







转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/28863651
概述
记得在很早之前,我有写过一篇文章Android高效加载大图、多图解决方案,有效避免程序OOM,这篇文章是翻译自Android Doc的,其中防止多图OOM的核心解决思路就是使用LruCache技术。但LruCache只是管理了内存中图片的存储与释放,如果图片从内存中被移除的话,那么又需要从网络上重新加载一次图片,这显然非常耗时。对此,Google又提供了一套硬盘缓存的解决方案:DiskLruCache(非Google官方编写,但获得官方认证)。只可惜,Android Doc中并没有对DiskLruCache的用法给出详细的说明,而网上关于DiskLruCache的资料也少之又少,因此今天我准备专门写一篇博客来详细讲解DiskLruCache的用法,以及分析它的工作原理,这应该也是目前网上关于DiskLruCache最详细的资料了。
那么我们先来看一下有哪些应用程序已经使用了DiskLruCache技术。在我所接触的应用范围里,Dropbox、Twitter、网易新闻等都是使用DiskLruCache来进行硬盘缓存的,其中Dropbox和Twitter大多数人应该都没用过,那么我们就从大家最熟悉的网易新闻开始着手分析,来对DiskLruCache有一个最初的认识吧。
初探
相信所有人都知道,网易新闻中的数据都是从网络上获取的,包括了很多的新闻内容和新闻图片,如下图所示:
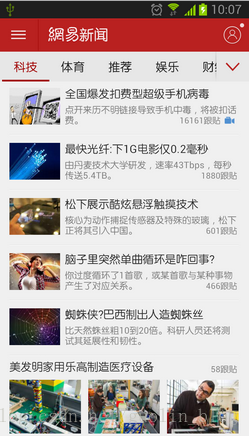
但是不知道大家有没有发现,这些内容和图片在从网络上获取到之后都会存入到本地缓存中,因此即使手机在没有网络的情况下依然能够加载出以前浏览过的新闻。而使用的缓存技术不用多说,自然是DiskLruCache了,那么首先第一个问题,这些数据都被缓存在了手机的什么位置呢?
其实DiskLruCache并没有限制数据的缓存位置,可以自由地进行设定,但是通常情况下多数应用程序都会将缓存的位置选择为 /sdcard/Android/data/<application package>/cache 这个路径。选择在这个位置有两点好处:第一,这是存储在SD卡上的,因此即使缓存再多的数据也不会对手机的内置存储空间有任何影响,只要SD卡空间足够就行。第二,这个路径被Android系统认定为应用程序的缓存路径,当程序被卸载的时候,这里的数据也会一起被清除掉,这样就不会出现删除程序之后手机上还有很多残留数据的问题。
那么这里还是以网易新闻为例,它的客户端的包名是com.netease.newsreader.activity,因此数据缓存地址就应该是 /sdcard/Android/data/com.netease.newsreader.activity/cache ,我们进入到这个目录中看一下,结果如下图所示:
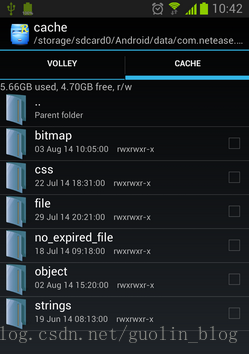
可以看到有很多个文件夹,因为网易新闻对多种类型的数据都进行了缓存,这里简单起见我们只分析图片缓存就好,所以进入到bitmap文件夹当中。然后你将会看到一堆文件名很长的文件,这些文件命名没有任何规则,完全看不懂是什么意思,但如果你一直向下滚动,将会看到一个名为journal的文件,如下图所示:
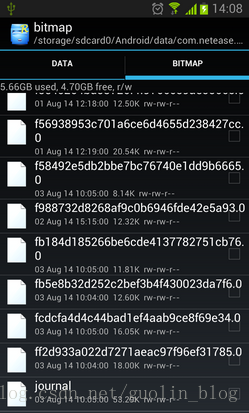
那么这些文件到底都是什么呢?看到这里相信有些朋友已经是一头雾水了,这里我简单解释一下。上面那些文件名很长的文件就是一张张缓存的图片,每个文件都对应着一张图片,而journal文件是DiskLruCache的一个日志文件,程序对每张图片的操作记录都存放在这个文件中,基本上看到journal这个文件就标志着该程序使用DiskLruCache技术了。
下载
好了,对DiskLruCache有了最初的认识之后,下面我们来学习一下DiskLruCache的用法吧。由于DiskLruCache并不是由Google官方编写的,所以这个类并没有被包含在Android API当中,我们需要将这个类从网上下载下来,然后手动添加到项目当中。DiskLruCache的源码在Google Source上,地址如下:
如果Google Source打不开的话,也可以点击这里下载DiskLruCache的源码。下载好了源码之后,只需要在项目中新建一个libcore.io包,然后将DiskLruCache.java文件复制到这个包中即可。
打开缓存
这样的话我们就把准备工作做好了,下面看一下DiskLruCache到底该如何使用。首先你要知道,DiskLruCache是不能new出实例的,如果我们要创建一个DiskLruCache的实例,则需要调用它的open()方法,接口如下所示:
- public static DiskLruCache open(File directory, int appVersion, int valueCount, long maxSize)
其中缓存地址前面已经说过了,通常都会存放在 /sdcard/Android/data/<application package>/cache 这个路径下面,但同时我们又需要考虑如果这个手机没有SD卡,或者SD正好被移除了的情况,因此比较优秀的程序都会专门写一个方法来获取缓存地址,如下所示:
- public File getDiskCacheDir(Context context, String uniqueName) {
- String cachePath;
- if (Environment.MEDIA_MOUNTED.equals(Environment.getExternalStorageState())
- || !Environment.isExternalStorageRemovable()) {
- cachePath = context.getExternalCacheDir().getPath();
- } else {
- cachePath = context.getCacheDir().getPath();
- }
- return new File(cachePath + File.separator + uniqueName);
- }
接着又将获取到的路径和一个uniqueName进行拼接,作为最终的缓存路径返回。那么这个uniqueName又是什么呢?其实这就是为了对不同类型的数据进行区分而设定的一个唯一值,比如说在网易新闻缓存路径下看到的bitmap、object等文件夹。
接着是应用程序版本号,我们可以使用如下代码简单地获取到当前应用程序的版本号:
- public int getAppVersion(Context context) {
- try {
- PackageInfo info = context.getPackageManager().getPackageInfo(context.getPackageName(), 0);
- return info.versionCode;
- } catch (NameNotFoundException e) {
- e.printStackTrace();
- }
- return 1;
- }
后面两个参数就没什么需要解释的了,第三个参数传1,第四个参数通常传入10M的大小就够了,这个可以根据自身的情况进行调节。
因此,一个非常标准的open()方法就可以这样写:
- DiskLruCache mDiskLruCache = null;
- try {
- File cacheDir = getDiskCacheDir(context, "bitmap");
- if (!cacheDir.exists()) {
- cacheDir.mkdirs();
- }
- mDiskLruCache = DiskLruCache.open(cacheDir, getAppVersion(context), 1, 10 * 1024 * 1024);
- } catch (IOException e) {
- e.printStackTrace();
- }
有了DiskLruCache的实例之后,我们就可以对缓存的数据进行操作了,操作类型主要包括写入、访问、移除等,我们一个个进行学习。
写入缓存
先来看写入,比如说现在有一张图片,地址是https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg,那么为了将这张图片下载下来,就可以这样写:
- private boolean downloadUrlToStream(String urlString, OutputStream outputStream) {
- HttpURLConnection urlConnection = null;
- BufferedOutputStream out = null;
- BufferedInputStream in = null;
- try {
- final URL url = new URL(urlString);
- urlConnection = (HttpURLConnection) url.openConnection();
- in = new BufferedInputStream(urlConnection.getInputStream(), 8 * 1024);
- out = new BufferedOutputStream(outputStream, 8 * 1024);
- int b;
- while ((b = in.read()) != -1) {
- out.write(b);
- }
- return true;
- } catch (final IOException e) {
- e.printStackTrace();
- } finally {
- if (urlConnection != null) {
- urlConnection.disconnect();
- }
- try {
- if (out != null) {
- out.close();
- }
- if (in != null) {
- in.close();
- }
- } catch (final IOException e) {
- e.printStackTrace();
- }
- }
- return false;
- }
- public Editor edit(String key) throws IOException
那么我们就写一个方法用来将字符串进行MD5编码,代码如下所示:
- public String hashKeyForDisk(String key) {
- String cacheKey;
- try {
- final MessageDigest mDigest = MessageDigest.getInstance("MD5");
- mDigest.update(key.getBytes());
- cacheKey = bytesToHexString(mDigest.digest());
- } catch (NoSuchAlgorithmException e) {
- cacheKey = String.valueOf(key.hashCode());
- }
- return cacheKey;
- }
- private String bytesToHexString(byte[] bytes) {
- StringBuilder sb = new StringBuilder();
- for (int i = 0; i < bytes.length; i++) {
- String hex = Integer.toHexString(0xFF & bytes[i]);
- if (hex.length() == 1) {
- sb.append('0');
- }
- sb.append(hex);
- }
- return sb.toString();
- }
因此,现在就可以这样写来得到一个DiskLruCache.Editor的实例:
- String imageUrl = "https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
- String key = hashKeyForDisk(imageUrl);
- DiskLruCache.Editor editor = mDiskLruCache.edit(key);
因此,一次完整写入操作的代码如下所示:
- new Thread(new Runnable() {
- @Override
- public void run() {
- try {
- String imageUrl = "https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
- String key = hashKeyForDisk(imageUrl);
- DiskLruCache.Editor editor = mDiskLruCache.edit(key);
- if (editor != null) {
- OutputStream outputStream = editor.newOutputStream(0);
- if (downloadUrlToStream(imageUrl, outputStream)) {
- editor.commit();
- } else {
- editor.abort();
- }
- }
- mDiskLruCache.flush();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }).start();
现在的话缓存应该是已经成功写入了,我们进入到SD卡上的缓存目录里看一下,如下图所示:
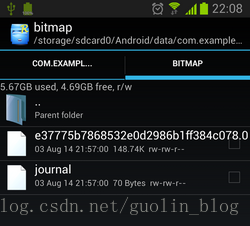
可以看到,这里有一个文件名很长的文件,和一个journal文件,那个文件名很长的文件自然就是缓存的图片了,因为是使用了MD5编码来进行命名的。
读取缓存
缓存已经写入成功之后,接下来我们就该学习一下如何读取了。读取的方法要比写入简单一些,主要是借助DiskLruCache的get()方法实现的,接口如下所示:
- public synchronized Snapshot get(String key) throws IOException
- String imageUrl = "https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
- String key = hashKeyForDisk(imageUrl);
- DiskLruCache.Snapshot snapShot = mDiskLruCache.get(key);
- try {
- String imageUrl = "https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
- String key = hashKeyForDisk(imageUrl);
- DiskLruCache.Snapshot snapShot = mDiskLruCache.get(key);
- if (snapShot != null) {
- InputStream is = snapShot.getInputStream(0);
- Bitmap bitmap = BitmapFactory.decodeStream(is);
- mImage.setImageBitmap(bitmap);
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
我们使用了BitmapFactory的decodeStream()方法将文件流解析成Bitmap对象,然后把它设置到ImageView当中。如果运行一下程序,将会看到如下效果:
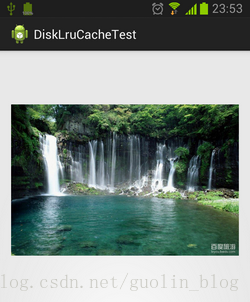
OK,图片已经成功显示出来了。注意这是我们从本地缓存中加载的,而不是从网络上加载的,因此即使在你手机没有联网的情况下,这张图片仍然可以显示出来。
移除缓存
学习完了写入缓存和读取缓存的方法之后,最难的两个操作你就都已经掌握了,那么接下来要学习的移除缓存对你来说也一定非常轻松了。移除缓存主要是借助DiskLruCache的remove()方法实现的,接口如下所示:
- public synchronized boolean remove(String key) throws IOException
- try {
- String imageUrl = "https://img-my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
- String key = hashKeyForDisk(imageUrl);
- mDiskLruCache.remove(key);
- } catch (IOException e) {
- e.printStackTrace();
- }
其它API
除了写入缓存、读取缓存、移除缓存之外,DiskLruCache还提供了另外一些比较常用的API,我们简单学习一下。
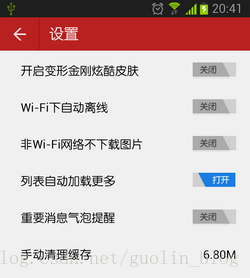
1. size()
这个方法会返回当前缓存路径下所有缓存数据的总字节数,以byte为单位,如果应用程序中需要在界面上显示当前缓存数据的总大小,就可以通过调用这个方法计算出来。比如网易新闻中就有这样一个功能,如下图所示:
2.flush()
这个方法用于将内存中的操作记录同步到日志文件(也就是journal文件)当中。这个方法非常重要,因为DiskLruCache能够正常工作的前提就是要依赖于journal文件中的内容。前面在讲解写入缓存操作的时候我有调用过一次这个方法,但其实并不是每次写入缓存都要调用一次flush()方法的,频繁地调用并不会带来任何好处,只会额外增加同步journal文件的时间。比较标准的做法就是在Activity的onPause()方法中去调用一次flush()方法就可以了。
3.close()
这个方法用于将DiskLruCache关闭掉,是和open()方法对应的一个方法。关闭掉了之后就不能再调用DiskLruCache中任何操作缓存数据的方法,通常只应该在Activity的onDestroy()方法中去调用close()方法。
4.delete()
这个方法用于将所有的缓存数据全部删除,比如说网易新闻中的那个手动清理缓存功能,其实只需要调用一下DiskLruCache的delete()方法就可以实现了。
解读journal
前面已经提到过,DiskLruCache能够正常工作的前提就是要依赖于journal文件中的内容,因此,能够读懂journal文件对于我们理解DiskLruCache的工作原理有着非常重要的作用。那么journal文件中的内容到底是什么样的呢?我们来打开瞧一瞧吧,如下图所示:
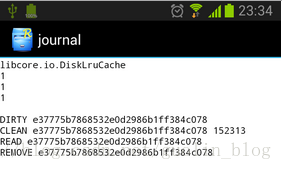
由于现在只缓存了一张图片,所以journal中并没有几行日志,我们一行行进行分析。第一行是个固定的字符串“libcore.io.DiskLruCache”,标志着我们使用的是DiskLruCache技术。第二行是DiskLruCache的版本号,这个值是恒为1的。第三行是应用程序的版本号,我们在open()方法里传入的版本号是什么这里就会显示什么。第四行是valueCount,这个值也是在open()方法中传入的,通常情况下都为1。第五行是一个空行。前五行也被称为journal文件的头,这部分内容还是比较好理解的,但是接下来的部分就要稍微动点脑筋了。
第六行是以一个DIRTY前缀开始的,后面紧跟着缓存图片的key。通常我们看到DIRTY这个字样都不代表着什么好事情,意味着这是一条脏数据。没错,每当我们调用一次DiskLruCache的edit()方法时,都会向journal文件中写入一条DIRTY记录,表示我们正准备写入一条缓存数据,但不知结果如何。然后调用commit()方法表示写入缓存成功,这时会向journal中写入一条CLEAN记录,意味着这条“脏”数据被“洗干净了”,调用abort()方法表示写入缓存失败,这时会向journal中写入一条REMOVE记录。也就是说,每一行DIRTY的key,后面都应该有一行对应的CLEAN或者REMOVE的记录,否则这条数据就是“脏”的,会被自动删除掉。
如果你足够细心的话应该还会注意到,第七行的那条记录,除了CLEAN前缀和key之外,后面还有一个152313,这是什么意思呢?其实,DiskLruCache会在每一行CLEAN记录的最后加上该条缓存数据的大小,以字节为单位。152313也就是我们缓存的那张图片的字节数了,换算出来大概是148.74K,和缓存图片刚刚好一样大,如下图所示:
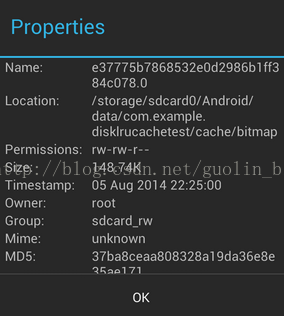
前面我们所学的size()方法可以获取到当前缓存路径下所有缓存数据的总字节数,其实它的工作原理就是把journal文件中所有CLEAN记录的字节数相加,求出的总合再把它返回而已。
除了DIRTY、CLEAN、REMOVE之外,还有一种前缀是READ的记录,这个就非常简单了,每当我们调用get()方法去读取一条缓存数据时,就会向journal文件中写入一条READ记录。因此,像网易新闻这种图片和数据量都非常大的程序,journal文件中就可能会有大量的READ记录。
那么你可能会担心了,如果我不停频繁操作的话,就会不断地向journal文件中写入数据,那这样journal文件岂不是会越来越大?这倒不必担心,DiskLruCache中使用了一个redundantOpCount变量来记录用户操作的次数,每执行一次写入、读取或移除缓存的操作,这个变量值都会加1,当变量值达到2000的时候就会触发重构journal的事件,这时会自动把journal中一些多余的、不必要的记录全部清除掉,保证journal文件的大小始终保持在一个合理的范围内。















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









