







百度云盘下载(解压安装):链接:https://pan.baidu.com/s/1dFTpMhj 密码:jp1g
百度云盘下载(源码):链接:https://pan.baidu.com/s/1ht81j7Y 密码:5yaa
官网下载:http://archive.apache.org/dist/hadoop/core/hadoop-2.3.0/
安装需要配置HADOOP_HOME
如果运行nutch出现
InjectorJob: starting at 2018-01-22 16:29:38
InjectorJob: Injecting urlDir: urls
InjectorJob: Using class org.apache.gora.mongodb.store.MongoStore as the Gora storage class.
InjectorJob: java.lang.NullPointerException
at java.lang.ProcessBuilder.start(Unknown Source)
at org.apache.hadoop.util.Shell.runCommand(Shell.java:482)
at org.apache.hadoop.util.Shell.run(Shell.java:455)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:702)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:791)
at org.apache.hadoop.util.Shell.execCommand(Shell.java:774)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:646)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:434)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:281)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:125)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:348)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1285)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1282)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1282)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1303)
at org.apache.nutch.util.NutchJob.waitForCompletion(NutchJob.java:115)
at org.apache.nutch.crawl.InjectorJob.run(InjectorJob.java:231)
at org.apache.nutch.crawl.InjectorJob.inject(InjectorJob.java:252)
at org.apache.nutch.crawl.InjectorJob.run(InjectorJob.java:276)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.nutch.dispatch.JobManager.run(JobManager.java:22)
at org.apache.nutch.dispatch.JobManager.main(JobManager.java:50)
下载以下文件:
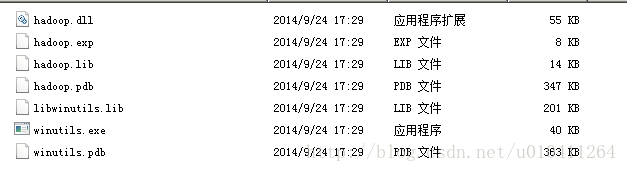
(不要问我为什么加这些文件)
下载地址:链接:https://pan.baidu.com/s/1i6UJLNB 密码:7d9j
将下载的文件加入到hadoop\bin路径下
如果还是出错,那么就是路径出错了,nutch内部引用hadoop不对,请尝试将hadoop-2.3.0改成hadoop-2.3















 6674
6674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











