







vision_transformer顾名思义,是将自然语言处理中的Transformer的思想应用在图像分类中,将一张图像切成不同的patch之后作为sequence,使用Transformer来实现图像分类。
本文主要是梳理vis-transformer的模型结构,以及图像数据在各种算子operator下的shape变化。方便理解和进一步开发。
原论文的模型结构示意图:
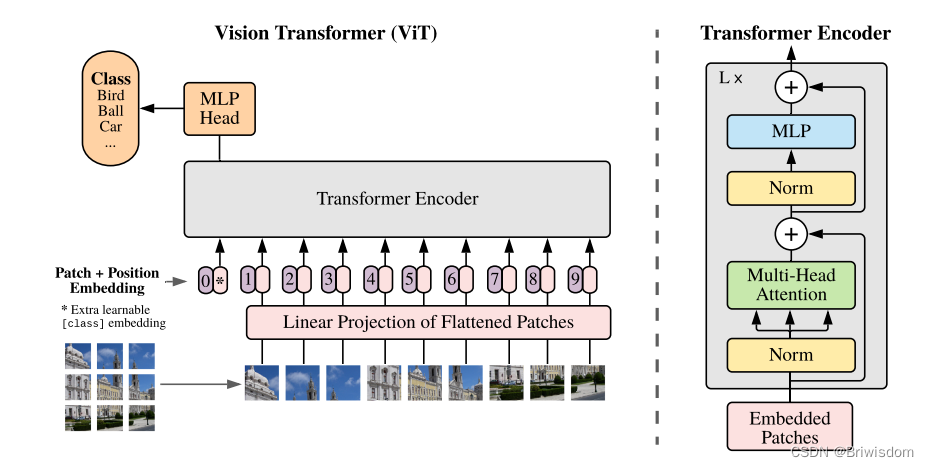
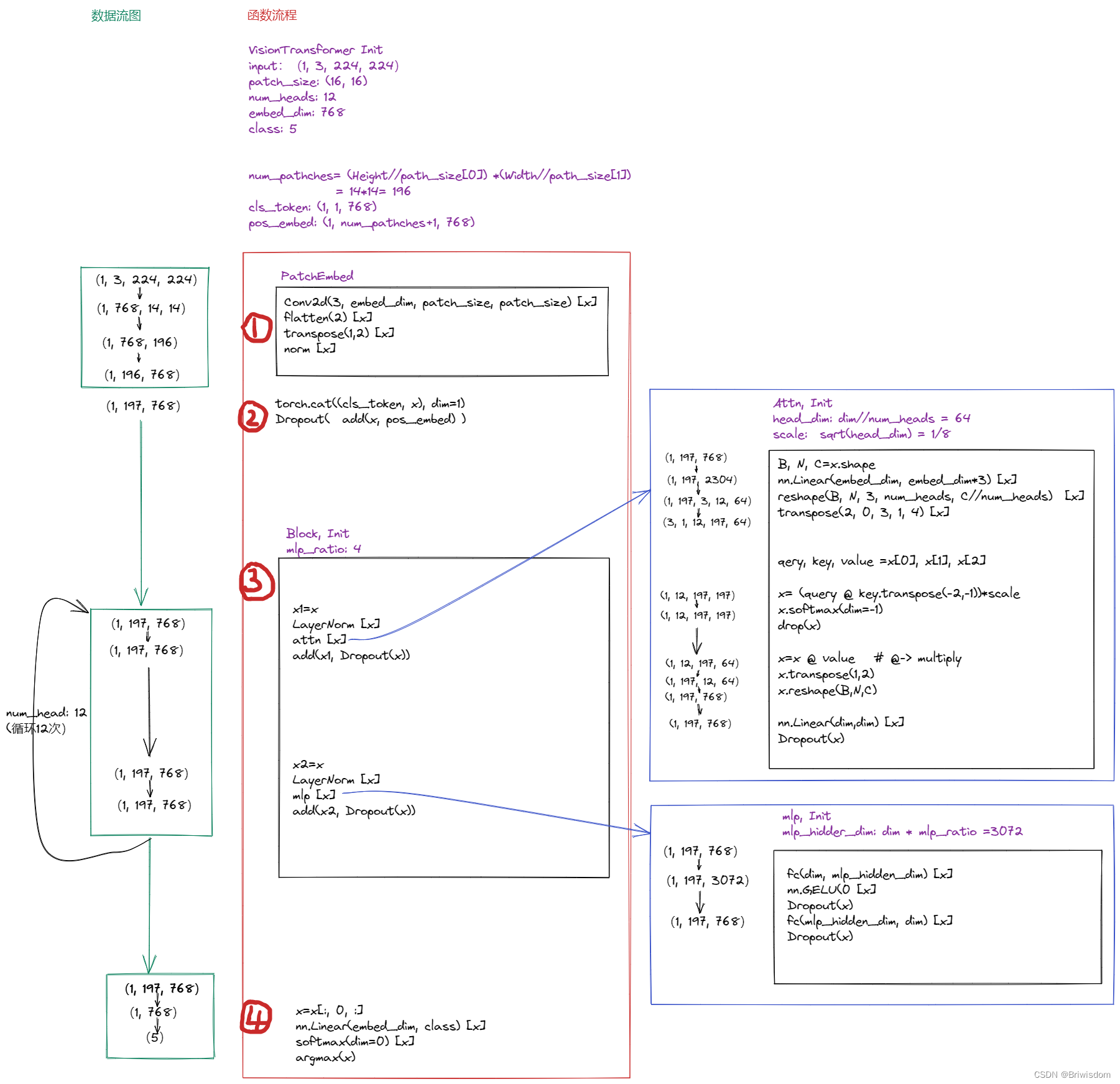
第一步:
将(1, 3, 224, 224)的图像,通过Conv2d, kernel=(16,16),stride=(16,16),变成(1,196,768)的数组形状,其中196可以理解为将原图像的H,W分别安装16切成的14*14个patches,768是定义的输出通道数。
第二步:
然后将类别的cls_token与卷积后的feature数据进行concat, 再add上pos的编码信息。
第三步:
transformer的结构,需要循环执行12次。每个transformer block包括attention和MLP编码模块。
attention模块
数据先进行layerNorm操作,然后通过一个Liner将输入x的channel维度扩3倍,再通过reshape和transpose操作分别把这三个维度给query, key, value这三个变量
query和key进行点乘,再乘以scale, 进行softmax,
然后softmax的结果和value进行点乘,进行reshape,transpose回数据进来时候的尺寸
最后通过一个Linear算子,将数据和第一步进来的数据进行点加,开始传递给MLP模块
MLP模块
进来后数据首先进行一个layerNorm操作,然后通过两个FC(全连接层,也是linear算子)将数据channel进行先扩大在缩回的操作,中间使用GELU激活函数。
最后一个FC层后的数据和MLP刚进来的数据进行点加,将数据传进下一步骤。
第四步:
最后的过程,先提取第一步插入的第0个通道的cls_token,即为类别的编码信息
通过Linear将类别信息定位到具体的class_num上,再通过经典的softmax, argmax得到图像的分类结果。
Excalidraw | Hand-drawn look & feel • Collaborative • Secure



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











