









 本文介绍了如何使用败者树优化大文件的外部排序过程,以减少I/O操作。败者树是一种自下而上的筛选方式,用于在多个数据中快速找出最小值,并在更新数据后迅速重新确定最小值。文章详细阐述了败者树的建立和调整过程,并提供了相关代码实现。
本文介绍了如何使用败者树优化大文件的外部排序过程,以减少I/O操作。败者树是一种自下而上的筛选方式,用于在多个数据中快速找出最小值,并在更新数据后迅速重新确定最小值。文章详细阐述了败者树的建立和调整过程,并提供了相关代码实现。
对于大文件的排序,常规思路便是:将大文件问个成 n 个小文件,分别对这些小文件利用内部排序(快速排序、堆排序等)算法排成有序。然后再对这些文件进行两两归并,直至归并成一个大的有序文件。
这样归并的趟数比较多,读写文件的 I/O 次数就比较多。相对于内存中的运算,对文件的读写操作是特别费时间的。显然一次性归并多个文件而不是两个会大大减少归并的趟数,从而减少对文件的读写操作。
如何一次性归并多个文件?败者树。
不同于堆排序自上而下的筛选方式,败者树是自下而上的。败者树的所有节点,存储的都是待筛选数据的位置(诸如数组下表等等)。而且,除了根节点用于存储最终的胜者之外,其余节点存储的都是作比较的两者中的败者。
类似堆排序,败者树的实现同样需要两个过程:建立和调整。这里把败者树成为 loserTree,数据列表为 dataArray,显然,loserTree 存储的是数组dataArray的下标。败者树的功能便是,从 n 个节点中选出关键字最小的节点, 然后当新的节点替换掉最小关键字的节点之后,能够有效地重新筛选出新的最小关键字节点。
调整:对败者树的每个节点(非根节点),令由叶子节点传递过来的“胜者”同该节点存储的下标对应的 dataArray 的关键字作比较,“败者”的下标留在该节点,胜者继续向上,同该节点的父节点重复同样的动作,直至最后的胜者,将其下表存储在 loserTree[0] 的位置。
建立:这里令败者树的每个节点都存储 dataArray 的0号下标,同时为 i = 0, 1, 2, ....., n 的 dataArray[i] 关键字赋值为 i - n. 然后对败者树的每一节点逐一进行调整。
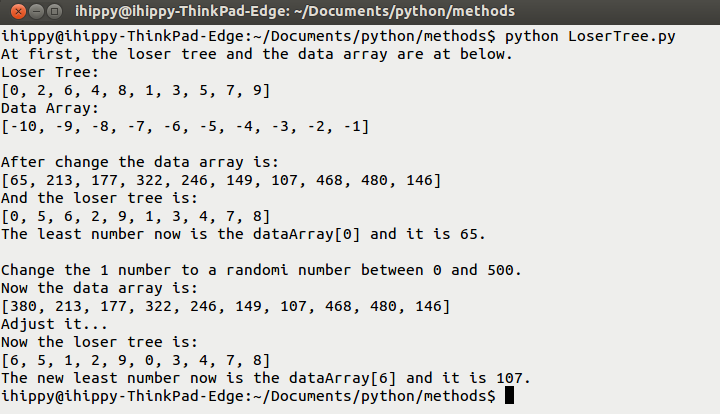
完整代码:
#!/usr/bin/python
# Filename: LoserTree.py
def createLoserTree(loserTree, dataArray, n):
'''Initialize the loser tree and data array by the branch number n.
Assign all members of the loser tree and the data array.
And adjust the to a real 'Loser Tree'.'''
for i in range(n):
loserTree.append(0)
dataArray.append(i-n)
for i in range(n):
adjust(loserTree, dataArray, n, n-1-i)
# Unlike the HeapSort, the LoserTree adjust from bottom to top.
def adjust(loserTree, dataArray, n, s):
t = (s + n) / 2
while t > 0:
if dataArray[s] > dataArray[loserTree[t]]:
s, loserTree[t] = loserTree[t], s
t /= 2
loserTree[0] = s
#---------------------------Test------------------------------
if __name__ == '__main__':
import random
a = 10
loserTree = []
dataArray = []
createLoserTree(loserTree, dataArray, a)
print 'At first, the loser tree and the data array are at below.'
print 'Loser Tree:'
print loserTree
print 'Data Array:'
print dataArray
# Adjust the loserTree every time change one item of the dataArray.
for i in range(a):
dataArray[i] = random.randint(0, 500)
adjust(loserTree, dataArray, a, i)
print '\nAfter change the data array is:'
print dataArray
print 'And the loser tree is:'
print loserTree
print 'The least number now is the dataArray[%d] and it is %d.' % (loserTree[0], dataArray[loserTree[0]])
print '\nChange the %d number to a randomi number \
between 0 and 500.' % (loserTree[0]+1)
dataArray[loserTree[0]] = random.randint(0,500)
print 'Now the data array is:'
print dataArray
print 'Adjust it...'
adjust(loserTree, dataArray, a, loserTree[0])
print 'Now the loser tree is:'
print loserTree
print 'The new least number now is the dataArray[%d] and it is %d.' % (loserTree[0], dataArray[loserTree[0]])

















 2382
2382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









