







Mysql架构与Mysql执行流程
前言
该内容来源于咕泡学院-青山老师的mysql性能优化课程,基于老师的笔记和课程,自己进行了一些总结。
整体架构
从整体架构上来说,mysql可以分为三层(连接层、服务层、存储引擎层)
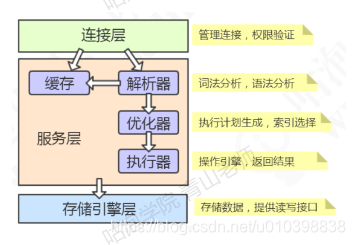

连接层
查询连接数
可以通过查询语句:
show global status like "%thread%";
查看当前mysql的连接数(客户端没发起一个连接或一个会话,mysql服务端都会创建一个线程来处理)
| 变量名称 | 含义 |
|---|---|
| Threads_cached | 缓存的线程连接数 |
| Threads_connected | 当前打开的连接数 |
| Threads_created | 为处理连接创建的线程数 |
| Threads_running | 非睡眠状态的连接数,通常指并发连接数 |
连接超时
可以通过查询语句:
-- 交互式的连接的超时时间
show global VARIABLES like "interactive_timeout";
-- jdbc等程序连接的超时时间
show global VARIABLES like "wait_timeout";
最大连接数
可以通过查询语句:
show global VARIABLES like "max_connections";
mysql默认最大连接数是151,最大可以手动设置到100000。
服务(server)层
缓存
mysql在服务层,有一个查询用的缓存,但是命中缓存的限制比较严格,默认是不开启的,实际使用效果并不好。我们实际生产环境中,更多的是依赖于ORM框架的缓存(例如mybatis的一级二级缓存)或者独立的缓存服务器(redis),所以这里不深入讨论mysql的查询缓存。
语法解析器和预处理
该模块的作用是对sql语句进行处理。
词法解析
首先,对于一条sql语句,需要通过词法解析,根据构词规则,将他打碎成一个个的单词。
语法解析
然后,根据定义的语法规则,将上面解析出来的单词组成语法短语,最后生成一颗语法解析树。
预处理器
经过词法解析和语法解析,mysql只能确定sql语句的各种语法是正常的,但是没法检测某个表或某个字段是否存在。而预处理器可以根据一些Mysql规则进一步检查解析树是否合法,例如,这里将检查数据表和数据列是否存在,还会解析名字和别名,看看它们是否有歧义。
mysql的预处理技术
参考:mysql的预处理技术
查询优化与查询执行计划
当得到正确的解析树后,需要mysql的查询优化器模块来进行优化,因为这里要考虑到是否可以使用索引,关联查询时以哪张表作为基准表的效率更高等等因素。一条sql语句可以有多个执行方式,虽然最终得到的结果肯定是一致的,但是从性能上来说可能差距很大。所以优化器模块是必不可少的。
而mysql里的优化器,是基于开销(cost)的优化器,会根据解析树生成不同的执行计划,再从这多种执行计划中,根据cost,选择cost最小的计划来执行。
执行引擎
当获得最优的执行计划后,需要交给执行引擎来处理。它会调用存储引擎提供的统一api来进行数据的处理。
存储引擎
我们的表数据最终是存储在存储引擎的,实际上也是转换成文件存储在磁盘上的,当然,没有看上去那么简单。
分类
mysql的存储引擎,根据官方文档,可以分为InnoDB、MyISAM、Memory、CSV、Archive、Blackhole、NDB、Merge、Federated、Example这10种,我们重点关注前三种。
InnoDB:mysql默认的存储引擎。是一个事务安全的mysql存储引擎,支持行级锁
| 存储引擎 | 特点 | 适用场景 |
|---|---|---|
| InnoDB | 支持事务,支持外键,支持行锁和表锁,读写并发 | 适用经常更新的表,存在并发读写或有事务处理的系统 |
| MyISAM | 支持表锁,不支持事务,插入和查询较快 | 适合只读的业务场景 |
| Memory | 所有数据存储在RAM内存汇总,读写速度快 | 适合用作临时表 |
更新操作的流程
上面是mysql中基于查询操作的流程,那么更新操作有什么不同呢?
前面的基本流程和查询操作是一致的,都要经过解析器、优化器的处理,最后交给执行器。差别在于对符合条件的数据的操作。
InnoDB总体架构
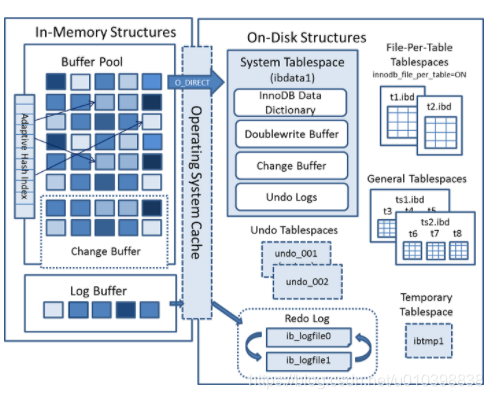
缓存池buffer pool
存储引擎想要操作数据,首先要获取数据,需要先从磁盘上将数据加载到内存中。
InnoDB设定了一个存储引擎从磁盘读取数据到内存的最小的单位,叫做页,默认大小为16KB。
而为了提高效率,使用了缓存,将读取过的数据也缓存起来。
InnoDB中有一个内存的缓冲区,Buffer Pool。当进行更新操作的时候,是先将更新数据写入到buffer pool,而不是直接写入磁盘(因为磁盘IO操作实在是太慢了),但是这时候会出现内存的数据也和磁盘数据不一致的问题,该数据页变成了脏页。这就需要专门的后台线程将脏页的数据写入到磁盘了,这个操作叫做刷脏。
Redo log
按照缓存的概念,数据就不是实时的了,那么如果在脏页数据还没有完成刷脏的时候,数据库挂了,那么内存中的数据就会直接丢失,但是又还没写入磁盘,最终造成数据丢失了。
这个时候就需要redo log出场了。
redo log是一个日志文件,会记录所有对数据页的修改操作。如果数据库挂了,当重启后,会检查redo log,从该文件里来回复数据(实现crash-safe)。
redo log的存储位置:/var/lib/mysql/目录下的ib_logfile0和ib_logfile1,默认2个文件,每个文件默认初始大小就是48M。
小知识点:既然最终都要写入磁盘,为什么要先记录到redo log中,再写入磁盘,而不是直接写入磁盘?
因为写入到redo log的过程是在后面追加数据,是顺序IO,而直接写入到数据在磁盘中的存放位置,是随机IO。顺序IO的性能远大于随机IO。
redo log的特点
1、独属于InnoDB的特性
2、只记录在某个数据页上做了什么修改,而不关注更新之后的数据状态,所以是一种物理日志
3、文件大小固定,写满后,会触发buffer pool到磁盘的刷脏同步操作。
Undo log
undo log记录了事务发生之前的数据状态,如果更新数据时出现异常,可以根据undo log进行回滚操作,保证了数据的原子性。
undo log记录的是反向的操作,比如对于一个insert操作,undo log 会记录一个delete操作,如果insert 操作成功,但是同一个事务里的其它操作失败了,则需要删掉这个insert进去的数据,就相当于执行undo log对应的delete操作。所以这是一个逻辑日志。
更新流程
以一个sql语句为例:
假设有一张表user,有一行记录为name=刘德华,对应主键id=1
update user set name = '张学友' where id = 1;
简化流程如下:
1、开启事务,从buffer pool或磁盘(data file)中根据id=1获取到包含这条数据的数据页,返回给server层的执行引擎
2、执行引擎将该数据页的这一条数据进行修改,将name改为张学友
3、记录 name=刘德华 到undo log
4、记录 name=张学友 到redo log
5、调用存储引擎接口,将修改后的数据页记录到buffer pool
6、提交事务
内存结构
InnoDB的内存结构主要包括buffer pool和log buffer。
buffer pool
buffer pool 包括了Buffer pool、change buffer和adaptive hash index。
buffer pool
buffer pool 缓存了页面信息,包括数据页和索引页。默认大小为128M。
buffer pool使用了LRU算法来管理缓冲池的数据页。
LRU
常规的LRU算法,是使用map和链表实现的。实际的数据存储在链表中,而map中存储的是key及对应的链表中数据所在节点的地址值。
当有新数据加入的时候,会放到链表的head处,长期不用的冷数据会从tail淘汰掉。
但InnoDB并没有直接使用这个算法,因为InnoDB中存在预读取机制,当读取了一个区的数据达到一定量,会默认将该区的其它数据也读取出来(方便后面调用,但是后面不一定会真的调用),那么如果直接使用这个LRU算法,就存在问题,会把不知道最终是否会被用到的数据插入到head,如果数据页的数据较大,会把真正的热点数据从head挤掉,甚至淘汰掉,显然不合理。
所以InnoDB对该算法进行了优化改造,将链表分成冷区和热区两部分,靠近head的5/8是热区,靠近tail的3/8是冷区。
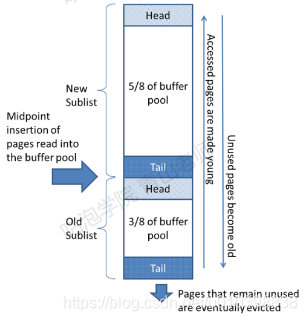
当有新数据加入到buffer pool的时候,一开始先放入到冷区的head,这样如果预读取到的数据最终没有被使用,则不会挤掉热区数据,且会慢慢从tail淘汰掉。这里还有个时间窗口的设定,如果数据放入冷区的head,然后再一秒钟之内,这个数据又被访问到了,那么该数据不会被移动到热区的head,而是会保持不动,这是为了避免全表扫描或预读的数据污染到真正的热数据。
对于热区,还有一个特殊的优化,因为对LRU的链表的操作从并发的角度来考虑是一定要加锁的,这会影响性能。InnoDB为了减小资源竞争对性能的影响,将热区的靠近head的1/4区域,设定为不需要移动,即该区域内的数据,即使被访问了,也不会移动到头部,而是保持不变。这是为什么呢?因为从需要实现的逻辑上来说,LRU只是为了保证数据能够快速获取热点数据,至于数据在不在head,其实没有什么大关系,反正在热区的前1/4了,一般都是不会被淘汰的了,就没必要移动到head了。
change buffer 写缓冲
当数据页不是唯一索引,并且业务逻辑上不存在数据重复的问题,那么就不要从磁盘加载索引页检查数据的唯一性了。这种情况下,会把修改操作记录在内存的缓冲池中,即change buffer中,从而提升更新操作的执行速度。
当访问这个数据页,或者通过后台线程、或者数据库关机重启、或者redo log写满的时候,会触发将change buffer 记录刷到数据页的操作。
redo log buffer
redo log buffer 主要用于缓冲redo log,默认为16M,作用也是为了节省磁盘IO。
磁盘结构
InnoDb的磁盘结构可以分为5大类。
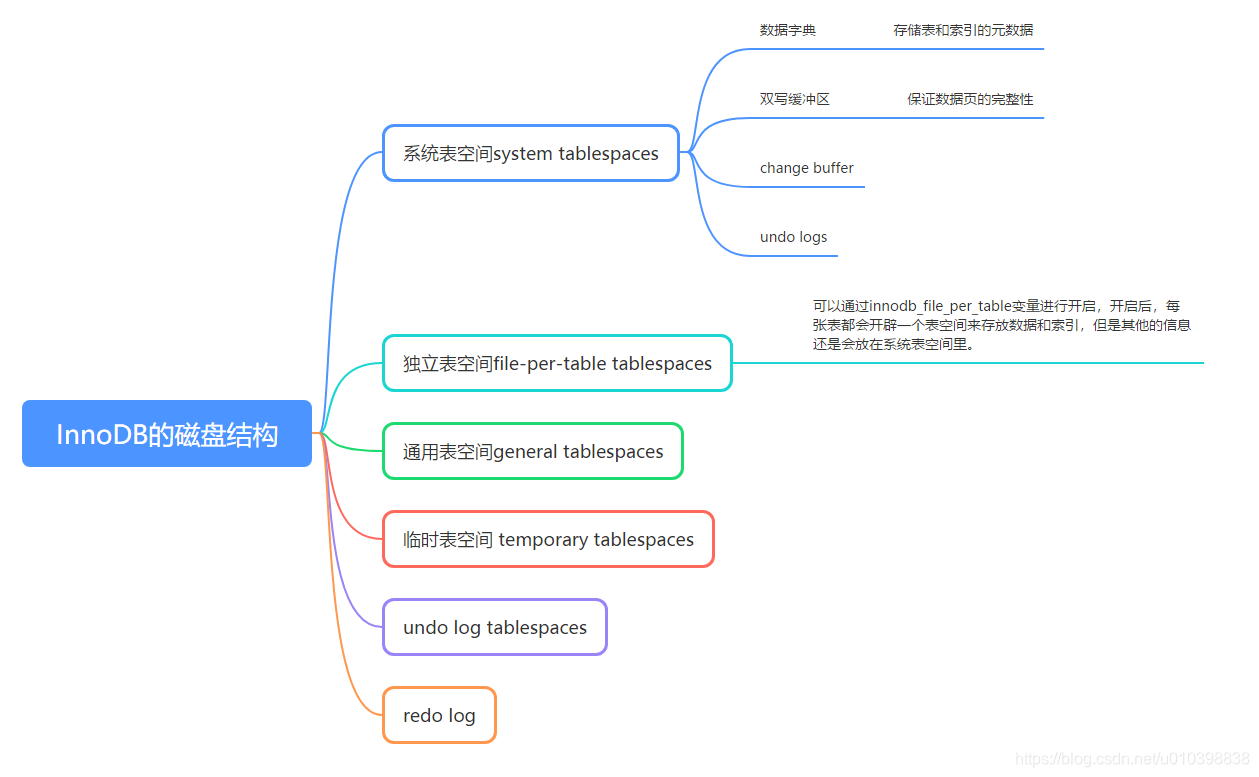
这里我们重点关注双写缓冲区。
双写缓冲区 double write buffer
问:为什么需要这个缓冲区?
答:因为Mysql的buffer的一页大小是16KB的,但是操作系统的文件系统的一页一般是4KB,那么mysql的一页数据写入到文件系统需要写到4个页里面。
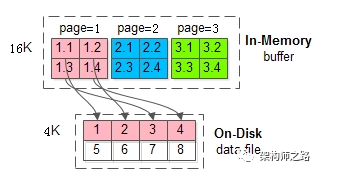
当在写入的时候,数据库宕机重启或者断电了,会造成“数据页损坏”,也叫“部分写失效”。这种破坏是redo log无法恢复的,因为原始的数据页已经损坏了。而redo log能够恢复的是页数据正常,且redo log正常的情况。
所以,这种情况就要靠双写缓冲区来解决了。看图
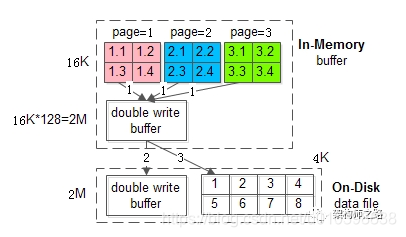
双写缓冲区在内存和磁盘上分别有一块缓冲区,当有数据要刷盘时,过程如下:
第一步:页数据先从buffer pool拷贝到DWB的内存里;
第二步:DWB的内存里,会先刷到DWB的磁盘上的DWB里;
第三步:DWB的内存里,再刷到数据磁盘存储上;
那么DWB是如何解决“数据页损坏”的问题呢?
1、假设步骤2的过程中断电,那么磁盘上的数据页都还是正常的。
2、假设步骤3的过程中断点,那么磁盘上的DWB里仍旧存储着完整数据,只要从磁盘上同步到数据页即可。














 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









