- 博客(228)
- 资源 (21)
- 收藏
- 关注
 RSS订阅
RSS订阅
原创 用sql教你什么是mysql的四种隔离级别
事务的基本要素A 原子性、C 一致性、I 隔离性、D 持久性。事务并发产生的问题脏读,不可重复读幻读mysql事务隔离级别读未提交 read-uncommitted读已提交 RC read-committed可重复读 RR repeatable-read (mysql默认的隔离级别为 RR)串行化 serializable读未提交事务A读取到了事务B未提交的数据。首先,在开启两个query的窗口,都执行下面的两行sql-- 先执行下,可以看到mysq
2020-09-18 00:04:54
 2027
2027
 2
2
原创 自旋锁以及Java中的自旋锁的实现
什么是自旋锁多线程中,对共享资源进行访问,为了防止并发引起的相关问题,通常都是引入锁的机制来处理并发问题。获取到资源的线程A对这个资源加锁,其他线程比如B要访问这个资源首先要获得锁,而此时A持有这个资源的锁,只有等待线程A逻辑执行完,释放锁,这个时候B才能获取到资源的锁进而获取到该资源。这个过程中,A一直持有着资源的锁,那么没有获取到锁的其他线程比如B怎么办?通常就会有两种方式:1...
2018-08-07 00:45:18
21615
3
原创 macbook intel 打开cursor会闪退
摘要 终端启动Cursor应用时出现EACCES权限错误,提示无法连接到用户目录下的socket文件。解决方案是删除相关应用目录:rm -rf "/Users/csucoderlee/Library/Application Support/Cursor",该命令将清除Cursor应用的配置和缓存文件,解决权限问题。错误源于应用对socket文件的访问权限不足,删除目录后可重新建立正确的文件权限。
2025-09-06 22:13:57
264
原创 找不到或无法加载主类 org.gradle.wrapper.GradleWrapperMain
摘要:项目构建时出现"找不到主类GradleWrapperMain"错误,原因是gradlew脚本中路径配置错误。脚本默认查找wrapper目录下的gradle-wrapper.jar,而实际文件位于gradle/wrapper目录下。这种路径不一致导致系统无法加载GradleWrapperMain类,从而引发ClassNotFoundException。解决方法是将脚本中的路径修改为与项目实际路径一致。
2025-07-17 23:00:00
407
原创 DBeaver连接MySQL8.0报错Public Key Retrieval is not allowed
MySQL 8.0+默认使用caching_sha2_password认证插件,导致DBeaver等客户端连接时可能报错"PublicKeyRetrieval is not allowed"。这是因为客户端需要获取服务器公钥来加密密码,但默认被禁止。解决方法:在DBeaver连接设置中找到Driver Properties,将allowPublicKeyRetrieval参数设置为true即可。
2025-07-12 23:22:11
328
原创 spring-boot-starter-parent 和 spring-boot-dependencies 的区别
【代码】spring-boot-starter-parent 和 spring-boot-dependencies 的区别。
2025-02-11 18:12:03
334
原创 解决VSCode按住Cmd, 点击鼠标左键,代码不跳转的问题
升级了vscode后,发现cmd+鼠标左键不能跳转到代码的实现里去了,而是变成了每点击一下,就多出来一个光标。搜索multi,将Editor: Multi Cursor Modifier 设置成alt即可。
2025-02-06 00:22:39
1704
原创 go语言中的Stringer的使用
Stringer 接口是 Go 语言中一个简单但强大的特性,它允许开发者为自定义类型提供更有意义的字符串表示,增强了代码的可读性和可调试性。当使用 fmt 包的打印函数(如 fmt.Println, fmt.Printf)输出一个实现了 Stringer 接口的类型时,会自动调用其 String() 方法来获取该类型的字符串表示。Go 语言中的 Stringer 是一个非常有用的接口,它在标准库的 fmt 包中定义。实现 Stringer 接口可以使调试更容易,因为它提供了一种自定义类型的可读表示。
2025-02-05 23:20:30
666
原创 Go方法接收者中值类型接收者和指针类型接收者的对比
虽然值接收者在某些方面更灵活,但指针接收者在效率和功能上有其独特的优势。一致性:如果类型的某些方法需要指针接收者(例如,为了修改状态),通常建议该类型的所有方法都使用指针接收者,以保持一致性。接口实现:使用指针接收者的方法只能被指针类型满足,而不能被值类型满足。效率:对于大型结构体,使用值接收者会导致整个结构体被复制,这可能会带来显著的性能开销。语义:有时,使用指针接收者更能表达方法的意图(例如,表示这个方法可能会修改接收者)。可修改性:如果方法需要修改接收者的状态,值接收者只会修改副本,而不是原始对象。
2025-02-04 23:38:34
392
原创 Go语言中的函数闭包
函数闭包(Function Closure)是 Go 语言中一个强大而灵活的特性。闭包是一个函数值,它引用了其外部作用域中的变量。简单来说,闭包"记住"并可以访问创建它的上下文环境。函数闭包是 Go 中实现函数式编程的重要工具,它提供了一种优雅的方式来创建有状态的函数和实现复杂的控制流。在 Go 中,你可以在函数内部定义并返回另一个函数,这个返回的函数就形成了一个闭包。闭包是一个函数,它可以访问其外部作用域中的变量,即使在其外部函数已经返回之后。这个例子创建了一个生成斐波那契数列的闭包。
2025-02-04 23:04:14
571
原创 Go语言中结构体字面量
结构体字面量(Struct Literal)是在 Go 语言中用于创建和初始化结构体实例的一种语法。它允许你在声明结构体变量的同时,直接为其字段赋值。结构体字面量提供了一种简洁、直观的方式来创建结构体对象。结构体字面量提供了一种清晰、简洁的方式来创建和初始化结构体,特别是在需要快速创建临时结构体实例时非常有用。
2025-02-04 21:45:40
486
原创 Go语言指针的解引用和间接引用
间接引用通常指通过指针间接地引用或访问某个值。这个概念与解引用密切相关,因为你正是通过解引用来进行间接引用的。解引用是指通过指针访问它所指向的变量的值。在 Go 中,使用星号(*)来解引用一个指针。在 Go 语言中,"解引用"和"间接引用"是与指针相关的概念。是一个间接引用,我们通过指针。
2025-02-04 21:32:35
483
原创 macbook安装go语言
Cask: Homebrew 的一个扩展,主要用于安装 macOS 应用程序和大型二进制文件。使用brew命令时,一般都会通过brew search看看有哪些版本。Core: Homebrew 的核心仓库,主要包含命令行工具和库。这个的意思是说,go从cask迁移到了core中。执行后,返回了一堆内容,最下方展示。通过brew来安装go语言。可以通过关键词来搜索。
2025-01-28 23:38:21
614
原创 REPLACE INTO 和 ON DUPLICATE KEY UPDATE的区别
• 如果需要保留旧记录并仅更新部分字段,使用 ON DUPLICATE KEY UPDATE。– 结果:记录更新为 (1, ‘Alice’, 30),保留原 name。影响行数 删除行数 + 插入行数 插入为 1 行,更新为 2 行。• 如果需要完全替换旧记录,使用 REPLACE INTO。冲突处理方式 删除旧记录并插入新记录 更新冲突记录的指定列。– 结果:记录被替换为 (1, ‘Bob’, 30)自增列影响 自增列值重新生成 自增列值不变。使用场景 完全替换旧数据 部分更新旧数据。
2025-01-13 11:05:46
667
原创 为什么我说cursor是非常棒的leetcode刷题助手
对于题解中,Math.max为什么要跟0比较,理解不了, 我就会直接通过快捷键打开聊天窗口,问下这行代码。比如,我在练习leetcode 124题目。
2024-12-22 22:22:11
376
原创 为什么我说gpt是最好的leetcode刷题助手
LeetCode 上并没有一题明确以“选择排序”(Selection Sort)命名的题目,因为 LeetCode 更注重实际应用问题,而不是直接考查基础排序算法。适合选择排序的题目通常是需要你自己实现排序逻辑,而不是直接使用内置的排序函数。自从有了gpt,就可以让gpt更细致的筛选出来题型,比如排序问题,甚至只刷快速排序相关的题目。这道题虽然要求的是相对排序,但你可以使用选择排序的思想来完成部分排序逻辑。在这道题中,你需要对区间进行排序,可以通过选择排序对区间的起点进行排序。
2024-12-01 21:41:07
427
原创 git初始化和更新项目中的子模块
有一个多模块项目,某个模块下挂着submodule的子项目,这个项目刚clone下来后,需要去submodule所在的目录,执行git submodule命令,获取submodule的所有代码。其实,可以把 git submodule update --init --recursive 拆分成几个独立的命令并按照顺序依次执行。执行上述命令后,主项目的所有子模块(包括嵌套子模块)都会被初始化并更新到指定版本。废话不多说,下面一行命令解决所有问题。
2024-11-12 21:53:14
1006
原创 eclipse mat leak suspects report和 component report的区别
• 报告会生成一些“疑似泄漏对象”的集合,标记出占用内存较多的引用路径,以帮助开发者找到内存泄漏的根本原因。• 该报告会分析堆中的对象并识别占用大量内存的对象集合,特别是那些没有被及时释放、可能导致内存泄漏的对象。• 它通常用于确认内存泄漏,显示出哪些对象的生命周期与预期不符,并展示引用链,使开发者可以追溯问题的来源。• 通过展示每个组件的内存使用情况,可以帮助开发者判断是否有特定组件或类占用了过多内存,进而优化内存占用。• 更关注内存使用的分布情况,而不是具体的泄漏。侧重于识别内存泄漏的原因,而。
2024-11-11 16:09:26
1156
原创 Android Studio的新界面New UI,怎么切换回老界面
打开settings设置, Appearance & Behavior - New UI 去掉勾选即可。新版Android studio的new ui有点不太适应,想要切回来老的。
2024-11-10 22:54:54
4767
原创 rustrover打开会报Error: Invalid toolchain
如果正常输出,但在使用 RustRover 时出现“Invalid toolchain”错误,可能是由于 RustRover 工具链配置有问题或路径指向错误。
2024-08-13 17:06:17
1473
原创 rust接受字符串作为参数的两种写法
str:适用于不需要修改字符串并且你不需要拥有所有权的情况。String:适用于需要修改字符串或需要拥有所有权的情况。选择哪种类型取决于你是否需要修改字符串以及你如何管理字符串的所有权。
2024-07-23 19:48:45
427
原创 mysql5.7升级到mysql8.0遇坑
mysql5.7升级到mysql8.0发现生产环境服务会报错Error querying database. Cause: java.sql.SQLSyntaxErrorException: FUNCTION GeomFromText does not exist在MySQL 8.0中,`GeomFromText`函数已经被弃用,取而代之的是`ST_GeomFromText`函数。你可以将你的查询从`GeomFromText`更新为`ST_GeomFromText`。这是因为MySQL 8.0引入
2024-06-20 12:54:23
921
原创 添加webpack.config.js配置
所以,在前面的博客中,我们初始化了一个空的项目,当执行webpack打包时,需要先手动在src目录下创建一个index.js文件,这样在执行npm run build后,在dist的目录下生成了一个main.js文件,这个也验证了上面零配置打包规则的第1点和第2点。上述配置,指定了入口文件,同时指定了dist文件夹下输出的文件名为bundle.js,执行npm run build,会看到在dist文件下多了一个bundle.js文件。
2024-05-20 13:00:30
742
原创 使用npm script运行webpack
Npm Script 还有一个重要的功能是能运行安装到项目目录里的 node_modules 里的可执行模块,比如之前安装了webpack,是无法直接在项目根目录下通过命令 webpack 去执行 Webpack 构建的,直接执行webpack命令会报错 command not found: webpack。可以向 npm 脚本传递参数,这些参数可以通过 `--` 分隔符传递给脚本,比如 npm run test -- --verbose,这将向test脚本传递 --verbose参数。
2024-05-07 11:30:39
662
2
原创 初始化创建一个webpack项目
执行npm install webpack webpack-cli --save-dev,安装webpack和webpack-cli。git的变更里,package.json中可以看到新增了两个依赖项目,安装了webpack和webpack-cli。git变更里,新增了一个package.json的文件,初始化了一个空的npm项目,将这个改动提交commit。安装后的webpack,实际上是放到了node_module下,可以执行以下命令来验证webpack的版本。执行nvm use 19.2.0。
2024-05-05 12:23:53
612
原创 使用nvm管理node版本
那我应该是用brew install node执行安装的,可以使用brew info node来查看node是否有安装过,显示如下有一行Installed说明,node是使用brew install安装的,版本是19.2.0,跟我上面执行node -v输出的版本是一致的,那这样就好办了,直接执行brew uninstall。npm:是 node.js 默认的包管理系统(用 JavaScript 编写的),在安装的 node 的时候,npm 也会跟着一起安装,管理 node 中的第三方插件。
2024-05-05 00:21:20
1113
原创 mysql使用st_distance_sphere函数报错Incorrect arguments to st_distance_sphere
st_distance_sphere函数报错
2023-09-01 09:45:10
2153
原创 浅谈Java中的观察者模式
如果要自己编码实现,我们通常定义一个主题接口(Subject)和一个观察者接口(Observer)。主题接口中包含注册观察者、移除观察者和通知观察者的方法,而观察者接口中则定义了更新状态的方法。考虑到实现简单点,我们假定有一个广播类,这个广播类实际上就是一个主题Subject,有多个听众收听这个广播,这里每个听众就是一个观察者Observer。观察者模式是软件开发中常用的一种设计模式,它通过定义一对多的依赖关系,使得一个对象(主题)的状态变化可以通知多个其他对象(观察者)。写一个测试类来测试结果。
2023-08-24 13:14:32
842
原创 macbook golang版本升级
如何查看mac上是通过pkg安装包安装的go语言,还是通过brew install go安装的go语言。不同的安装方式,升级go语言版本方式会有不同。
2023-07-19 22:59:05
11152
原创 OpenStreetMap实战-准备postgresql
个人推荐,下载Postgres.app的方式,这样后续不需要了,直接在应用程序中,将这个Postgres.app删除掉即可。打开Postgres的应用程序,默认是创建了一个postgres的数据库,双击这个数据会出现命令行。而后我们进入到这个osm的数据命令行中,执行创建拓展的命令。下载后,直接双击dmg文件,将app拖入到应用程序中即可。我是macos的系统,点击macos链接,进入下载页。在命令行中创建一个名为osm的数据库。下载postgresql。
2023-05-25 11:05:51
313
原创 OpenStreetMap初探与实战
OpenStreetMap(OSM)是一个由志愿者创建并维护的免费和开源的地图数据库。其目的是为全球任何人提供可自由使用、编辑和分发的地图数据。OpenStreetMap数据库中的地理要素包括道路、建筑、河流、森林、山脉、公共设施等。由于OpenStreetMap是开放的平台,任何人都可以添加新的地理信息,从而使其不断发展和更新。OpenStreetMap已经成为诸如Google地图等商业地图的一个重要替代品。
2023-05-24 22:40:22
4563
原创 macbook brew install 经常遇见 No such file or directory @ rb_sysopen
安装php : brew install php ,在执行过程中经常报错,比如以下==> Installing php dependency: openldap==> Pouring openldap-2.5.8.arm64_monterey.bottle.tar.gzError: No such file or directory @ rb_sysopen - /Users/li.xiang/Library/Caches/Homebrew/downloads/93f5617b379ba
2022-05-15 21:52:47
4983
2
原创 使用Semaphore 实现一个简单的限流器
# 使用Semaphore 实现一个简单的限流器## java apiJava的api中,提供了semaphore这个线程同步的辅助类,用来控制同时访问共享资源的线程数量。Semaphore提供的主要方法如下:void acquire():获取一个信号量,在获得信号量前线程会一直阻塞。void release():释放一个信号量。int availablePermits(): 返回当前可用的信号量数。boolean hasQueuedThreads(): 查询是否有等待获取信号量
2021-10-27 23:01:39
324
转载 springboot mock controller和log4j 单元测试实践1
本文重点将讲述如何在单元测试中,mock controller的请求,测试controller请求,同时顺带着讲解如何在单测中测试代码日志中输出的内容。首先,新建spring boot的项目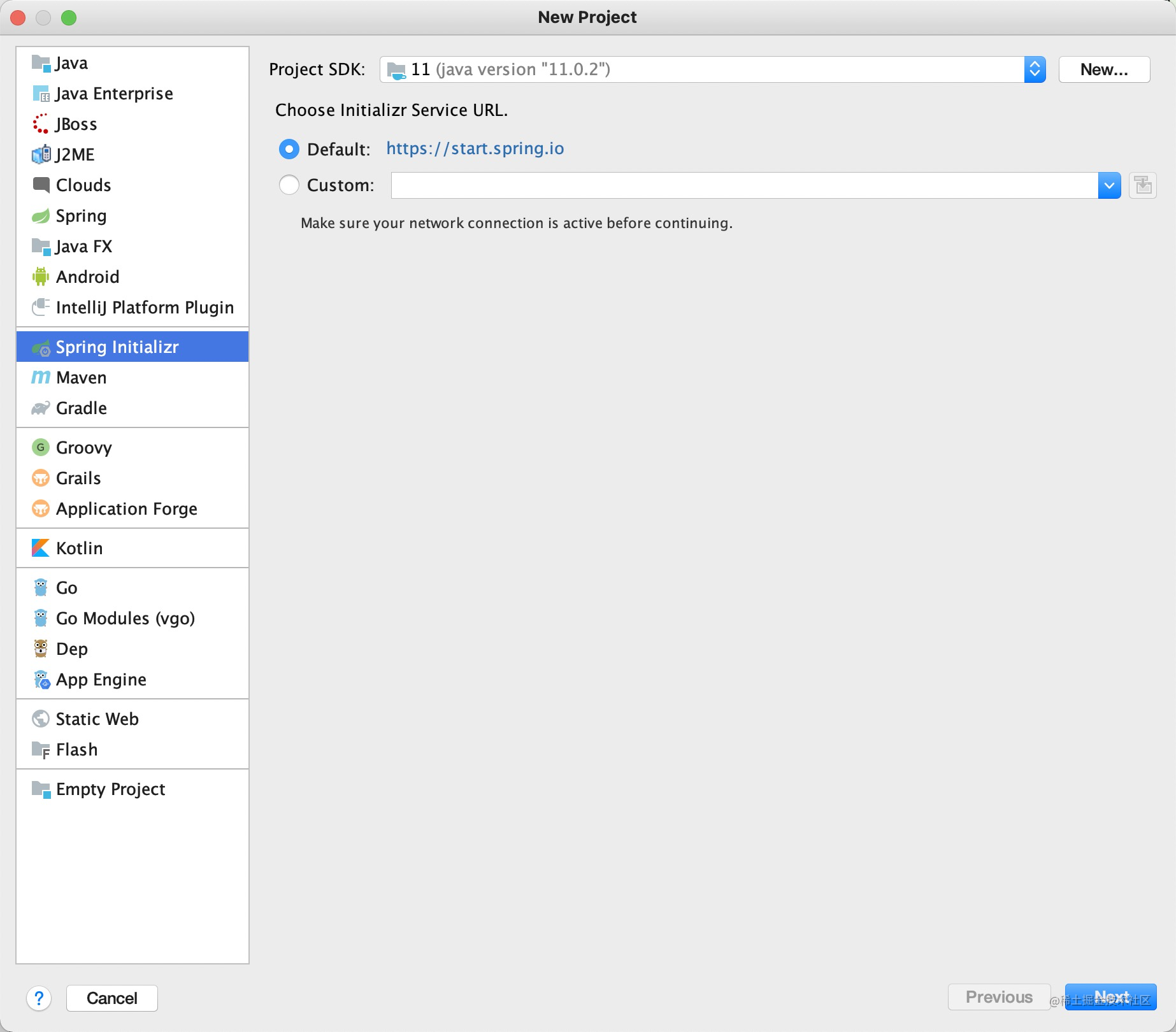和Rust包管理器(cargo)rustup-init安装完成后,会提示如下关闭shell窗口重新打开,或者直接当前shell下执行下面语句,即可生效source $HOME/.cargo/env...
2021-08-30 20:15:18
793
原创 推送同一份代码到两个不同的仓库
想把同一份代码推送到两个不同的仓库,比如推送到github和gitee。有一份代码放在了github上,也想把这份代码同时推送到gitee上。有两种方式:一种方式gitremote add gitee git@gitee.com:csucoderlee/leetcode.git在推送代码的时候,再额外git push gitee xxxxx 就可以了。这么搞,其实比较麻烦,每次提交的时候都需要push两次git push origin xxxxx / git push ...
2021-07-18 21:01:57
1446
中文版本的JavaTM Platform Standard Ed. 6API规范
2014-03-25
zend studio11.0.2全过程破解文件
2014-11-09
numpy 1.8 for win7 64bit
2015-06-02
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人