







CPU的概念
CPU是英文Central Processing Unit的缩写,一般是指中央处理器,它是一块超大规模的集成电路,是一台计算机的运算核心和控制核心。它的功能主要是解释计算机指令以及处理计算机软件中的数据。CPU由运算器、控制器和寄存器及实现它们之间联系的数据、控制及状态的总线构成。CPU的能力高低直接影响了整个电脑的运行速度。
CPU依靠指令计算和控制系统,每款CPU在设计时就规定了一系列与其硬件电路相配合的指令系统。指令的强弱也是CPU的重要指标,指令集是提高微处理器效率的最有效工具之一。CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码。它把指令分解成一系列的微操作,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行
CPU的性能指标
cpu的性能指标有如下图几种。
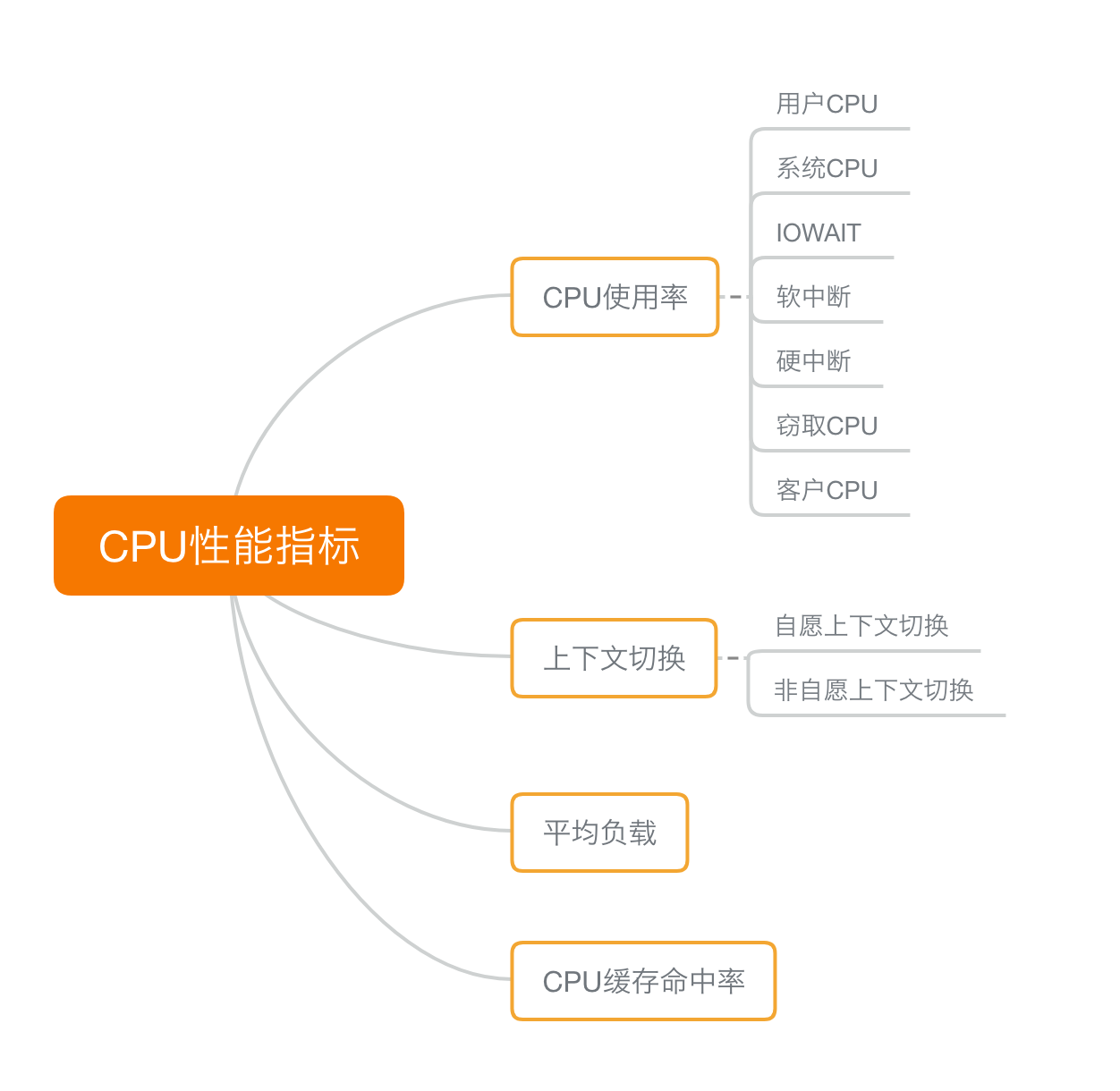
CPU 使用率
描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
-
用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
-
系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
-
等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
-
软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
-
除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载(Load Average)
也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
进程上下文切换
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。包括:
-
无法获取资源而导致的自愿上下文切换;
-
被系统强制调度导致的非自愿上下文切换。
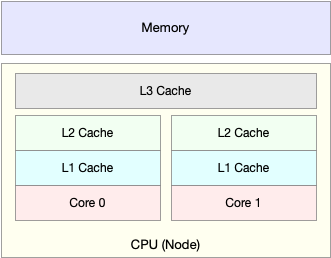
CPU 缓存的命中率
由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。如下图,从 L1 到 L3,三级缓存的大小依次增大,相应的,性能依次降低(当然比内存还是好得多)。而它们的命中率,衡量的是 CPU 缓存的复用情况,命中率越高,则表示性能越好
CPU性能指标的查询工具
当知道要查询的CPU指标时候,查询工具
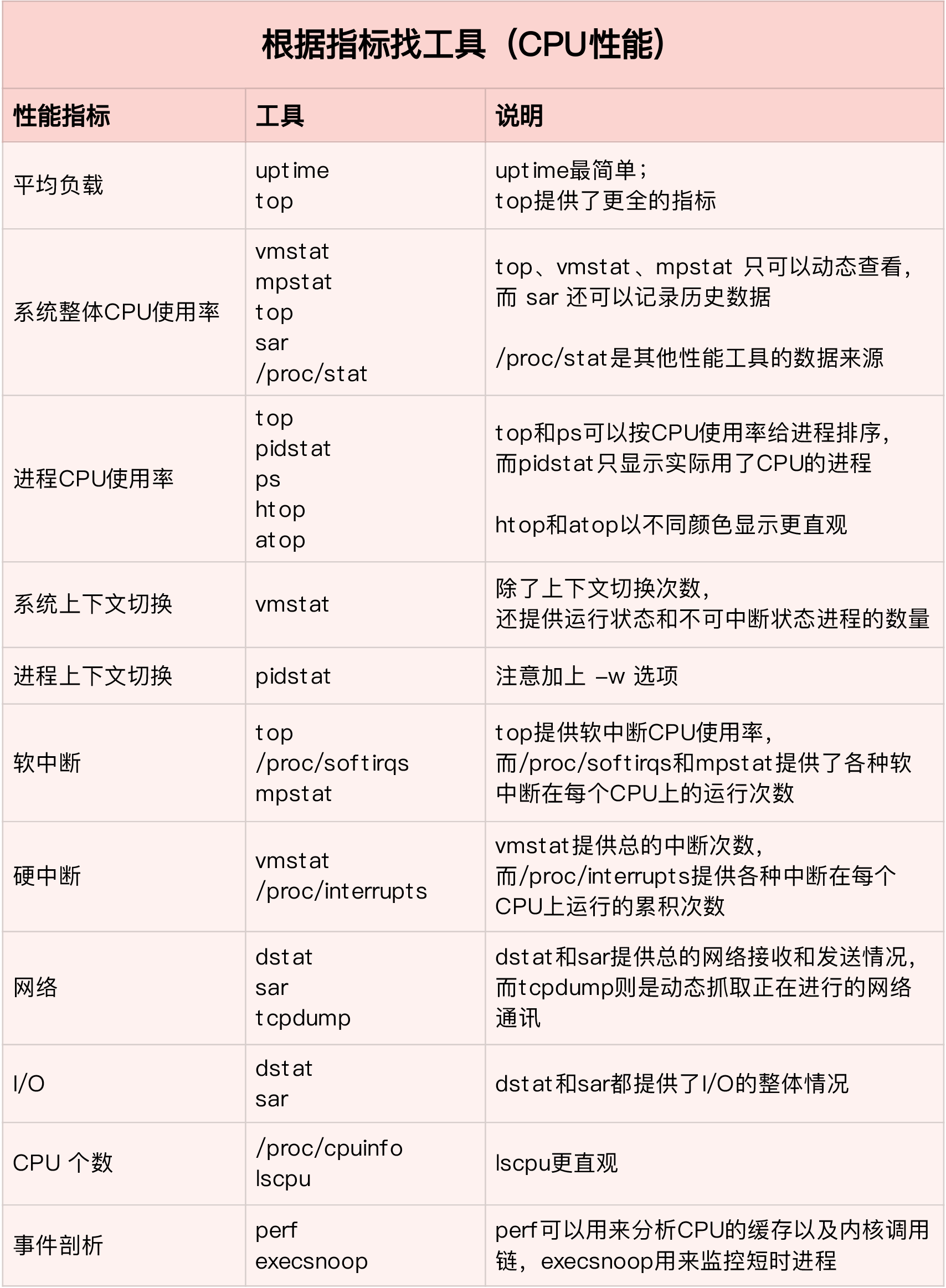
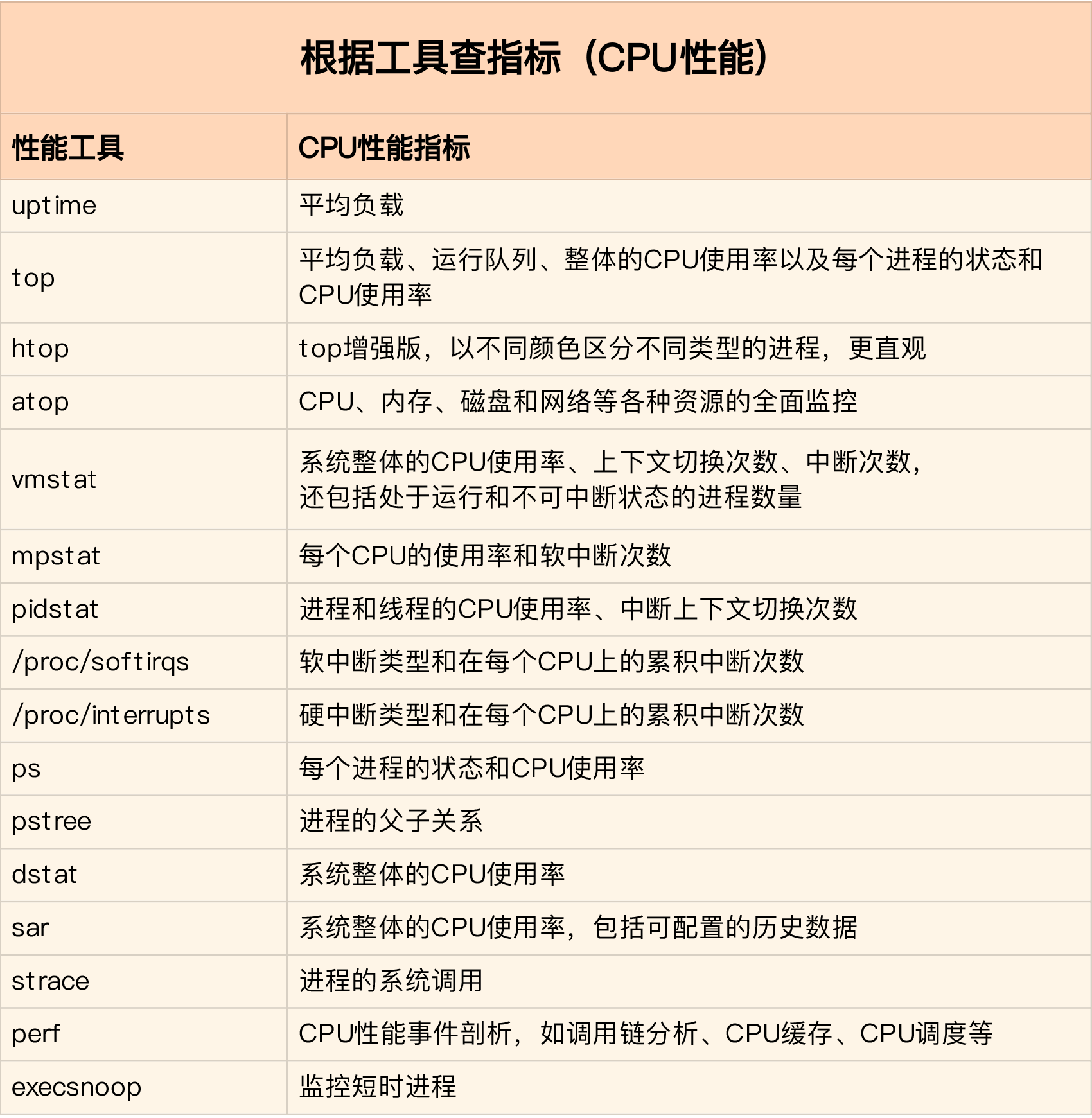
常用的: top, vmstat, pidstat
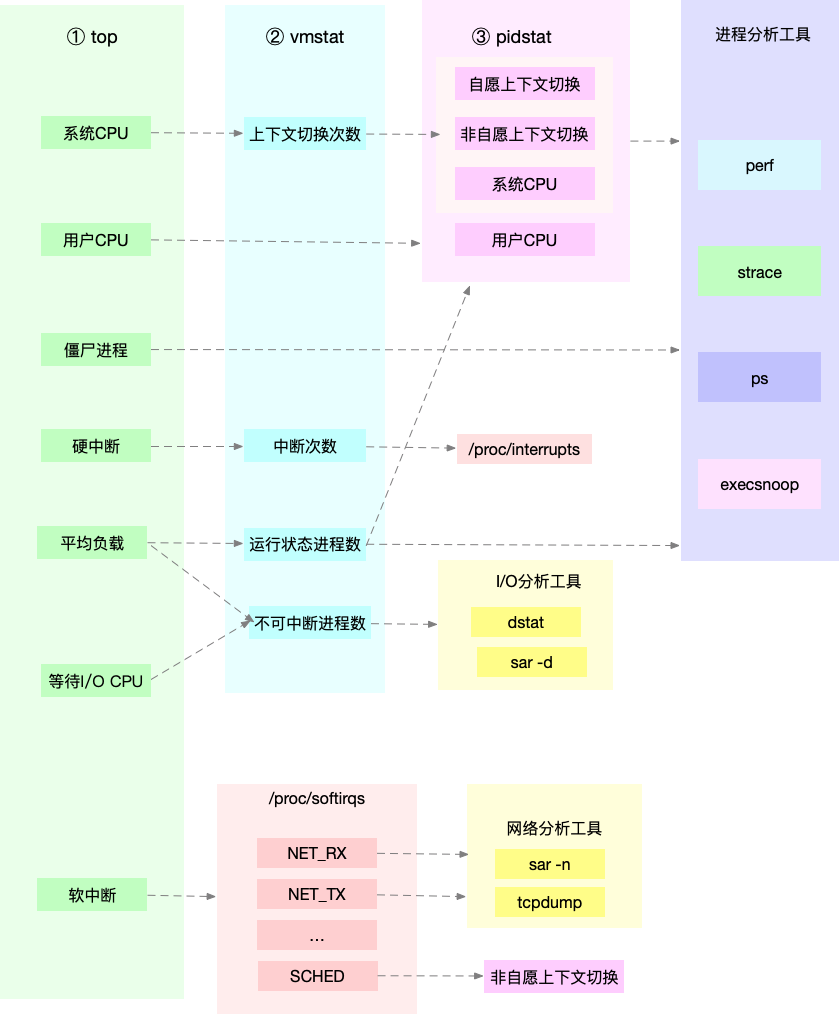
通过这张图你可以发现,这三个命令,几乎包含了所有重要的 CPU 性能指标,比如:
-
从 top 的输出可以得到各种 CPU 使用率以及僵尸进程和平均负载等信息。
-
从 vmstat 的输出可以得到上下文切换次数、中断次数、运行状态和不可中断状态的进程数。
-
从 pidstat 的输出可以得到进程的用户 CPU 使用率、系统 CPU 使用率、以及自愿上下文切换和非自愿上下文切换情况。
这三个工具输出的很多指标是相互关联的,所以,用虚线表示了它们的关联关系,举几个例子可能会更容易理解。
第一个例子,pidstat 输出的进程用户 CPU 使用率升高,会导致 top 输出的用户 CPU 使用率升高。所以,当发现 top 输出的用户 CPU 使用率有问题时,可以跟 pidstat 的输出做对比,观察是否是某个进程导致的问题。而找出导致性能问题的进程后,就要用进程分析工具来分析进程的行为,比如使用 strace 分析系统调用情况,以及使用 perf 分析调用链中各级函数的执行情况。
第二个例子,top 输出的平均负载升高,可以跟 vmstat 输出的运行状态和不可中断状态的进程数做对比,观察是哪种进程导致的负载升高。
-
如果是不可中断进程数增多了,那么就需要作 I/O 的分析,也就是用 dstat 或 sar 等工具,进一步分析 I/O 的情况。
-
如果是运行状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运行状态的到底是什么进程,然后再用进程分析工具,做进一步分析。
最后一个例子,当发现 top 输出的软中断 CPU 使用率升高时,可以查看 /proc/softirqs 文件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。比如,发现是网络接收中断导致的问题,那就可以继续用网络分析工具 sar 和 tcpdump 来分析。
(一) CPU的占用是怎么产生的?为什么不同OS下的CPU利用率不同?
操作系统是用来调度任务(进程)和管理外围设备的系统,操作系统采用自己的进程调度策略将进程调度到CPU上运行,占用了CPU时间片,由此产生了CPU的占用。
为什么不同OS下的CPU利用率不同呢?有以下几方面的原因:
1. 不同的操作系统管理外围设备的方法、进程调度的算法、内存管理的算法等等有差异,因此同一个应用在不同的OS下的CPU消耗可能不一样。
2. 同一个应用安装在不同的设备上(包括硬件+OS+系统软件),并不能保证参数都是一样的。即使是同一个版本的OS,由于应用和OS的参数配置太多,可能某个参数配的不一样,相差很大的CPU利用率都是可能的。举几个例子:
-
一个采用文件系统,另一个采用裸设备
-
一个设置了CPU折叠,一个没设置
-
一个写磁盘是按照4K写入,另一个按照64K写入,那么diskbusy的百分比相差很大,CPU的繁忙程度也略有不同
3. 不同OS上,CPU数读工具的统计方法可能不一样,即使是同一个OS,不同的CPU读数工具的统计方法也可能不一样。
有人提到,“Linux on Power的处理器利用率比AIX的处理器利用率相比少得多”,这个现象并不奇怪。即使都是AIX,同一个应用在AIX61上和AIX71上,CPU利用率也不同,我做过实验,AIX71相比AIX61做了一定的优化。
(二) 为什么多核CPU的利用率分布不均匀
问题:在AIX系统,利用topas查看时,发现只有一个CPU的利用率很高,其他的core利用率几乎为零,怎么可以调整参数,使得其他的core的利用率增大?在Linux下的问题同样的疑问。
从应用角度,很可能应用是个单进程,不能分到多个CPU上运行。如果已经是个多进程应用,那就可能并发数设置为1了,需调大并发数后才能分配到多个核运行。
从操作系统层面,系统会把进程调度到上一次使用的CPU,以避免进程的上下文切换。一个CPU干的好好的,当然不会调到其他CPU,不然上下文切换代价大。因此,如果压力不是很大的时候,当然是只有一个core的利用率较大,而其他core是闲置状态。
(三) CPU利用率的正常使用范围是多少?
一般来说,生产运行环境中CPU 70%会报警。有些谨慎、保守的单位,CPU超过40%就着手扩容了。
但并不是说CPU一超过70%就一定是异常,对于夜间的批处理业务,可能更多的是期望它尽多占用CPU、尽快处理完成,以免影响第二天的开门。
(四) CPU利用率当中的Sys%高是什么原因?
如果系统态占比比较大,一般有以下几类原因:
1. 为了追求效率,减少用户态到系统态的转换,把用户态的function改到系统态,例如:一些驱动程序,以显卡驱动最为常见
2. 系统有IO问题
参考
https://www.infoq.cn/article/5jjidopx12rwwvgx_h9j
https://www.cnblogs.com/kongzhongqijing/articles/8916844.html



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











