









可能很多初学者和我一样,一开始以为只要在分区表上创建的索引就是分区索引,其实不然,索引是否分区和表是否分区没有必然的关系,表分区索引可以分区也可以不分区,甚至表不分区索引也可以分区(但很少会这么定义),因此分区索引比分区表要复杂的多。
分区索引主要分为本地分区索引和全局分区索引,本地索引又分为前缀索引和非前缀索引,本文主要探讨它们的区别。
本地分区索引
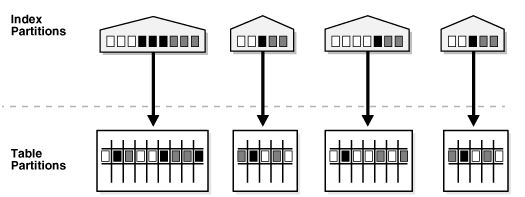
本地分区索引具有如下基本特征:
1. 本地索引一定是分区索引,分区键等同于表的分区键,分区数等同于表的分区说,总之,本地索引的分区机制和表的分区机制一模一样。
2. 如果本地索引的索引列以分区键为第一列,则称为本地前缀分区索引。
3. 如果本地索引的索引列不是以分区键为第一列,或者不包含分区键列,则称为本地非前缀分区索引。
4. 前缀和非前缀都可以支持索引分区消除,前提是查询的条件中包含索引分区键。
5. 本地索引只支持分区内的唯一性,无法支持表上的唯一性,因此如果要用本地索引去给表做唯一性约束,则约束中必须要包括分区键列。
6. 本地分区索引是对单个分区的,每个分区索引只指向一个表分区,全局索引则不然,一个分区索引能指向n个表分区,同时,一个表分区,也可能指向n个索引分区,对分区表中的某个分区做truncate或者move,shrink等,可能会影响到n个全局索引分区,正因为这点,本地分区索引具有更高的可用性。
7. 位图索引只能为本地分区索引。
8. 本地索引多应用于OLAP环境中。
本地前缀分区索引
本地前缀分区索引是指分区键是索引列的第一列,假设分区表的定义如下:
create table t
( id number,
year number,
month number
) partitioned by range (year)
( partition p_2009 values less than (2010)
partition p_2010 values less than (2011),
partition p_2011 values less than (2012),
partition p_2012 values less than (2013)
) 则以下的两个索引都是前缀分区索引:
create index i1 on t(year) local;
create index i2 on t(year,month) local;本地非前缀分区索引
本地非前缀索引是指索引列中不包含分区键,或分区键不在索引列的第一列,下面的两个索引是本地非前缀分区索引:
create index i3 on (id,year) local;
create index i4 on (month) local;全局分区索引
全局分区索引正好和本地索引相反,即索引分区和表分区不完全一样,它具有如下特征:
1.全局索引的分区键、分区数和表的分区键、分区数可能都不相同,表和全局索引的分区机制不一样。
2.全局索引可以分区,也可以不分区,全局索引必须是前缀索引,即全局索引的索引列必须是以索引分区键作为其前几列。
3.全局分区索引的索引条目可能指向若干个分区,因此,对于全局分区索引,即使只截断一个分区中的数据,都需要rebulid若干个分区甚至是整个索引。
4.全局分区索引多应用于OLTP系统中。
5.全局分区索引只按范围或者哈希分区,哈希分区是10g以后才支持。
6.oracle9i以后对分区表做move或者truncate的时可以用update global indexes语句来同步更新全局分区索引,用消耗一定资源来换取高度的可用性。
下面的例子是在分区表上定义一个不分区的全局索引:
create index i5 on t(id);
create index i6 on t(id) global;
下面的例子定义了一个全局分区索引,它的分区键和表的不一样:
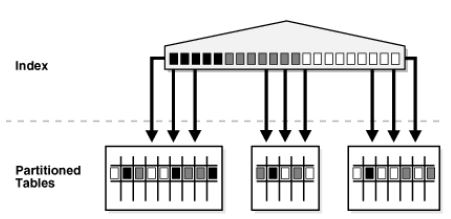
create index i7 on t (month)
global partition by range (month)
( partition p_before_july values less than (7),
partition p_after_july values less than (13)
);其示意图如下:

本地分区VS全局索引
全局索引正好相反,可维护性差,比如删除表中一个分区,索引失效,需要rebuild,但它的索引访问性能比本地分区索引要好。因此比较适合OLTP系统。















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









