








我们知道普通的线性数据结构如链表,数组等,遍历方式单一,都是从头到尾遍历就行,但树这种数据结构却不一样,我们从一个节点出发,下一个节点却有可能遇到多个分支路径,所以为了遍历树的全部节点,我们需要借助一个临时容器,通常是栈这种数据结构,来存储当遇到多个分叉路径时的,存暂时没走的其他路径,等走过的路径遍历完之后,再继续返回到原来没走的路径进行遍历,这一点不论在递归中的遍历还是迭代中的遍历中其实都是一样的,只不过递归方法的栈是隐式的,而我们自己迭代遍历的栈需要显式的声明。
树遍历的思想总体分为两种思路:
(一)深度优先遍历(Depth-First-Search=>DFS)
1,前序遍历(Pre-order Traversal)
遍历规则:先根节点,然后左子树,最后右子树
2,中序遍历(In-order Traversal)
遍历规则:先左子树,然后根节点,最后右子树
3,后序遍历(Post-order Traversal)
遍历规则:先左子树,然后右子树,最后根节点。
(二)广度优先遍历(Breadth-First-Search=>BFS)
1, 层级遍历(level order traversal)
我们来看一个普通二叉树:

这里简单说下为什么拿二叉树举例,这是因为在实际开发中,我们使用的树形结构里面,二叉树是最为广泛的,比如AVL树,红黑树,堆等,这些是非常高效的面向内存的数据结构,比较易于理解和使用。 除了二叉树之外,这里还有面向磁盘的多叉树数据结构B树,通常用在文件系统或者数据库系统的索引。 我们来看一下二叉树的代码表示:
class Node<T>{
public T data;
public Node<T> left;
public Node<T> right;
}

上面的代码是一个基于泛型的二叉树模型表示,代表二叉树的一个节点,里面有一个data字段,用来保存该节点的数据,此外还有左孩子节点和右孩子节点,分别表示二叉树的两个分支,这里我要提醒各位一下,虽然在代码上表示是单独的左右两个节点,但是正确的理解策略是把这两个节点,分别看成是一棵树,也即左子树和右子树,理解这一点至关重要,因为这是一个嵌套的定义,每个左,右子节点下面都可能还有无数个类似于这个节点本身的结构,所以不能将其仅仅看成一个节点,而应该看成是一颗树,只有这样思考,才能更加容易的看清二叉树的遍历策略,否则有可能陷入误区,导致很难理解各种遍历策略,尤其还是在递归的遍历的算法中。
递归虽然可以写出非常简洁的代码,但是想要理解和看清递归的本质可不是一件容易事。
在二叉树的深度遍历的三种遍历策略里面,有一个共性,那就是无论哪种策略,都是先遍历左子树,然后再右子树。
这里以中序遍历为例子,来思考下遍历的过程。首先在深度遍历优先的思想里,我们从抽象的角度,总是可以把一颗二叉树给切分成三部分,分别是根节点,左子树,右子树。
如下图:

如果是中序遍历,那么这里的遍历规则就是,先左子树,然后根节点,最后是右子树。
按照这个顺序,我们把这三部分数据,放在一个栈里,如下图所示:

然后,遍历的过程就是出栈的过程,但是大家不要忘记一点,如果栈里的结构仍然是一颗子树,我们就仍然需要按照中序遍历的规则,来继续拆分数据入栈,直到这颗子树,被分解成一个个叶子节点。在上图的栈里,我们发现栈顶部分仍然是一颗子树,所以我需要继续拆分,按照先左,再根,最后右来拆分,继续入栈,最后图示如下:
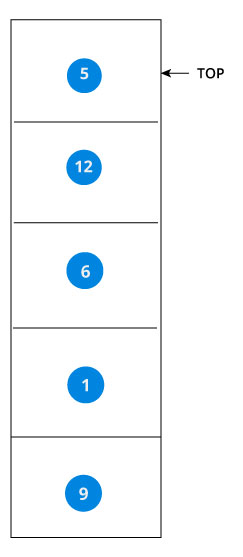
这时候,整棵树都拆分成了叶子节点,我们直接出栈每一个节点,就完成了中序的遍历:
5 -> 12 -> 6 -> 1 -> 9
同理,对于前序遍历和后序遍历也是如此,这里就不再详细介绍了,感兴趣的朋友,可以自己画画图来帮助理解。
下面我们来看看如何在Java中实现,三种深度遍历方式:
递归版本:
前序遍历:
public static void myPreOder(Node<Integer> root) {
if (root == null) {
return;
}
System.out.print(root.data+" ");//根节点
myPreOder(root.left);//全部遍历完左子树
myPreOder(root.right);//全部遍历完右子树
}
中序遍历:
public static void myInOder(Node<Integer> root) {
if (root == null) {
return;
}
myInOder(root.left);//全部遍历完左子树
System.out.print(root.data+" ");//根节点
myInOder(root.right);//全部遍历完右子树
}
后序遍历:
public static void myPostOder(Node<Integer> root) {
if (root == null) {
return;
}
myPostOder(root.left);//全部遍历完左子树
myPostOder(root.right);//全部遍历完右子树
System.out.print(root.data+" ");//根节点
}
输出的结果分别是:
1 12 5 6 9(前序)
5 12 6 1 9(中序)
5 6 12 9 1(后序)
从上面的能够看到,递归的代码非常简洁,但是如果不明白原理只会看的一头雾水。递归能够工作的前提是编程语言为递归的方法,隐式的创建了栈容器,每一次方法的递归调用都相当于作了一次压栈操作(递),而当条件不满足时会进行出栈操作(归)。
为了帮助理解递归的工作方式,我们接着用循环迭代+创建显式的栈容器来实现同样的前,中,后序遍历策略:
迭代版本:
前序遍历:
public static void myIterativePreOder(Node<Integer> root) {
if (root == null) {
return;
}
Stack<Node<Integer>> stack = new Stack();
stack.add(root);
while (!stack.isEmpty()) {
Node<Integer> temp = stack.pop();
System.out.println(temp);
if (temp.right != null) {
stack.push(temp.right);
}
if (temp.left != null) {
stack.push(temp.left);
}
}
}
中序遍历:
public static void myIterativeInOder(Node<Integer> root) {
if (root == null) {
return;
}
Stack<Node<Integer>> stack = new Stack();
Node<Integer> curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
curr = stack.pop();
System.out.println(curr);
curr = curr.right;
}
}
}
后序遍历:
public static void myIterativePostOder(Node<Integer> root) {
if (root == null) {
return;
}
Stack<Node<Integer>> stack = new Stack();
stack.push(root);
LinkedList<Integer> list = new LinkedList<>();
while (!stack.empty()) {
Node<Integer> curr = stack.pop();
list.addFirst(curr.data);
if (curr.left != null) {
stack.push(curr.left);
}
if (curr.right != null) {
stack.push(curr.right);
}
}
System.out.println(list);
}
相比递归版本,迭代版本代码略冗长,但是非常容易理解。另外一个优点在于迭代版本的方式是不容易导致栈溢出的问题,而递归版本则很容易导致栈溢出。参考迭代版本的遍历方式再结合我们前面的分析策略,很容易就能理解二叉树的遍历思路和同样功能的递归算法。
深度遍历是遍历二叉树最常见的策略,本篇文章结合实际例子和图示,通俗易懂的介绍了深度遍历几种策略的思想,理解二叉树的遍历关键点在于,要把定义模型的左右节点,分别看成是两棵树,在遍历过程中,如果发现子节点仍然是棵树,我们就需要优先继续拆分这颗子树,直到找到叶子节点,找叶子节点的过程其实就是在递归的压栈,当找到叶子节点之后,就从开始原路返回,这个过程就是出栈,至于前,中,后序的遍历,无非是遍历的顺序的问题,掌握这一点,就能很容易理解遍历的过程,此外二叉树的遍历还有广度优先遍历算法,也称层级遍历,这个也非常容易理解,就是从顶开始,一层层顺序向底部遍历,相比深度遍历的弯弯绕绕,广度遍历更符合人的思考过程,一点都不烧脑,后面的文章,会单独介绍广度优先遍历的思想和实现,刚兴趣的同学,可以先研究一下。














 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









