使用此阶段(m,e)点乘得分代替cross-encoder的重排打分
- Full Wikipedia: 使用wiki数据作为KB 代替TACKBP数据做KB,其他同1
- Full Wikipedia w/o finetune: 同3,只是没有finetune阶段

第3个数据集是 WikilinksNED dataset,包含了各个领域的歧义性实体,并且测试集测试也是在训练集不可见的。和TACK一样先在wiki数据上对bi-encoder 和 cross-encoder 模型进行预训练,然后在此数据集上进行finetune。看表6,本文模型效果超过了所有baseline。
总结:本文只是通过简单的文本context和描述,就能超越以往精心设计的特征抽取方式,例如之前那些使用同义词词典、别名、entity type、link popularity 等特征的方法,本文模型依靠强大的BERT仅做了简单的特征抽取,就达到了 zero-shot benchmark的SOTA 水平。
[1] Sil, Avirup, et al. “Neural cross-lingual entity linking.” Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[2] Wu, Ledell, et al. “Scalable zero-shot entity linking with dense entity retrieval.” arXiv preprint arXiv:1911.03814 (2019).
如果需要其他NLP相关内容请移步至: 我的github:https://github.com/qingyujean/Magic-NLPer,求赞求星求鼓励~~~
最后:如果本文中出现任何错误,请您一定要帮忙指正,感激~














 2434
2434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









